1.2 16/09: O processo de boot e instalação de software
1.2.1 O boot
O processo de inicialização do sistema operacional, chamado de boot. Tradicionalmente no Unix System V isto se faz com a definição de níveis de execução (runlevels) e uma tabela que descreve que processos ou serviços devem existir em cada nível. Os níveis de execução são:
Monousuário (single-user), ou administrativo: usado para manutenção do sistema, admite somente o login do superusuário. Não inicia serviços de rede.
Multiusuário com rede (parcial): admite logins de usuários, mas não ativa acesso a recursos de rede (como sistemas de arquivo remotos)
Multiusuário com rede plena
Não usado
Multiusuário com rede plena e ambiente gráfico: ativa também o ambiente gráfico X11
Reinício do sistema (reboot)
As distribuições Linux em geral adotam a inicialização no estilo Unix System V. No entanto, o Ubuntu usa um outro processo chamado de upstart. Esse serviço de inicialização confere maior flexibilidade e mesmo simplicidade à definição de que serviços devem ser executados. O upstart não usa o conceito de níveis de execução, mas devido à sua flexibilidade ele pode emular esse estilo de inicialização. Para o upstart, um serviço deve ser iniciado ou parado dependendo de uma combinação de eventosm, sendo que um evento indica a ocorrência de uma etapa da inicialização.
O upstart é implementado pelo processo init (programa /sbin/init), que é o primeiro processo criado pelo sistema operacional. Quer dizer, logo após terminar a carga e inicialização do kernel, este cria um processo que executa o programa /sbin/init. O upstart lista o subdiretório /etc/init e procura arquivos com extensão .conf. Cada arquivo desses descreve um serviço a ser controlado pelo upstart. Por exemplo, o serviço tty2 é escrito no arquivo tty2.conf:
# tty2 - getty
#
# This service maintains a getty on tty2 from the point the system is
# started until it is shut down again.
start on runlevel [23]
start on runlevel [!23]
respawn
exec /sbin/getty -8 38400 tty2
Abaixo segue o significado de cada linha:
start on runlevel [23]: o serviço deve ser iniciado quando ocorrerem os eventos "runlevel 2" ou "runlevel 3"
stop on runlevel [!23]: o serviço deve ser parado quando ocorrer qualquer evento "runlevel X", sendo X diferente de 2 e 3
respawn: o serviço deve ser reiniciado automaticamente caso termine de forma anormal
exec /sbin/getty -8 38400 tty2: a ativação do serviço implica executar o /sbin/getty -8 38400 tty2
Em linhas gerais, a descrição do serviço informa quando ele deve ser ativado (start), quando deve ser parado (stop), o tipo de execução (respawn para reinício automático, ou task para uma única execução), e que ação deve ser executada para ativar o serviço (exec para executar um programa, ou script .. end script para executar uma sequência de comandos de shell). Maiores detalhes podem ser lidos na página de manual do init.
Um exemplo de criação de serviço no upstart
Foi proposta a criação de um serviço chamado faxineiro, para remover dos diretórios temporários (/tmp e /var/tmp) todos os arquivos que não tenham sido modificados há mais de um dia. Esse novo serviço deve ser executado no boot, logo após o serviço mountall. A solução encontrada foi a seguinte:
Criar o arquivo /etc/init/faxineiro.conf
Adicionar o seguinte conteúdo a esse arquivo:
start on filesystem
task
console output
script
find /tmp -type f -mtime +1 -exec rm -f {} \; -print
find /var/tmp -type f -mtime +1 -exec rm -f {} \; -print
echo Faxineiro executado \!\!\!
end script
Reiniciar o sistema para testá-lo (executar reboot)
1.2.2 Instalação de software
A instalação de software pode ser feita de diversas formas, dentre as quais serão destacadas três:
Com utilitário apt-get: busca o software de um repositório de rede e o instala; dependências (outros softwares necessários) são automaticamente instaladas. Esses softwares buscados da rede estão no formato dpkg (Debian Package). Exemplo de uso do apt-get:
# Instala o navegador de texto lynx
apt-get install lynx
# Testa o navegador lynx
lynx http://www.ifsc.edu.br/
# Remove o lynx
apt-get --auto-remove remove lynx
Diretamente com utilitário dpkg: instala um software que está contido em um arquivo no formato dpkg. Exemplo de uso:
# Obtém os pacotes Debian para o lynx
wget http://www.sj.ifsc.edu.br/~msobral/ger/lynx_2.8.7pre6-1_all.deb
wget http://www.sj.ifsc.edu.br/~msobral/ger/lynx-cur_2.8.7pre6-1_i386.deb
# Instala os pacotes
dpkg -i lynx-cur_2.8.7pre6-1_i386.deb lynx_2.8.7pre6-1_all.deb
# Testa o lynx
lynx
# Remove os pacotes instalados
dpkg -r lynx lynx-cur
A partir do código fonte: busca-se manualmente na rede o código fonte do software desejado, que deve então ser compilado e instalado. Esta opção se aplica quando não existe o software no formato dpkg, ou a versão disponível em formato dpkg foi compilada de uma forma que não atende os requisitos para seu uso em seu servidor.
1.3 18/09: RAID
RAID (Redundant Array of Independent Disks) se destina a combinar discos de forma a incrementar o desempenho de entrada e saída e, principalmente, segurança dos dados contra defeitos em discos. RAID pode ser provido via software ou hardware (melhor este último). O Linux possui implementação por software em seu kernel, e neste HOWTO há uma descrição resumida.
Há vários níveis RAID, que correspondem a diferentes combinações de discos e partições. São eles:
LINEAR: concatena discos ou partições, mas não provê acréscimos de desempenho, nem de segurança dos dados (pelo contrário ! se um disco falhar, perdem-se todos os dados ...).
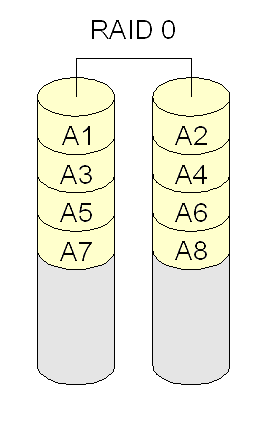
RAID 0 (ou striping): combina discos ou partições de forma alternada, para distribuir os acessos entre eles (aumentar desempenho). Porém, se um disco falhar perdem-se todos os dados. Requer um mínimo de dois discos.
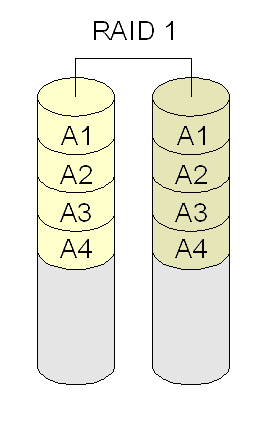
RAID 1 (ou mirroring): combina discos ou partições para espelhar dados (segurança). Requer o dobro de discos necessários para guardar os dados (ex: se há dois discos com dados, são necessários outros dois para espelhamento). Se todos os discos falharem, é possível continuar a operar usando os discos espelhados. Requer no mínimo dois discos.
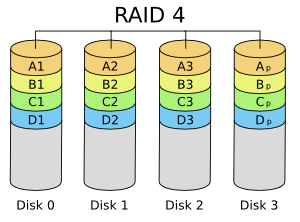
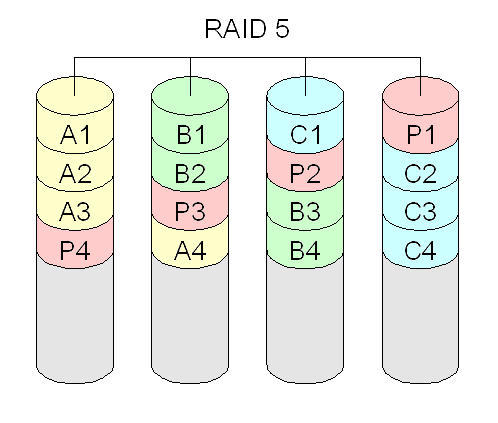
RAID 4 e 5: combina discos ou partições para ter redundância de dados (segurança), usando um esquema baseado em paridade. Se um disco falhar, é capaz de continuar operando (porém com desempenho reduzido até que esse disco seja reposto). RAID 4 na prática não se usa, pois apresenta um gargalo no disco onde residem os blocos de paridades. Requer no mínimo três discos.
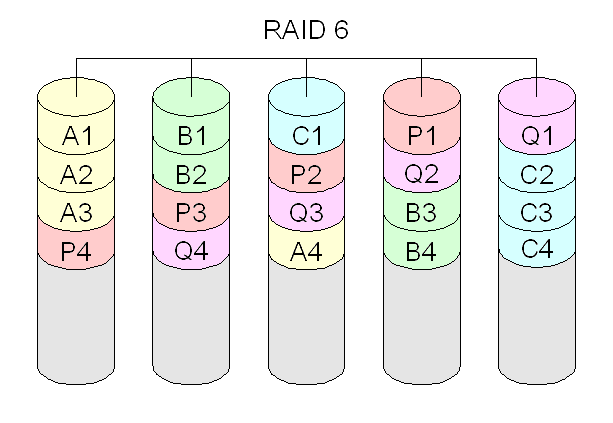
RAID 6: combina discos ou partições para ter redundância de dados (segurança), usando um esquema baseado em paridade de forma duplicada. Isto garante que os dados se preservam mesmo que dois discos se danifiquem. Requer no mínimo quatro discos (pois há dois discos adicionais para paridades).
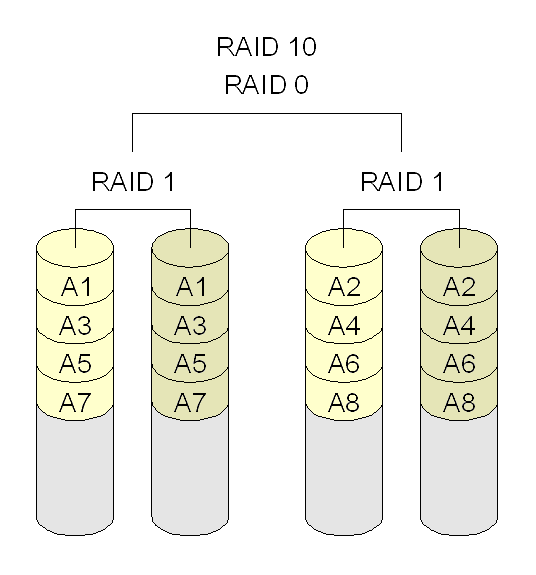
RAID 10: combina RAID 1 e RAID 0, criando um volume com espelhamento (RAID 1), e depois fazendo o striping (RAID 0). Requer no mínimo quatro discos.
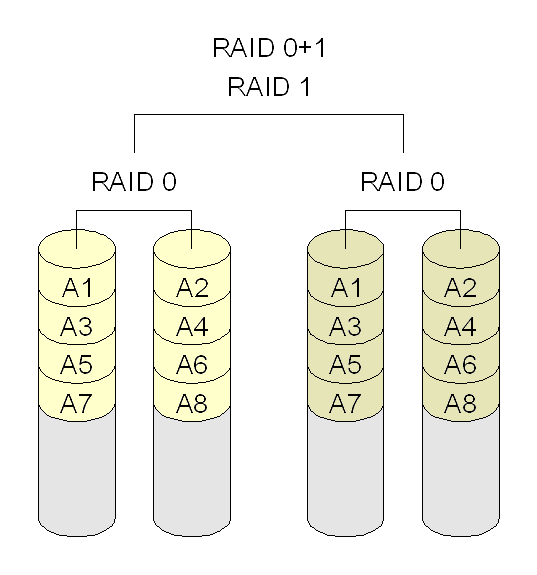
RAID 01: combina RAID 0 e RAID 1, criando um volume com striping (RAID 0), e depois fazendo o espelhamento (RAID 1). Requer no mínimo quatro discos.
NIVEL_RAID pode ser linear, 0, 1, 4, 5, 6, 10, mp, faulty (mais comuns são 0, 1 e 5).
NUM_PARTICOES é a quantidade de partições usadas no volume.
As partições são identificadas com o caminho (pathname) do dispositivo correspondente no Linux. Ex: a primeira partição do primeiro disco SCSI ou SATA é /dev/sda1, a segunda partição desse disco é /dev/sda2, a primeira partição do segundo disco SCSI ou SATA é /dev/sdb1, e assim por diante.
/dev/md0 é o caminho do dispositivo que corresponde ao volume RAID a ser criado. O primeiro volume RAID é /dev/md0, o segundo é /dev/md1, e assim por diante.
Formatar o volume RAID: mkfs.ext4 -j /dev/md0
Uma vez testado o volume RAID, sua configuração pode ser salva para posterior uso: mdadm --detail --scan >> /etc/mdadm/mdadm.conf
Isto é importante para que o volume possa ser ativado automaticamente no próximo boot.
Para ativar um volume já criado, basta executar mdadm --assemble caminho_do_volume. Ex: mdadm --assemble /dev/md0, mdadm --assemble /dev/md1.
Atividade:
Crie duas partições de mesmo tamanho no disco /dev/sdb. Marque-as como sendo do tipo Linux RAID (fdisk t = "fd")
Crie um volume RAID nível 1 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
Desmonte e Pare o volume existente, com mdadm -S /dev/md0
Crie um volume RAID nível 0 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
Desmonte e Pare o volume existente, com mdadm -S /dev/md0
Crie um volume RAID nível 5 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
Desmonte e Pare o volume existente, com mdadm -S /dev/md0
1.4 23/09: LVM
Armazenamento com Gerenciador de Volumes Lógicos (LVM). Ver páginas 57 e 58 da apostila.
Há um HOWTO com informação adicional sobre LVM no Linux, e outro com uma definição mais geral na Wikipedia.
LVM combina volumes físicos (ou PV, de Physical Volume), tais como discos, partições e volumes RAID, em uma abstração chamada grupo de volumes (ou VG, de Volume Group). Um VG funciona como um grande disco virtual, que pode ser dividido em volumes lógicos (LV, de Logical Volume). Cada LV pode ser usado para conter um sistema de arquivos, memória virtual (área de swap), ou qualquer outra finalidade de armazenamento (ex: área de dados de um banco de dados Oracle). A figura abaixo mostra
a relação entre esses componentes, com exemplos de utilização dos LV:
PE: Physical Extent, ou uma subdivisão do PV (são todas de mesmo tamanho), que funciona como unidade de alocação de espaço
LE: Logical Extent, o equivalente ao PE, porém no contexto do LV
PV: Physical Volume, ou uma partição física
LV: Logical Volume, ou uma partição lógica criada dentro do VG
Em sua estrutura interna, o LVM divide cada PV em pequenas partições chamadas de PE (Physical Extent). Um tamanho típico para as PE é de 4 MB. Essas PE são usadas para alocar espaço para os LV, porém não há nenhuma relação entre a ordem física das PE nos PV e a ordem em que elas são alocadas aos LV - é normal inclusive PE de diferentes PV serem alocadas ao mesmo LV. Dentro de cada LV cada PE é chamada de LE (Logical Extent). A figura abaixo relaciona as PE com as LE dos LV:
Diagrama para LVM versão 1 (LVM1) no Linux.
1.4.1 Criação do LVM no Linux
A sequência de criação de um VG e seus LV é a seguinte:
Criar partições físicas do tipo 8E (Linux LVM), que serão usadas para serem os PV
Preparar essas partições para serem usadas como PV, usando o comando lvm pvcreate caminho_partição (ex: lvm pvcreate /dev/sdb1)
Criar o VG, usando o comando lvm vgcreate nome_vg pv1 [pv2 ...] (ex: lvm vgcreate meu_vg /dev/sdb1 /dev/sdb2)
Criar os LV, com o comando lvm lvcreate nome_vg -L tamanho_LV -n nome_LV (ex: lvm lvcreate meu_vg -L 512M -n teste)
Formatar os LV (ex: mke4fs -j /dev/meu_vg/teste, para formatar com sistema de arquivos ext4)
Abaixo segue um exemplo de uma sequência de comandos relacionados com LVM, desde o particionamento de um disco até o redimensionamento de um LV existente:
# Prepara as partições (devem ser do tipo 8E (Linux LVM)
fdisk/dev/sdb
# Prepara essas duas partições para serem usadas como volumes físicos
lvmpvcreate/dev/sdb1
lvmpvcreate/dev/sdb2
# Cria o volume group "vg"
lvmvgcreatevg/dev/sdb1/dev/sdb2
# Cria dentro do volume group "vg" um volume lógico "dados" com 512 MB iniciais
lvmlvcreatevg-L512M-ndados
# Cria dentro do volume group "vg" um volume lógico "teste" com 256 MB iniciais
lvmlvcreatevg-L256M-nteste
# Mostra informações sobre todos os volumes lógicos
lvmlvs
# Mostra detalhes sobre o volume lógico "dados", que pertence ao volume group "vg"
lvmlvdisplay/dev/vg/dados
# Formata o volume lógico "dados" com sistema de arquivos do tipo "ext4"
mkfs.ext4-j/dev/vg/dados
# Formata o volume lógico "teste" com sistema de arquivos do tipo "xfs"
mkfs.xfs/dev/vg/teste
# Aumenta em 512 MB o tamanho do volume lógico "dados"
lvmlvresize-L+512M/dev/vg/dados
# Aumenta o sistema de arquivos contido no volume lógico "dados", para adaptá-lo ao seu novo tamanho
resize2fs/dev/vg/dados
Questões importantes:
O que é LVM, e qual sua relação com os discos físicos ?
Para que usar LVM (o que se ganha com seu uso) ?
Existe algum problema que possa ocorrer com o uso do LVM ? Por exemplo, se um disco apresentar defeito ?
1.5 23/09: LVM - Atividade
Com o fdisk crie três novas partições, no início do espaço livre do disco, uma de tamanho de 512 MB, outra de 1GB e a terceira com 1.4 GB. Formate-as com sistema de arquivos ext4.
Monte estas partições em /dados, /soft e /outra.
Configure o sistema para que faça a montagem automaticamente, ou seja, em todo reinício da máquina.
Desfaça os itens 2 e 3, para dar prosseguimento ao exercício.
Crie um grupo de volume LVM (VG) com nome GerVg, contendo as duas partições criadas no item 1. Esse VG deverá ter tamanho total de 1512 MB.
Crie 4 volumes lógicos, "dados", "home", "teste", "softwares", respectivamente com 300 , 400, 100 e 500 MB, dentro do VG.
Formate os volumes lógicos.
Monte as novas partições em /dados, /usuarios, /nada e /soft, respectivamente.
Aumente o tamanho de "home" em 500 MB, redimensionando o sistema de arquivos apropriadamente (e sem desmontá-lo).
Com o fdisk remova completamente as partições criadas, para não deixar o hd “bagunçado”. Remova também todos os diretórios criados.
1.6 30/09: Atividade RAID + LVM
1.6.1 RAID + LVM
LVM não proporciona proteção dos dados ... pelo contrário. Por combinar volumes físicos para serem usados em volumes lógicos, e pela forma como faz a alocação de espaço (em que os LE dos volumes lógicos podem apresentar um mapeamento arbitrário e fora de sequência aos PE dos volumes físicos), na verdade o LVM amplia a chance de dores de cabeça no evento de um defeito em um disco. Por isto é fundamental que a segurança dos dados seja provida por outra técnica, sendo o mais recomendado RAID.
RAID combina discos ou partições de forma a incrementar o desempenho e/ou segurança dos dados, conforme visto anteriormente. Um volume RAID (ou array RAID), composto de múltiplos discos, se apresenta como se fosse um único disco. Para usá-lo de forma a prover segurança de dados para o LVM, o volume RAID deve ser usado como volume físico do LVM. Além disto, dado o objetivo do uso do RAID, devem-se usar os níveis RAID 1, RAID 5, RAID 6 ou RAID 10 (melhor os dois primeiros). Fazendo isto, os volumes LVM estarão menos vulneráveis a falhas de hardware.
Atividade:
Usando dois discos físicos com 4 GB cada, combine RAID e LVM para criar um Volume Group que aproveite todo o espaço disponível e esteja protegido contra defeitos em um dos discos.
Crie dois sistemas de arquivos do tipo EXT4 dentro desse Volume Group:
Um com 1GB, a ser montado em /dados
Outro com 2 GB, a ser montado em /usuarios
Simule um defeito em um dos discos e verifique se esses sistemas de arquivos continuam disponíveis:
Se o Linux estiver rodando em um computador real, remova a alimentação de um dos discos
Se estiver rodando com VirtualBox, desligue a máquina virtual, remova um dos discos virtuais, e então a reinicie
1.7 02/10: Usuários e grupos
Criação de contas de usuários e de grupos, e seu uso para conferir permissões de acesso a arquivos, diretórios e recursos do sistema operacional.
Apostila, páginas 61 a 65.
Um usuário no Linux (e no Unix em geral) é definido pelo seguinte conjunto de informações:
Nome de usuário (ou login): um apelido que identifica o usuário no sistema
UID (User Identifier): um número único que identifica o usuário
GID (Group Identifier): o número do grupo primário do usuário
Senha (password): senha para verificação de acesso
Nome completo (full name): nome completo do usuário
Diretório inicial (homedir): o subddiretório pessoal do usuário, onde ele é colocado ao entrar no sistema
Shell: o programa a ser executado quando o usuário entrar no sistema
As contas de usuários, que contêm as informações acima, podem ficar armazenadas em diferentes bases de dados (chamadas de bases de dados de usuários). Dentre elas, a mais simples é composta pelo arquivo /etc/passwd:
Cada linha desse arquivo define uma conta de usuário no seguinte formato:
nome de usuário:senha:UID:GID:Nome completo:Diretório inicial:Shell
O campo senha em /etc/passwd pode assumir os valores:
x: significa que a senha se encontra em /etc/shadow
*: significa que a conta está bloqueada
senha encriptada: a senha de fato, porém encriptada usando algoritmo hash MD5 ou crypt. Porém usualmente a senha fica armazenada no arquivo /etc/shadow.
O arquivo /etc/shadow armazena exclusivamente as informações relativas a senha e validade da conta. Nele cada conta possui as seguintes informações:
Nome de usuário
Senha encriptada (sobrepõe a senha que porventura exista em /etc/passwd)
Data da última modificação da senha
Dias até que a senha possa ser modificada (validade mínima da senha)
Dias após que a senha deve ser modificada
Dias antes da expiração da senha em que o usuário deve ser alertado
Dias após a expiração da senha em que a conta é desabilitada
Os membros de um grupo são os usuários que o têm como grupo primário (especificado na conta do usuário em /etc/passwd), ou que aparecem listados em /etc/group.
1.7.1 Gerenciamento de usuários e grupos
Para gerenciar usuários e grupos podem-se editar diretamente os arquivos /etc/passwd, /etc/shadow e /etc/group, porém existem utilitários que facilitam essa tarefa:
useradd: adiciona um usuário
Ex: useradd -c "Roberto de Matos" -m roberto : cria o usuário roberto com nome completo "Roberto de Matos"
Ex: useradd -c "Roberto de Matos" -g users -u 5000 -d /usuarios/roberto -s /bin/tcsh -m roberto : cria o usuário roberto com nome completo "Roberto de Matos", UID 5000, grupo users, diretório inicial /usuarios/roberto e shell /bin/tcsh
userdel: remove um usuário
Ex: userdel roberto : remove o usuário roberto, porém preservando seu diretório home
Ex: userdel -r roberto : remove o usuário roberto, incluindo seu diretório home
usermod: modifica as informações da conta de um usuário
Ex: usermod -u 5001 roberto : modifica o UID do usuário roberto
Ex: usermod -g wheel roberto : modifica o GID do usuário roberto
Ex: usermod -G users,wheel roberto : modifica os grupos secundários do usuário roberto
Ex: usermod -d /contas/roberto roberto : modifica o diretório inicial do usuário roberto (mas não copia os arquivos ...)
groupadd: adiciona um grupo
Ex: groupadd -g 4444 ger: cria o grupo ger com GID 4444
groupdel: remove um grupo
Ex: groupdel ger: remove o grupo ger
groupmod: modifica um grupo
Ex: groupmod -g 5555 ger: modifica o GID do grupo ger
Ex: groupmod -A roberto ger: adiciona o usuário roberto ao grupo ger
Ex: groupmod -R roberto ger: remove o usuário roberto do grupo ger
Esses utilitários usam os arquivos /etc/login.defs e /etc/default/useradd para obter seus parâmetros default. O arquivo /etc/login.defs contém uma série de diretivas e padrões que serão utilizados na criação das próximas contas de usuários. Seu principal conteúdo é:
MAIL_DIR dir # Diretório de e-mail
PASS_MAX_DAYS 99999 #Número de dias até que a senha expire
PASS_MIN_DAYS 0 #Número mínimo de dias entre duas trocas senha
PASS_MIN_LEN 5 #Número mínimo de caracteres para composição da senha
PASS_WARN_AGE 7 #Número de dias para notificação da expiração da senha
UID_MIN 500 #Número mínimo para UID
UID_MAX 60000 #Número máximo para UID
GID_MIN 500 #Número mínimo para GID
GID_MAX 60000 #Número máximo para GID
CREATE_HOME yes #Criar ou não o diretório home
Como o login.defs o arquivo /etc/default/useradd contém padrões para criação de contas. Seu principal conteúdo é:
GROUP=100 #GID primário para os usuários criados
HOME=/home #Diretório a partir do qual serão criados os “homes”
INACTIVE=-1 #Quantos dias após a expiração da senha a conta é desativada
EXPIRE=AAAA/MM/DD #Dia da expiração da conta
SHEL=/bin/bash #Shell atribuído ao usuário.
SKEL=/etc/skel #Arquivos e diretórios padrão para os novos usuários.
GROUPS=video,dialout
CREATE_MAIL_SPOOL=no
1.7.2 Permissões
Há uma maneira de restringir o acesso aos arquivos e diretórios para que somente determinados usuários possam acessá-los. A cada arquivo e diretório é associado um conjunto de permissões. Essas permissões determinam quais usuários podem ler, e escrever (alterar) um arquivo e, no caso de ser um arquivo executável, quais usuários podem executá-lo. Se um usuário tem permissão de execução para um diretório, significa que ele pode realizar buscas dentro daquele diretório, e não executá-lo como se fosse um programa.
Quando um usuário cria um arquivo ou um diretório, o LINUX determina que ele é o proprietário (owner) daquele arquivo ou diretório. O esquema de permissões do LINUX permite que o proprietário determine quem tem acesso e em que modalidade eles poderão acessar os arquivos e diretórios que ele criou. O super-usuário (root), entretanto, tem acesso a qualquer arquivo ou diretório do sistema de arquivos.
O conjunto de permissões é dividido em três classes: proprietário, grupo e usuários. Um grupo pode conter pessoas do mesmo departamento ou quem está trabalhando junto em um projeto. Os usuários que pertencem ao mesmo grupo recebem o mesmo número do grupo (também chamado de Group Id ou GID). Este número é armazenado no arquivo /etc/passwd junto com outras informações de identificação sobre cada usuário. O arquivo /etc/group contém informações de controle sobre todos os grupos do sistema. Assim, pode -se dar permissões de acesso diferentes para cada uma destas três classes.
Quando se executa ls -l em um diretório qualquer, os arquivos são exibidos de maneira semelhante a seguinte:
Mês da criação do arquivo; Dia da criação do arquivo;
Hora da criação do arquivo;
Nome do arquivo;
O esquema de permissões está dividido em 10 colunas, que indicam se o arquivo é um diretório ou não (coluna 1), e o modo de acesso permitido para o proprietário (colunas 2, 3 e 4), para o grupo (colunas 5, 6 e 7) e para os demais usuários (colunas 8, 9 e 10).
Existem três modos distintos de permissão de acesso: leitura (read), escrita (write) e execução (execute). A cada classe de usuários você pode atribuir um conjunto diferente de permissões de acesso. Por exemplo, atribuir permissão de acesso irrestrito (de leitura, escrita e execução) para você mesmo, apenas de leitura para seus colegas, que estão no mesmo grupo que você, e nenhum acesso aos demais usuários. A permissão de execução somente se aplica a arquivos que podem ser executados, obviamente, como programas já compilados ou script shell. Os valores válidos para cada uma das colunas são os seguintes:
1 d se o arquivo for um diretório;-se for um arquivo comum;
2,5,8 r se existe permissão de leitura;-caso contrário;
3,6,9 w se existe permissão de alteração;-caso contrário;
4,7,10 x se existe permissão de execução;-caso contrário;
A permissão de acesso a um diretório tem outras considerações. As permissões de um diretório podem afetar a disposição final das permissões de um arquivo. Por exemplo, se o diretório dá permissão de gravação a todos os usuários, os arquivos dentro do diretório podem ser removidos, mesmo que esses arquivos não tenham permissão de leitura, gravação ou execução para o usuário. Quando a permissão de execução é definida para um diretório, ela permite que se pesquise ou liste o conteúdo do diretório.
A modificação das permissões de acesso a arquivos e diretórios pode ser feita usando-se os utilitários:
chmod: muda as permissões de acesso (também chamado de modo de acesso). Somente pode ser executado pelo dono do arquivo ou pelo superusuário
Ex: chmod +x /home/usuario/programa : adiciona para todos os usuários a permissão de execução ao arquivo /home/usuario/programa
Ex: chmod -w /home/usuario/programa : remove para todos os usuários a permissão de escrita do arquivo /home/usuario/programa
Ex: chmod o-rwx /home/usuario/programa : remove todas as permissões de acesso ao arquivo /home/usuario/programa para todos os usuários que não o proprietário e membros do grupo proprietário
Ex: chmod 755 /home/usuario/programa : define as permissões rwxr-xr-x para o arquivo /home/usuario/programa
chown: muda o proprietário de um arquivo. Somente pode ser executado pelo superusuário.
Ex: chown roberto /home/usuario/programa: faz com que o usuário roberto seja o dono do arquivo
chgrp: muda o grupo dono de um arquivo. Somente pode ser executado pelo superusuário.
Ex: chgrp users /home/usuario/programa: faz com que o grupo users seja o grupo dono do arquivo /home/usuario/programa
Há também o utilitário umask, que define as permissões default para os novos arquivos e diretórios que um usuário criar. Esse utilitário define uma máscara (em octal) usada para indicar que permissões devem ser removidas. Exemplos:
umask 022: tira a permissão de escrita para group e demais usuários
umask 027: tira a permissão de escrita para group, e todas as permissões para demais usuários
1.7.3 Atividade
Crie o grupo turma.
Crie o diretório /home/contas.
Faça cópia dos arquivos a serem alterados: /etc/login.defs e /etc/default/useradd.
Faça com que o diretório home dos usuários, a serem criados a partir de agora, seja por padrão dentro de /home/contas.
Faça com que os usuários sejam criados com o seguinte perfil, por padrão:
Expiração de senha em 15 dias a partir da criação da conta;
Usuário possa alterar senha a qualquer momento;
Data do bloqueio da conta em 7 dias após a expiração da senha.
Inicie os avisos de expiração da senha 4 dia antes de expirar.
Iniciar a numeração de usuários (ID) a partir de 1000.
Crie um usuário com o nome de manoel, pertencente ao grupo turma.
Dê ao usuário manoel a senha mane123.
Acrescente ao perfil do usuário seu nome completo e endereço: Manoel da Silva, R. dos Pinheiros, 2476666.
Verifique o arquivo /etc/passwd.
Mude, por comandos, o diretório home do manoel de /home/contas/manoel para /home/manoel.
Mude o login do manoel para manoelsilva.
Logue como manoelsilva.
Recomponha os arquivos originais do item 3.
Permissionamento de arquivos e grupos de usuários
Crie a partir do /home 3 diretórios, um com nome aln (aluno), outro prf (professor) e o último svd (servidor).
Crie 3 grupos com os mesmos nomes acima.
Crie 3 contas pertencentes ao grupo aln: aluno1, aluno2, aluno3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/aln/. Por exemplo para o aluno1 teremos /home/aln/aluno1.
Crie 3 contas pertencentes ao grupo prf: prof1, prof2, prof3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/prf/.
Crie 3 contas pertencentes ao grupo svd: serv1, serv2, serv3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/svd/.
Os diretórios dos alunos, e todo o seu conteúdo, devem ser visíveis, mas não apagáveis, aos membros do próprio grupo e de todos os demais usuários da rede.
Já os diretórios dos professores e servidores, devem ser mutuamente visíveis, mas não apagáveis, entre os membros dos grupos professores e servidores mas não deve ser sequer visível aos membros do grupo alunos.
1.8 07/10: Quotas de disco
Quotas de disco servem para limitar o uso de espaço pelos usuários. Ver também apostila de Gerência de Redes, páginas 68 a 70.
Em servidores não se pode correr o risco de poucos usuários utilizarem tanto espaço de disco que impeça outros usuários de trabalharem. Quer dizer, deve-se implantar algum mecanismo que limite o espaço a ser usado por cada usuário, para evitar que o espaço livre no volume se esgote. Quotas de disco é um mecanismo simples para impor tal limitação, estando disponível em todos os sistemas operacionais usados em servidores.
Os sistemas operacionais Linux oferecem um mecanismo simples para impor quotas. Para cada sistema de arquivos é possível ativar ou não o uso de quotas, e fazer um controle de quota por usuário ou grupo. Os sistemas de arquivos de uso mais difundido, tais como EXT3FS, EXT4FS, XFS, ReiserFS e JFS, suportam o uso de quotas (o que não é o caso de VFAT, usado majoritariamente em pendrives atualmente, por exemplo). O sistema operacional controla diretamente o uso do espaço, evitando que o limite estabelecido seja ultrapassado. Desta forma, se um arquivo estiver sendo gravado e o limite de espaço for atingido, a operação de escrita é abortada com um erro de quota excedida (como resultado, o arquivo ficaria truncado). Mas como essa forma de impor um limite pode ser muito estrita, o sistema de quotas define na verdade dois limites:
soft limit: pode ser ultrapassado, no entanto gera um alerta para o usuário. No entanto, se o espaço total usado pelo usuário ficar acima desse limite continuamente por um número predefinido de dias, esse limite se torna estrito (quer dizer, se torna um hard limit).
hard limit: não pode ser ultrapassado, gerando um erro de escrita.
Abaixo pode-se ver um exemplo do uso de disco pelo usuário roberto, em um sistema de arquivos com quotas ativadas. Nesse caso, roberto está usando em torno de 30 MB dentro do sistema de arquivos contido no dispositivo /dev/sdb2, e que está montado em /usuarios. O uso total atual está na coluna blocos (1 kB cada), soft limit aparece na coluna quota e o hard limit está em limite:
Além disto, note-se que há outras colunas reportadas acima, tais como grace e arquivos. A coluna grace informa quantos dias o usuário ainda tem de prazo, caso esteja acima do soft limit, antes que ele se torne um hard limit (normalmente iniciando com 7 dias). Além disso, é possível limitar também a quantidade de arquivos por ele mantidos. A coluna arquivos informa quantos arquivos e diretórios um usuário possui, e as colunas que a sucedem informam seus limites.
A decisão de que limites devem ser impostos aos usuários é de grande importância, pois devem-se conciliar as necessidades desses usuários e a quantidade de espaço em disco disponível para eles. Uma política para uso de espaço seria dividir a capacidade total do volume pela quantidade de usuários. Porém sabe-se que usuários têm diferentes práticas de uso dos recursos de rede, incluindo as áreas de armazenamento de arquivos. Muitos usuários fazem pouco uso do espaço disponível, enquanto outros realmente aproveitam tudo que lhes for alocado. Assim, uma outra política seria definir um limite individual maior, mesmo que a soma dos limites de usuários exceda a capacidade total do volume. Não é incomum que a soma das quotas individuais seja o dobro ou mais do espaço total existente. Cabe ao administrador o bom senso e, principalmente, o conhecimento sobre o padrão de uso de seus usuários, para melhor definir as quotas e assim o aproveitamento dos discos dos servidores.
Por fim, quotas não implicam nenhuma reserva de espaço em disco para os usuários.
1.8.1 Implantação de quotas
Vários passos são necessários para implantar quotas em um sistema de arquivos. Em primeiro lugar, deve-se certificar de que os utilitários necessários para sua configuração estejam instalados:
apt-getinstallquota
# mostra a man page do utilitário quota
manquota
Cada sistema de arquivos onde se desejam ativar quotas deve ser montado com a opção quota. Assim, a linha do arquivo /etc/fstab correspondente a um sistema de arquivos desses deve ser similar a:
/dev/sdb2 /usuarios ext4 defaults,quota 0 1
Ao montar o sistema de arquivos pela primeira vez, devem-se tanto atualizar manualmente as informações permanentes sobre quotas (mantidas em um arquivo aquota.user, que fica na raiz do sistema de arquivos), quanto ativar manualmente as quotas:
# Monta o sistema de arquivos /usuarios (só funciona assim por que ele está descrito em /etc/fstab)
mount/usuarios
# Atualiza as informações sobre quotas: isto varre todo o sistema de arquivos para contabilizar quanto espaço cada usuário possui, e grava# o resultado no arquivo aquota.user
quotacheck-f/usuarios
# Ativa as quotas no sistema de arquivos
quotaon-v/usuarios
# Gera uma listagem das quotas dos usuarios
repquota-v/usuarios
Uma vez estando o sistema de arquivos definido com a opção quota, as quotas serão ativadas automaticamente no boot do sistema. O procedimento acima é necessário somente na implantação das quotas.
Uma vez estando as quotas ativadas, podem-se editar as quotas de usuaŕios com o utilitário edquota.
edquotaroberto
Esse utilitário executa um editor de texto comum para editar as quotas, e então grava o resultado no arquivo aquota.user. O editor de texto executado é aquele indicado na variável de ambiente EDITOR (ex: nano, vim, ...). Abaixo pode-se ver o editor vi sendo chamado para editar as quotas:
Uma prática comum para automatizar a edição de quotas (e fazê-la de forma não-interativa) é definir alguns usuários que servem como perfis (ex: aluno, professor, funcionario), e definir as quotas para cada um deles. Assim , cada novo usuário que for criado pode ter suas quotas copiadas a partir de um desses perfis, usando-se edquota -p:
# copia as quotas do usuário professor para roberto
edquota-pprofessorroberto
Outra forma de definir quotas de forma não-interativa (bom para shell scripts ou outros programas que automatizem o gerenciamento de usuários) é com o utilitário setquota. Com esse programa devem-se informar diretamente na linha de comando os limites tanto de espaço em disco quanto de arquivos:
# Define quotas para o usuário roberto:# espaço em disco: soft limit = 100 MB, hard limit = 150 MB# quantidade de arquivos: ilimitado
setquota-uroberto10000015000000/usuarios
Finalmente, os usuários que excederam seus soft limit podem ser alertado por email pelo utilitário warnquota. Esse programa pode ser executado periodicamente pelo agendador de tarefas (ex: diariamente).
Configure o Linux para permitir o uso de quotas de usuários no “/home”.
Estabeleça para os usuários do tipo alunos a seguinte quota: blocos (soft = 500 e hard = 1000).
Estabeleça para os usuários do tipo professores e servidores a seguinte quota: blocos (soft = 600 e hard = 800).
Logue como estes usuários e crie ou copie vários arquivos dentro de seus homes e verifique as mensagens de estouro de quotas de usuários.
Crie um usuário chamado operador, e defina que sua quota é ilimitada. Crie arquivos para esse usuário, e verifique se há alguma restrição do sistema de quotas.
Em um servidor se deseja limitar que alunos no total não excedam 100 MB, e professores e servidores estejam limitados a 200 MB. Quer dizer, todos os alunos juntos não podem execeder esse limite, assim como profesores e funcionários. Pesquise como implementar isto com o sistema de quotas do Linux (dica: veja quotas para grupos).
1.9 09/10: Agendamento de tarefas
Agendamento de tarefas administrativas com crontab. Apostila de Gerência de Redes, capítulo 19.
O cron é um programa de agendamento de tarefas. Com ele pode-se fazer a programação para execução de qualquer programa numa certa periodicidade ou até mesmo em um exato dia, numa exata hora. Um uso comum do cron é o agendamento de tarefas administrativas de manutenção do seu sistema, como por exemplo, análise de segurança w backup. Estas tarefas são programadas para, todo dia, toda semana ou todo mês, serem automaticamente executadas através da crontab e um script shell comum. A configuração do cron geralmente é chamada de crontab.
Os sistemas Linux possuem o cron na instalação padrão. A configuração tem duas partes: uma global, e uma por usuário. Na global, controlada pelo root, o crontab pode ser configurado para executar qualquer tarefa de qualquer lugar, como qualquer usuário. Já na parte por usuário, cada usuário tem seu próprio crontab, sendo restringido apenas ao que o usuário pode fazer (e não tudo, como é o caso do root).
1.9.1 Uso do crontab
Para configurar um crontab por usuário, utiliza-se o comando crontab, junto com um parâmetro, dependendo do que se deseja fazer. Abaixo uma relação:
crontab -e: Edita a crontab atual do usuário logado
crontab -l: Exibe o atual conteúdo da crontab do usuário
crontab -r: Remove a crontab do usuário
Se você quiser verificar os arquivos crontab dos usuários, você precisará ser root. O comando crontab coloca os arquivos dos usuários no diretório /var/spool/cron/crontabs . Por exemplo, a crontab do usuário aluno estará no arquivo /var/spool/cron/crontabs/aluno.
Existe também uma crontab global, que fica no arquivo /etc/crontab, e só pode ser modificado pelo root.
Vamos estudar o formato da linha do crontab, que é quem vai dizer o que executar e quando. Vamos ver um exemplo:
A linha é dividida em campos separados por tabs ou espaço:
Campo
Função
1o
Minuto
2o
Hora
3o
Dia do mês
4o
Mês
5o
Dia da semana
6o
Programa a ser executrado
Todos estes campos, sem contar com o 6o., são especificados por números. Veja a tabela abaixo para os valores destes campos:
Campo
Função
Minuto
0-59
Hora
0-23
Dia do mês
1-31
Mês
1-12
Dia da semana
0-6 (0=domingo, 6=sábado)
Então o que nosso primeiro exemplo estava dizendo? A linha está dizendo: "Execute o comando /root/scripts/backup.sh às 12:30 h e às 22:30h, todos os dias".
Vamos analisar mais alguns exemplos:
1,21,41 * * * * echo "Meu crontab rodou mesmo!"
Aqui está dizendo: "Executar o comando do sexto campo toda hora, todo dia, nos minutos 1, 21 e 41".
30 4 * * 1 rm -rf /tmp/*
Aqui está dizendo: "Apagar todo conteúdo do diretório /tmp toda segunda-feira, as 4:30 da manhã."
45 19 1,15 * * /usr/local/bin/backup
Aqui está dizendo: "Executar o comando 'backup' todo dia 1 e 15 às 19:45.".
E assim pode-se ir montando inúmeros jeitos de agendamento possível. No arquivo do crontab global, o sexto campo pode ser substituído pelo nome do usuário, e um sétimo campo adicionado com o programa para a execução, como mostrado no exemplo a seguir:
*/5 * * * * root /usr/bin/mrtg /etc/mrtg/mrtg.cfg
Aqui está dizendo: "Executar o mrtg como usuário root, de 5 em 5 minutos sempre."
0 19-23/2 * * * /root/script
Aqui está dizendo: “Executar o 'script' entre as 19 e 23 de 2 em duas horas.”
1.9.2 Atividade
Agende o comando date para escrever/adicionar sua saída ao arquivo /root/date a cada minuto.
Pressuponha que o script /root/abacaxi.sh exista, agende o mesmo para ser executado:
De dois em dois dias às 11 h e 55 min.
Todo dia 5 às 3 h e 50 min.
No dia 14 de cada mês entre as 8 e 18 h, de hora em hora.
1.10 14/10: Avaliação Docente – Exercício Quotas
Avaliação Docente
Finalizar o Exercício de Quotas
Aula extra marcada para o dia 21/10 das 15:40h às 17:30h.
1.11 16/10: Shell Scripts para automatizar tarefas
Repare nas chaves em volta do nome da variável. Isto é particularmente necessário quando se deseja delimitar o nome da variável, como no exemplo abaixo:
#!/bin/bashbasedir=/home/aluno
# a sentença abaixo funciona como esperadoechoaluno1temdiretóriohome${basedir}1# ... mas esta a seguir não !echoaluno1temdiretóriohome$basedir1
Tratando variáveis que podem estar indefinidas ou vazias:
#!/bin/bashx=ok
echoVariavelx=${x}# Mostra o valor "vazia", porque y é uma variável indefinida, mas não altera yechoVariavely=${y:-vazia}echoVariavely=${y}# Mostra o valor "vazia", porque y é uma variável indefinida, e faz com que y="vazia"echoVariavely=${y:=vazia}echoVariavely=${y}
#!/bin/bashx=1y=3# Abaixo apenas concatena os valores de x e yechox+y=${x}+${y}# Abaixo faz a soma de x e yechox+y=$((${x}+${y}))
Estruturas condicionais:
Teste de condição: se condição então ... senão ... fimSe
#!/bin/bash# Este programa também diz aloif["$LOGNAME"="root"];thenecho"Alo SENHOR, tenha um bom dia ... e às suas ordens !"elseecho"Alo $LOGNAME, tenha um bom dia."fi
Condições a serem usadas no if ... then ... else se baseiam no programa test. Alguns exemplos:
x=0y=1# operador -eq: igualdade numericaif[$x-eq0];thenechoVariavelxzerada
fi# operador -o: OU logicoif[$x-eq1-o$y-eq1];thenechoUmadasvariáveisxouytemvalordiferentedezerofi# operador -a: E logicoif[$x-eq1-a$y-eq1];thenechoAmbasvariáveisxouytemvalordiferentedezerofi# operador -le: <= (less or equal)if[$x-le10];thenechoVariávelxmenorouiguala10fi# operador -lt: < (less than)if[$x-lt10];thenechoVariávelxmenorque10fi# operador -ge: >= (greater or equal)if[$x-ge10];thenechoVariávelxmaiorouiguala10fi# operador -gt: > (greater than)if[$x-gt10];thenechoVariávelxmaiorque10fi# operador !: NEGACAOif[!$x-gt10];thenechoVariávelxmenorouiguala10fi
Variações do uso do teste condicional:
ifcomando
thencomandosexecutadosse"comando"retornarstatus"ok"(0)elsecomandosexecutadosse"comando"retornarstatus"não ok"(diferentede0)fiifcomando1
thencomandosexecutadosse"comando1"retornarstatus"ok"(0)elifcomando2
comandosexecutadosse"comando2"retornarstatus"ok"(0)elsecomandosexecutadossenãoentrarnos"if"acima
fi
comando1&&comando2
# construção na linha acima eh equivalente a (porta E):ifcomando1
thencomando2
fi
comando1||comando2
# construção na linha acima eh equivalente a (porta OU):ifcomando1
then:
elsecomando2
fi
#!/bin/bash# enquanto x <= 5while[${x}-le5];doecho$xx=$(($x+1))done# Mostra os processos do usuario aluno, enquanto ele estiver logadowhile(who|grepaluno>/dev/null);dodate
psaux|grepaluno
echo""sleep5done
1.12.2 Atividade
Faça um script que mostre os 5 diretórios que estão ocupando mais espaço no diretório /var/
Modifique o script acima para que a quantidade de diretório mostrada seja parametrizada.
Faça um script mostrando o nome completo do usuário, a partir do argumento "login".
Faça um script mostrando os grupos que o usuário está incluído. Esse script deve consultar os arquivos /etc/group.
Faça um script que utilize um usuário padrão chamado "modelo" para estabelecer cotas a todos os usuários do sistema.
Em um diretório existem diversos arquivos compactados com zip, como se pode ver abaixo:
$ls
arq1.zip
banana.zip
laranja.zip
$
Faça um script que descompacte cada arquivo desses em um subdiretório que tenha o nome do arquivo em questão, porém excluída sua extensão (ex: para banana.zip, deve-se descompactá-lo dentro de "banana"). Dica: use o esqueleto de script mostrado abaixo:
#!/bin/bashforarqin*.zip;doecho$arqdone
1.13 23/10: Prova
Prezado Gerente de Redes,
A empresa está expandindo sua atuação no mercado e estão sendo contratados novos funcionários para os setores recém criados. Por esse motivo, foi necessário investir em mais espaço no servidor do sistema. Foram comprados dois novos discos rígidos de 8GB para os diretórios "home" de todos os novos funcionários e é necessário que eles sejam configurados de forma a garantir a segurança dos dados no caso de falha de um dos discos e prevendo a possibilidade de futuras expansões de espaço. Além disso, foi comprado mais um disco de 4GB que deve ser particionado igualmente entre os novos setores para diretórios de "arquivos temporários" que não precisam prever nenhum tipo de redundância ou melhor performance, mas deve prever futuras expansões. Além das configurações dos novos discos é necessário a criação dos grupos (setores) e usuários (novos funcionários); a aplicação de políticas de cotas no "home"; definição de permissões para os diretórios de arquivos temporários. Essas atividades devem seguir o detalhamento abaixo.
Atenciosamente,
Diretoria de TI
1.13.1 Detalhamento
1.13.2 Montagem
Ponto de montagem para os diretórios "home":
/contas
Ponto de montagem para os arquivos temporários de cada grupo grupos:
/tmp/design
/tmp/estrategico
As partições devem ser montadas no boot, bem como os serviços dependentes (ex.: RAID)
Diretório "home" dos usuários, a serem criados a partir de agora, seja por padrão dentro de /contas
1.13.3 Grupos e Usuários
Os setores/funcionários são:
Design:
Pedro Silva
Paulo Santos
Estratégico:
Amaral Caxias
Ernesto Medeiros
O login dos funcionários é o primeiro nome.
Cada setor deve ter o seu grupo e os funcionários desses setores devem pertencer a este grupo.
1.13.4 Política de Cotas
Criar usuário padrão para cada setor e definir cotas a partir do usuário padrão.
Cada usuário do Design: 200MB (soft) 500MB (hard)
Cada usuário do Estratégico: 100MB (soft) 200MB (hard)
1.14 30/10: Serviços de rede
Visão geral de serviços e funções de rede típicos:
Configuração de interfaces de rede. Noções de roteamento.
DHCP: configuração automática de endereços IP em máquinas clientes
DNS: serviço de nomes, que associa nomes a endereços IP, entre outras finalidades.
LDAP: serviço de diretórios (um banco de dados hierárquico), para guardar informações administrativas, tais como usuários, grupos e contatos de email, usadas por outros serviços de rede.
HTTP: acesso a documentos em geral (uso mais notório para acesso a páginas Web)
FTP: transferência de arquivos
SMTP, IMAP4, POP3, LMTP: protocolos para envio de email e acesso a caixas de entrada
NFS e Samba: sistemas de arquivos de rede
Web proxy: controle de acesso e cache para acesso a WWW
NAT: tradução transparente de endereços IP, para mascarar endereços internos de uma rede (função de rede)
Filtro IP: restrições aplicadas a tráfego IP, visando melhorar o nível de segurança (função de rede)
SSH: acesso remoto seguro ao shell em um servidor
VPN: redes privativas virtuais
1.14.2 Interfaces de rede
Qualquer dispositivo (físico ou lógico) capaz de transmitir e receber datagramas IP. Interfaces de rede ethernet são o exemplo mais comum, mas há também interfaces PPP (seriais), interfaces tipo túnel e interfaces loopback. De forma geral, essas interfaces podem ser configuradas com um endereço IP e uma máscara de rede, e serem ativadas ou desabilitadas. Em sistemas operacionais Unix a configuração de interfaces de rede se faz com o programa ifconfig:
Ao se configurar uma interface de rede, cria-se uma rota automática para a subrede diretamente acessível via aquela interface. Isto se chama roteamento mínimo.
Todo sistema operacional possui alguma forma de configurar suas interfaces de rede, para que sejam automaticamente ativadas no boot com seus endereços IP. Por exemplo, em sistemas Linux Ubuntu (descrito em maiores detalhes em seu manual online), a configuração de rede se concentra no arquivo /etc/network/interfaces:
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo eth1
iface lo inet loopback
address 127.0.0.1
netmask 255.0.0.0
# a interface ethernet eth1
iface eth1 inet static
address 192.168.1.100
netmask 255.255.255.0
gateway 192.168.1.254
Esses arquivo é lido pelos scripts ifup e ifdown. Esses scripts servem para ativar ou parar interfaces específicas, fazendo todas as operações necessárias para isto:
# Ativa a interface eth1
ifupeth1
# Desativa a interface eth1
ifdowneth1
Para ativar, desativar ou recarregar as configurações de todas as interfaces de rede:
# desativa todas as interfaces de rede
sudo/etc/init.d/networkingstop
# ativa todas as interfaces de rede
sudo/etc/init.d/networkingstart
# recarrega as configurações de todas as interfaces de rede
sudo/etc/init.d/networkingrestart
Rotas estáticas podem ser adicionadas a uma tabela de roteamento. Nos sistemas operacionais Unix, usa-se o programa route:
# adiciona uma rota para a rede 10.0.0.0/24 via o gateway 192.168.1.254
routeadd-net10.0.0.0netmask255.255.255.0gw192.168.1.254
# adiciona uma rota para a rede 172.18.0.0/16 via a interface PPP pp0
routeadd-net172.18.0.0netmask255.255.0.0devppp0
# adiciona a rota default via o gateway 192.168.1.254
routeadddefaultgw192.168.1.254
# adiciona uma rota para o host 192.168.1.101 via o gateway 192.168.1.253
routeadd-host192.168.1.101gw192.168.1.253
A tabela de rotas pode ser consultada com o programa netstat:
# remove a rota para 10.0.0.0/24
routedelete-net10.0.0.0netmask255.255.255.0
# remove a rota para o host 192.168.1.101
routedelete-host192.168.1.101
1.14.4 Atividade
Verifique a configuração de sua interface de rede eth1, na máquina virtual Tecnologo-ger2. Se necessário corrija-a assim: ip 192.168.2.X, sendo X o número do computador + 100 (exemplo: para o micro 2 X=102), roteador default = 192.168.2.1.
Teste a comunicação do seu computador, fazendo ping 192.168.2.1. Tente pingar outras máquinas da rede.
Tente também pingar o IP 200.135.37.65.
Veja a tabela de rotas, usando netstat -rn.
Verifique a rota seguida pelos datagramas enviados, usando traceroute -n 200.135.37.65.
Configure sua máquina virtual para que a informação de rede, configurada manualmente acima, fique permanente. Quer dizer, no próximo boot essa configuração deve ser ativada automaticamente.
Adicione um IP alias a sua interface eth1. Esse novo IP deve estar na subrede 10.0.0.0.0/24
Tente pingar os computadores de seus colegas, usando ambos endereços: da rede 192.168.2.0/24 e da rede 10.0.0.0/24.
Enquanto acontecem os pings, visualize o tráfego pela interface eth1, usando o programa tcpdump:
# Mostra o tráfego ICMP que passa pela interface eth1
tcpdump-ieth1-lnicmp
Pense em uma utilidade para IP alias ...
1.15 11/11: Coleta de tráfego e NAT
Aula Extra (manhã)
1.15.1 Coleta e análise de tráfego
Uma ferramenta básica de análise de tráfego de rede faz a coleta das PDUs por interfaces de rede, revelando as informações nelas contidas. Dois programas bastante populares
para essa finalidade são:
nstreams: analisa a saída do tcpdump, e revela os fluxos em uma rede
driftnet: analisa o tráfego em uma interface, e captura imagens, videos e audio
1.15.2 NAT
A tradução de endereço de rede (NAT - Network Address Translation), proposta pela RFC 1631 em 1994, é uma função de rede criada para contornar o problema da escassez de endereços IP. Com a explosão no crescimento da Internet, e o mau aproveitamento dos endereços IP (agravado pelo endereçamento hierárquico), percebeu-se que o esgotamento de endereços poderia ser logo alcançado a não ser que algumas medidas fossem tomadas. Esse problema somente seria eliminado com a reformulação do protocolo IP, de forma a aumentar o espaço de endereços, que resultou na proposta do IPv6 em 1998. Porém no início dos anos 1990 a preocupação era mais imediata, e pensou-se em uma solução provisória para possibilitar a expansão da rede porém reduzindo-se a pressão por endereços IP. O NAT surgiu assim como uma técnica com intenção de ser usada temporariamente, enquanto soluções definitivas não se consolidassem. Ainda hoje NAT é usado em larga escala, e somente deve ser deixado de lado quando IPv6 for adotado mundialmente (o que deve demorar).
NAT parte de um princípio simples: endereços IP podem ser compartilhados por nodos em uma rede. Para isto, usam-se endereços IP ditos não roteáveis (também chamados de inválidos) em uma rede, sendo que um ou mais endereços IP roteáveis (válidos) são usados na interface externa roteador que a liga a Internet. Endereços não roteáveis pertencem às subredes 10.0.0.0/8, 192.168.0.0/16 e 172.16.0.0/12, e correspondem a faixas de endereços que não foram alocados a nenhuma organização e, portanto, não constam das tabelas de roteamento dos roteadores na Internet. A figura abaixo mostra uma visão geral de uma rede em que usa NAT:
Para ser possível compartilhar um endereço IP, NAT faz mapeamentos (IP origem, port origem, protocolo transporte) -> (IP do NAT, port do NAT, , protocolo transporte), sendo protocolo de transporte TCP ou UDP. Assim, para cada par (IP origem, port origem TCP ou UDP) o NAT deve associar um par (IP do NAT, port do NAT TCP ou UDP) (que evidentemente deve ser único). Assim, por exemplo, se o roteador ou firewall onde ocorre o NAT possui apenas um endeerço IP roteável, ele é capaz em tese de fazer até 65535 mapeamentos para o TCP (essa é a quantidade de ports que ele pode possui), e o mesmo para o UDP. Na prática é um pouco menos, pois se limitam os ports que podem ser usados para o NAT. Note que o NAT definido dessa forma viola a independência entre camadas, uma vez que o roteamento passa a depender de informação da camada de transporte.
A regra acima faz com que todo o tráfego originado em 192.168.1.0/24, e que sai pela interface eth0 deve ser mascarado com o endereço IP dessa interface. Esta regra diz o seguinte: todos os pacotes que passarem (POSTROUTING) por esta máquina com origem de 192.168.1.0/24 e sairem pela interface eth0 serão mascarados, ou seja sairão desta máquina com o endereço de origem como sendo da eth0. O alvo MASQUERADE foi criado para ser usado com links dinâmicos (tipicamente discados ou ADSL), pois os mapeamentos se perdem se o link sair do ar. Para uso mais geral, com links permanentes, deve-se usar o alvo SNAT:
Uma outra possibilidade é mapear para um endereço da rede interna um tráfego originado externamente. Por exemplo, pode haver um servidor na rede interna que precisa ser acessado externamente, porém ele não possui um endereço IP roteável. O NAT no Linux possui a função DNAT que pode fazer essa tarefa:
Nesse exemplo, datagramas com IP destino 200.135.37.66 e contendo um segmento TCP com port 8080 são desviados para o port 80 no IP 192.168.1.10. Quer dizer, o IP de destino desses datagramas é de fato substituído por 192.168.1.10, e o port de destino é mudado para 80.
Note que DNAT é aplicado a chain PREROUTING.
Com estas configurações o cliente acessa qualquer site na internet mas não pode ser acessado. Por isto alguns textos colocam NAT na categoria de técniccas de segurança. Apesar de NAT prover o isolamento entre rede externa e interna, a não ser para os tráfegos mapeados, não se pode usá-lo sozinho como proteção de uma rede. Quer dizer, não se pode
prescindir de um bom firewall e políticas de segurança adequadas.
1.15.3 Atividade
Coleta de tráfego
Faça um ou mais pings para algum(ns) sítios e, com o uso de parâmetros apropriados, faça com que o tcpdump:
Capture todos os pacotes da rede.
Capture somente os pacotes gerados por sua máquina.
Capture somente pacotes destinados à sua máquina.
Capture pacotes destinados ou originados da máquina 172.18.0.1.
Faça com que os pacotes capturados anteriormente sejam salvos num arquivo, chamado “pacotes_capturados“.
Se desejar instale e capture pacotes com o WireShark.
Roteamento estático
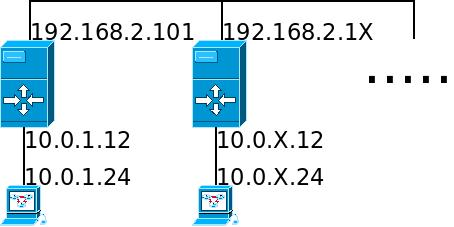
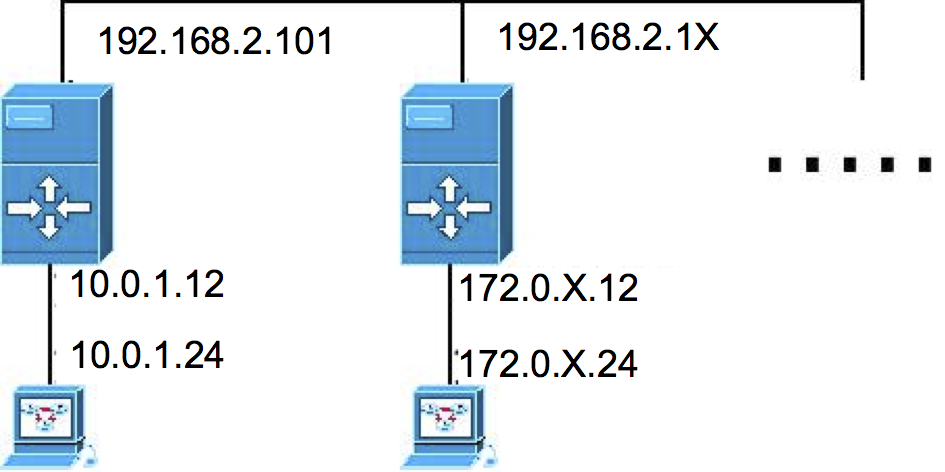
Configure a segunda interface de rede de sua máquina servidora, conforme números de IPs sugeridos na Ilustração mais abaixo.
Configure sua máquina servidora para rotear pacotes.
Configure sua máquina cliente para ser seu cliente de rede, conforme Ilustração 1.
Montar as tabelas estáticas de roteamento de modo que todas as máquinas tenham acesso entre si (“pingando” ente elas).
Faça testes. Se houver problemas usar tcpdump ou WireShark para monitorar individualmente as interfaces e verificar onde está o problema. Lembre-se que os pacotes devem ter rota de ida e volta, portanto o problema pode ser no seu roteador ou de seu vizinho. Uma boa sequência de testes é:
Pingar entre cliente e roteador.
Do cliente pingar a interface externa do roteador.
Do cliente pingar a máquina do professor. Se funcionar até aqui seu roteador estará corretamente configurado.
Do roteador pingar a interface externa de outro roteador.
Do roteador pingar outro cliente.
Do seu cliente pingar outro cliente.
NAT
Desfaça as tabelas de roteamento e configure a máquina servidora para fazer NAT, nos mesmos moldes do item 2.
Faça testes pingando para redes externas e para as redes dos colegas.
DNS (Domain Name System) é uma base de dados distribuída e hierárquica. Nela se armazenam informações para mapear nomes de máquinas da Internet para endereços IP e vice-versa, informação para roteamento de email, e outros dados utilizados por aplicações da Internet.
A informação armazenada no DNS é identificada por nomes de domínio que são organizados em uma árvore, de acordo com as divisões administrativas ou organizacionais. Cada nodo dessa árvore, chamado de domínio, possui um rótulo. O nome de omínio de um nodo é a concatenação de todos os rótulos no caminho do nodo até a raiz. Isto é representado como uma string de rótulos listados da direita pra esquerda e separados por pontos (ex: ifsc.edu.br, sj.ifsc.edu.br). Um rótulo precisa ser único somente dentro do domínio pai a que pertence.
Por exemplo, um nome de domínio de uma máquina no IFSC pode ser mail.ifsc.edu.br, em que br é o domínio do topo da hierarquia ao qual mail.sj.ifsc.edu.br pertence.
Já edu é um subdomíno de br, ifsc um subdomínio de edu, e mail o nome da máquina em questão.
Por razões administrativas, o espaço de nomes é dividido em áreas chamadas de zonas, cada uma iniciando em um nodo e se estendendo para baixo para os nodos folhas ou nodos onde outras zonas iniciam. Os dados de cada zona são guardados em um servidor de nomes, que responde a consultas sobre uma zona usando o protocolo DNS.
Clientes buscam informação no DNS usando uma biblioteca de resolução (resolver library), que envias as consultas para um ou mais servidores de nomes e interpreta as respostas.
Cada rótulo na hierarquia DNS possui um conjunto de informações associadas a si. Essas informações são guardas em registros
de diferentes tipos, dependendo de seu significado e propósito. Cada consulta ao DNS retorna assim as informações do registro pedido associado ao rótulo. Por exemplo, para ver o registro de endereço IP associado a www.ifsc.edu.br pode-se executar esse comando (o resultado teve alguns comentários removidos):
Cada uma das informações acima mostra um determinado registro e seu conteúdo, como descrito na tabela abaixo:
Nome
TTL
Classe
Registro
Conteúdo do registro
hendrix.sj.ifsc.edu.br.
3600
IN
A
200.135.37.65
sj.ifsc.edu.br.
3600
IN
NS
hendrix.sj.ifsc.edu.br.
sj.ifsc.edu.br.
3600
IN
MX
10 hendrix.sj.ifsc.edu.br.
Obs: TTL é o tempo de validade (em segundos) da informação retornada do servidor de nomes, e classe é o tipo de endereço (no caso IN equivale a endereços Internet).
Os tipos de registros mais comuns são:
Registro
Descrição
Exemplo
A
Endereço (Address)
www.sj.ifsc.edu.br IN A 200.135.37.66
NS
Servidor de nomes (Name Server)
sj.ifsc.edu.br IN NS hendrix.sj.ifsc.edu.br.
CNAME
Apelido (Canonical Name)
mail.sj.ifsc.edu.br IN CNAME hendrix.sj.ifsc.edu.br.
MX
Roteador de email (Mail Exchanger)
sj.ifsc.edu.br IN MX mail.sj.ifsc.edu.br.
SOA
dados sobre o domínio (Start of Authority)
sj.ifsc.edu.br IN SOA hendrix.sj.ifsc.edu.br. root.sj.ifsc.edu.br. 2009120102 1200 120 604800 3600
PTR
Ponteiro para nome (Pointer)
65.37.135.200.in-addr.arpa IN PTR hendrix.sj.ifsc.edu.br.
TXT
Texto genérico (Text)
sj.ifsc.edu.br IN TXT "v=spf1 a mx ~all"
Uma zona assim é composta de um conjunto de registros com todas as informações dos domínios nela contidos. O conteúdo de uma zona, contendo o domínio example.com, pode ser visualizado abaixo:
example.com 86400 IN SOA ns1.example.com. hostmaster.example.com. (
2002022401 ; serial
10800 ; refresh
15 ; retry
604800 ; expire
10800 ; minimum
)
IN NS ns1.example.com.
IN NS ns2.smokeyjoe.com.
IN MX 10 mail.another.com.
IN TXT "v=spf1 mx -all"
ns1 IN A 192.168.0.1
www IN A 192.168.0.2
ftp IN CNAME www.example.com.
bill IN A 192.168.0.3
fred IN A 192.168.0.4
1.16.2 Atividade
O objetivo é montar a seguinte estrutura:
Vamos configurar e testar um servidor DNS. Para tanto montaremos a estrutura indicada no diagrama, onde cada máquina será um servidor DNS, com um domínio próprio e, ao mesmo tempo, será cliente do servidor DNS da máquina 192.168.2.101. Esta, por sua vez, será servidor um servidor master do domínio redes.edu.br e servidor escravo, recebendo automaticamente uma cópia das zonas dos servidores masters, de todos os demais domínios criados. Esta, será também a única máquina com servidor DNS com zona reversa. Sendo assim todos os domínios, diretos e reversos, serão visíveis por meio deste servidor.
Entendendo o serviço DNS. Antes de qualquer reconfiguração faça testes usando a ferramenta “dig”:
Siga o roteiro da apostila e inicialize o servidor DNS, criando o domínio redesX.edu.br (onde X é o último dígito do ip de sua máquina). Por questões práticas, acima mencionadas, não crie zona reversa.
O servidor DNS deverá responder pelos nomes: da própria máquina (etiqueta), www, ftp e mail, todos apontando para o mesmo IP.
No /etc/resolv.conf declare nameserver 192.168.2.101.
type master;
file "/etc/bind/redes4.zone";
allow-transfer {
192.168.4.101;
};
};
</syntaxhighlight>
vim /etc/bind/redes4.zone
redes4.edu.br. IN SOA ns.redes4.edu.br. admin.redes4.edu.br. (
2010041202; serial
3H ; refresh
60 ; retry
1W ; expire
3W ; minimum
)
IN NS ns; este é o servidor master deste domínio
IN NS ns.redes5.edu.br. ; este é um servidor slave (o computador do professor)
IN MX 10 mail
mail IN A 192.168.4.104
www IN A 192.168.4.104
ftp IN A 192.168.4.104
ns IN A 192.168.4.104
</syntaxhighlight>
vim /etc/resolv.conf
nameserver 192.168.4.104
</syntaxhighlight>
Utilitário para testar o arquivo que contém o conteúdo de uma zona:
# named-checkzone nome_do_dominio arquivo_da_zona
# Assume que você esteja no diretório onde está o redes.zone
named-checkzone redes.edu.br redes.zone
Utilitário para testar a configuração do BIND:
# Assume que você esteja no diretório onde está o named.conf
named-checkconf named.conf
Restart do serviço:
service bind9 restart
Seqüênica de Testes:
dig redes4.edu.br soa
dig mail.redes4.edu.br a
ping mail.redes4.edu.br
1.17 13/11: Servidor web Apache
O servidor Apache (Apache server) é o mais bem sucedido servidor web livre. Foi criado em 1995 por Rob McCool, então funcionário do NCSA (National Center for Supercomputing Applications), Universidade de Illinois. Ele descende diretamente do NCSA httpd, um servidor web criado e mantido por essa organização. Seu nome vem justamente do reaproveitamento do NCSA httpd (e do fator de tê-lo tornado modular) fazendo um trocadilho com a expressão "a patchy httpd (um httpd remendável). Para ter ideia de sua popularidade, numa pesquisa realizada em dezembro de 2005 foi constatado que sua utilização supera 60% nos servidores ativos no mundo. O servidor é compatível com o protocolo HTTP versão 1.1. Suas funcionalidades são mantidas através de uma estrutura de módulos, podendo inclusive o usuário escrever seus próprios módulos — utilizando a API do software. É disponibilizado em versões para os sistemas Windows, Novell Netware, OS/2 e diversos outros do padrão POSIX (Unix, GNU/Linux, FreeBSD, etc).
Um servidor web é capaz de atender requisições para transferência de documentos. Essas requisições são feitas com o protocolo HTTP (HyperText Transfer Protocol), e se referem a documentos que podem ser de diferentes tipos. Uma requisição HTTP simples é mostrada abaixo:
Para o servidor Web, os principais componentes de uma requisição HTTP são o método HTTP a executar e o localizador do documento a ser retornado (chamado de URI - Uniform Resource Indicator). No exemplo acima, a requisição pede o método GET aplicado à URI /. O resultado é composto do status do atendimento, cabeçalhos informativos e o conteúdo da resposta. No exemplo, o status é a primeira linha (HTTP/1.1 200 OK), com os cabeçalhos logo a seguir. Os cabeçalhos terminam ao aparecer uma linha em branco, e em seguida vem o conteúdo (ou corpo) da resposta.
Todo documento possui um especificador de tipo de conteúdo, chamado de Internet media Type. O cabeçalho de resposta Content-type indica o media type, para que o cliente HTTP (usualmente um navegador web) saiba como processá-lo. No exemplo acima, o documento retornado é do tipo text/html, o que indica ser um texto HTML. Outros possíveis media types são: text/plain (texto simples), application/pdf (um texto PDF), application/x-gzip (um conteúdo compactado com gzip).
Um documento no contexto do servidor web é qualquer conteúdo que pode ser retornado como resposta a uma requisição HTTP. No caso mais simples, um documento corresponde a um arquivo em disco, mas também podem ser gerados dinamicamente. Existem diversas tecnologias para gerar documentos, tais como PHP, JSP, ASP, CGI, Python, Perl, Ruby, e possivelmente outras. Todas se caracterizam por uma linguagem de programação integrada intimamente ao servidor web, obtendo dele informação sobre como gerar o conteúdo da resposta. Atualmente, boa parte dos documentos que compõem um site web são gerados dinamicamente, sendo PHP, JSP e ASP as tecnologias mais usadas.
1.17.1 Informações gerais sobre Apache no Ubuntu
Instalação:
sudoapt-getinstallapache2
Arquivos de configuração ficam em /etc/apache2:
apache2.conf: a configuração inicia aqui
Diretório sites-available: configurações de hosts virtuais
Diretório sites-enabled: hosts virtuais atualmente ativados
Para iniciar o Apache:
sudoserviceapache2start
Para testar o Apache: com um navegador acesse a URL http://192.168.2.X/ (X é 102 para o micro 2, 103 para o 3, e assim por diante).
1.17.2 Uma configuração básica
O servidor Apache precisa de algumas informações básicas para poder ativar um site:
Qual seu nome de servidor: seu nome DNS , como www.sj.ifsc.edu.br
Em que portas ele atende requisições: as portas TCP onde ele recebe requisições HTTP. Por default é a porta 80, mas outras portas podem ser especificadas.
Onde estão os documentos que compõem o site hospedado: o caminho do diretório onde estão esses documentos
Quem pode acessar os documentos: restrições baseadas em endereços IP de clientes e/ou nomes de usuários e grupos.
No exemplo abaixo, define-se um servidor WWW chamado www.ger.edu.br, que atende requisições nos ports 80 e 443:
# O nome de servidor
ServerName www.ger.edu.br
# As portas onde se atendem requisições HTTP
Listen 80 443
# Onde estão os documentos desse site
DocumentRoot /var/www/ger
# As restrições de acesso aos documentos
<Directory /var/www/ger>
Options Indexes
DirectoryIndex index.html index.php
order allow,deny
allow from all
</Directory>
Além dessas configurações, diversas outras se referem a opções do Apache, tais como modos de operação, identificação de tipos de documentos, extensões (funcionalidades) suportadas, e outras. Usualmente essas configurações já estão definidas de forma conveniente no arquivo de configuração do Apache.
No seu domínio DNS redeX.edu.br (X é o número do seu computador), adicione um registro A para www, associando-o ao IP de sua máquina virtual. Crie também um registro A para o nome webmail, associando-o ao mesmo IP.
Um servidor Web típico deve suportar em sua configuração a especificação de que requisições HTTP ele é capaz de atender. Isto inclui o nome do servidor (ex: www.das.ufsc.br), e as localizações dos documentos que ele pode retornar, assim como restrições de acesso a esses documentos. No caso do servidor Apache, a configuração reside em arquivos contidos no diretório /etc/apache2. Toda a configuração é feita por meio de diretivas, que são válidas para determinados escopos. Escopos correspondem aos conjuntos de documentos para os quais se aplica, e pode ser um diretório (que contém arquivos que correspondem a documentos), ou uma localização (que corresponde a uma determinada URI). Como os documentos se organizam de forma parecida com diretórios, os escopos também são hierárquicos. Isto significa que a configuração contida em um escopo é válida para todos os escopos abaixo dele, a não ser naqueles onde ela é redefinida. Por exemplo, no arquivo /etc/apache2/sites-enabled/000-default (que especifica a configuração do site default) há o seguinte escopo:
Ele indica que o escopo / (diretório raiz) tem como opção habilitada somente FollowSymLinks ("siga links simbólicos"), e para fins de controle de acesso não permite nenhuma modificação. Assim, todos os diretórios abaixo desse terão as mesmas restrições, a não ser que um novo escopo mais específico seja definido. De fato, nesse arquivo de configuração há outros escopos:
<Directory /var/www/>
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order allow,deny
allow from all
</Directory>
Esse novo escopo se aplica ao diretório /var/www, adicionando algumas opções e modificando as restrições de acesso (permite o acesso de todos). Uma configuração semelhante, porém baseada na URI, segue abaixo:
<Location /docs>
Options Indexes -FollowSymLinks
AllowOverride None
Order allow,deny
allow from 192.168.2.0/24
</Location>
Veja que ela se aplica a URI /docs. Assim, todas as URIs abaixo de /docs estão sujeitas às restrições ali definidas.
1.18.2 Hosts virtuais
Há muitos recursos no servidor Apache, que estão descritos em profundidade em sua documentação. Além da lista de diretivas, seguem abaixo alguns que merecem uma olhada:
Hosts virtuais (Virtual Hosts)
Autenticação e controle de acesso
Suporte a redirecionamentos
Expressões regulares
Filtros
Ativação de extensões
Associação de plugins e extensões a mime-types
Dentre essas, Hosts virtuais tem largo uso porque possibilita que um mesmo servidor Apache hospede de forma independente diferentes sites. Cada site atende por um diferente nome de servidor (ServerName na terminologia do Apache), que corresponde ao seu nome DNS . Por exemplo, www.sj.ifsc.edu.br, webmail.sj.ifsc.edu.br são hosts virtuais hospedados no mesmo servidor Apache que fica no servidor hendrix.sj.ifsc.edu.br (verifique a resolução DNS desses nomes com o utilitário 'dig).
Um host virtual define a configuração de um site. Essa configuração fica sendo exclusiva desse site, e portanto não interfere (nem é interferida) pelas configurações de outras hosts virtuais. No entanto, tudo o que foi definido para o site global vale para os hosts virtuais, a não ser que neles seja redefinido. Assim, o exemplo anterior para o site www.ger.edu.br poderia estar dentro de um host virtual:
<VirtualHost *:80>
# O nome de servidor
ServerName www.ger.edu.br
# Onde estão os documentos desse site
DocumentRoot /var/www/ger
# As restrições de acesso aos documentos
<Directory /var/www/ger>
Options Indexes
DirectoryIndex index.html index.php
order allow,deny
allow from all
</Directory>
</VirtualHost>
1.18.3 Módulos
Módulos estendem a funcionalidade do Apache, e podem ser ativados ou desativados em sua configuração. Módulos são ativados com a diretiva LoadModule:
PHP (Personal Homepage): uma linguagem de programação voltada para a criação de páginas dinâmicas. Para disponibilizá-la deve-se instalar o pacote com o módulo php5:
sudoapt-getinstall-yphp5
Para testá-lo crie um arquivo chamado teste.php com o conteúdo abaixo, e coloque-o no DocumentRoot do seu site:
<?phpecho"Hello world";?>
SSL (Secure Socket Layer): provê o acesso a página com sigilo e autenticação baseada em certificados digitais.
Rewrite: possibilita manipular URLs e URIs por meio de expressões regulares.
Crie hosts virtuais para www.redeX.ger.edu.br e webmail.redeX.ger.edu.br. Esses hosts virtuais deve ter como DocumentRoot respectivamente os diretórios /var/www/novo e /var/www/webmail.
Restrinja o acesso ao novo servidor WWW a pessoas autorizadas. Essas pessoas devem se autenticar, fornecendo um usuário e senha. Para isto, algumas diretivas devem ser adicionadas:
AuthType Basic
AuthName "Acesso Restrito"
AuthUserFile /etc/apache2/senhas
Require user aluno
Além disto, o arquivo de senhas precisa ser criado:
htpasswd-c-s/etc/apache2/senhasusuario
Modifique a restrição acima para que ela seja aplicada somente aos acessos a URI /docs.
Ative o módulo PHP5. Instale-o com:
sudoapt-getinstall-yphp5
... e em seguida teste-o criando uma página de nome index.php, com o seguinte conteúdo:
O correio eletrônico (email) é um dos principais serviços na Internet. De fato foi o primeiro serviço a ser usado em larga escala. Trata-se de
um método para intercâmbio de mensagens digitais. Os sistemas de correio eletrônico se baseiam em um modelo armazena-e-encaminha (store-and-forward) em que os servidores de email aceitam, encaminham, entregam e armazenam mensagens de usuários.
Uma mensagem de correio eletrônico se divide em duas partes:
Cabeçalhos: contém informações de controle e atributos da mensagem
Corpo: o conteúdo da mensagem
From: Roberto de Matos <roberto@eel.ufsc.br>
Content-Type: text/plain;
charset=iso-8859-1
Content-Transfer-Encoding: quoted-printable
X-Smtp-Server: smtp.ufsc.br:roberto.matos@posgrad.ufsc.br
Subject: =?iso-8859-1?Q?Teste_Ger=EAncia?=
Message-Id: <0595A764-EEAE-41E7-99F0-80DC11FB5327@eel.ufsc.br>
X-Universally-Unique-Identifier: 684c3833-bbbe-420b-8b66-d92d9a419bc0
Date: Wed, 20 Nov 2013 11:36:35 -0200
To: Roberto de Matos <roberto.matos@ifsc.edu.br>
Mime-Version: 1.0 (Mac OS X Mail 6.6 \(1510\))
Ol=E1 Pessoal,
Hoje vamos aprender o funcionamento do Email!!
Abra=E7o,
Roberto=
Na mensagem acima, os cabeçalhos são as linhas iniciais. Os cabeçalhos terminam quando aparece uma linha em branco, a partir de que começa o corpo da mensagem.
1.20.1 Funcionamento do email
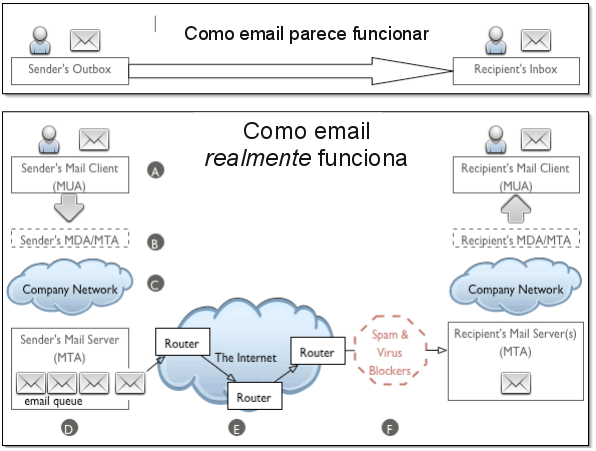
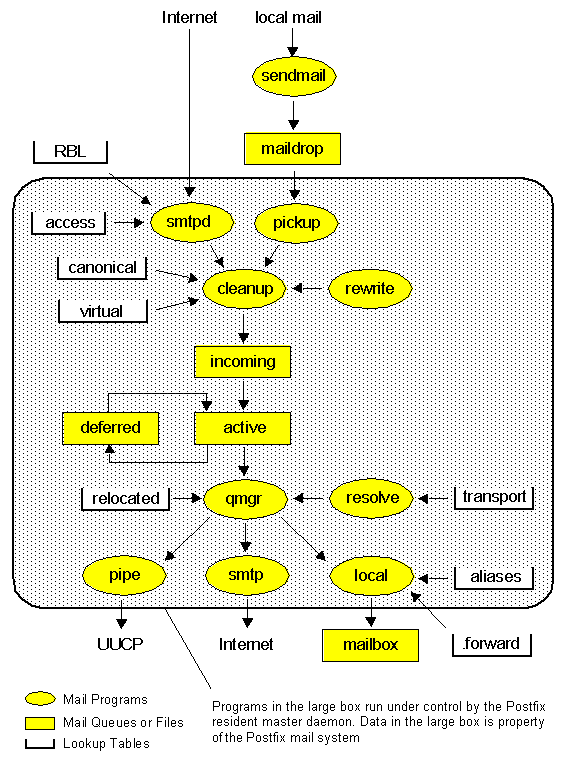
Os componentes da infraestrutura de email são:
MUA (Mail User Agent): o aplicativo que o usuário usa para envio e acesso a mensagens. Atualmente é bastante comum MUA do tipo webmail, mas existem outros como Mozilla Thunderbird, KMail e Microsoft Outlook.
MDA (Mail Delivery Agent): o servidor responsável por receber dos usuários mensagens a serem enviadas. Assim, quando um usuário quer enviar uma mensagem, usa um MUA que contata o MDA para fazer o envio. Exemplos de software são Postfix, Sendmail, Qmail e Microsoft Exchange.
MTA (Mail Transport Agent): o servidor responsável por transmitir mensagens até seu destino, e receber mensagens da rede para seus usuários. Comumente faz também o papel de MDA. Exemplos de softwares são Postfix, Sendmail, Qmail e Microsoft Exchange.
A figura abaixo ilustra uma infraestrutura de email típica.
Os protocolos envolvidos são:
SMTP (Simple Mail Transfer Protocol): usado para envios de mensagens entre MTAs, e entre MUA e MDA/MTA.
IMAP (Internet Mail Access Protocol): usado por MUAs para acesso a mensagens armazenadas em caixas de email em servidores.
POP (Post Office Protocol): mesma finalidade que IMAP, porém com funcionalidade mais limitada. Se destina a situações em que o normal é copiar as mensagens parao computador do usuário, e então removê-las do servidor.
LMTP (Local Mail Transfer Protocol): usado para entrega de mensagens entre MTA e MDA/MTA, sendo que o servidor de destino não mantém uma fila de mensagens (quer dizer, ele entrega diretamente na caixa de entrada de um usuário ou a encaminha imediatamente).
1.20.2 Endereçamento
Endereços de email estão intimamente ligados ao DNS. Cada usuário de email possui um endereço único mundial, definido por um identificador de usuário e um domínio de email, escritos usando-se o símbolo especial @ (lê-se at, do original em inglês) para conectá-los:
tele@ifsc.edu.br
Nesse exemplo, o identificador de usuário é tele, e o domínio é ifsc.edu.br.
Os domínios de email tem correspondência direta com domínios DNS. De fato, para criar um domínio de email deve-se primeiro criá-lo no DNS. Além disto, o domínio DNS deve ter associado a si um ou mais registros MX (Mail exchanger) para apontar os MTAs responsáveis por receber emails para o domínio. Por exemplo, o domínio DNS ifsc.edu.br possui esse registro MX:
> dig ifsc.edu.br mx
;; QUESTION SECTION:
;ifsc.edu.br. IN MX
;; ANSWER SECTION:
ifsc.edu.br. 3581 IN MX 5 hermes.ifsc.edu.br.
... e o domínio gmail.com:
> dig gmail.com mx
;; QUESTION SECTION:
;gmail.com. IN MX
;; ANSWER SECTION:
gmail.com. 3600 IN MX 20 alt2.gmail-smtp-in.l.google.com.
gmail.com. 3600 IN MX 30 alt3.gmail-smtp-in.l.google.com.
gmail.com. 3600 IN MX 40 alt4.gmail-smtp-in.l.google.com.
gmail.com. 3600 IN MX 5 gmail-smtp-in.l.google.com.
gmail.com. 3600 IN MX 10 alt1.gmail-smtp-in.l.google.com.
1.20.3 MTA Postfix
O primeiro software MTA usado em larga escala na Internet foi o sendmail. Esse MTA possui muitas funcionalidades, e enfatiza a felxibilidade em sua configuração. No entanto, configurá-lo e ajustá-lo não é tarefa fácil. Além disto, houve vários problemas de segurança no passado envolvendo esse software. Assim outras propostas surgiram, como qmail e postfix. Tanto qmail quanto postfix nasceram como projetos preocupados com a segurança nas operações de um MTA, e também se apresentaram como MTAs mais simples de configurar e operar. Em nossas aulas será usado o postfix, mas recomenda-se experimentar usar as outras duas opcões citadas.
O postfix é um MTA modularizado, que divide as tarefas de processamento das mensagens em diversos componentes que rodam como processos separados. Isto difere bastante do sendmail, que se apresenta como um software monolítico. No postfix, um conjunto de subsistemas cuida de processar cada etapa da recepção ou envio de uma mensagem, como mostrado na figura abaixo:
A configuração do postfix é armazenada em arquivos, que normalmente residem no diretório /etc/postfix. Os dois principais são:
master.cf: configurações para execução dos subsistemas do Postfix (define que subsistemas estão ativados, quantas instâncias rodar de cada um, e seus argumentos de execução)
main.cf: configurações usadas pelos subsistemas
No Ubuntu deve-se iniciar o uso do Postfix com esses comandos:
sudoapt-getinstall-ypostfix
# O comando abaixo deve ser usado se o postfix já foi instalado, mas deseja-se recriar sua configuração
sudodpkg-reconfigurepostfix
As configurações iniciais informadas na instalação são suficientes para que o postfix possa ser iniciado. No entanto muitos detalhes provavelmente precisarão ser ajustados para que ele opere como desejado.
Para um rápido teste do postfix pode-se fazer a sequência abaixo:
O resultado do teste (a mensagem entreguepara o usuário postmaster) pode ser visto no arquivo de log do postfix. No Ubuntu esse arquivo é /var/log/mail.log :
> tail /var/log/mail.log
May 2 17:29:42 ger postfix/smtpd[1965]: 71259CCA3: client=localhost[127.0.0.1]
May 2 17:30:48 ger postfix/cleanup[1970]: 71259CCA3: message-id=<20100502202942.71259CCA3@ger>
May 2 17:30:48 ger postfix/qmgr[1894]: 71259CCA3: from=<aluno@ifsc.edu.br>, size=323, nrcpt=1 (queue active)
May 2 17:30:48 ger postfix/local[1972]: 71259CCA3: to=<root@ger.edu.br>, orig_to=<postmaster@ger.edu.br>, relay=local, delay=102, delays=102/0.05/0/0.03, dsn=2.0.0, status=sent (delivered to mailbox)
May 2 17:30:48 ger postfix/qmgr[1894]: 71259CCA3: removed
May 2 17:31:25 ger postfix/smtpd[1965]: disconnect from localhost[127.0.0.1]
>
A mensagem de teste foi entregue em /var/mail/root:
Instale o postfix em sua máquina virtual. Configure-o para que se comunicar na Internet, criando o domínio de email redeX.edu.br, sendo X o número do seu computador.
Teste o funcionamento do postfix, enviando um email para postmaster@redeX.edu.br.
Teste o envio de mensagens para os domínios de seus colegas. Acompanhe o processamento das mensagens olhando o log do postfix.
Tente usar o servidor SMTP de seu colega para enviar uma mensagem para o domínio de um terceiro colega.
Edite a configuração do postfix (arquivo /etc/postfix/main.cf), de forma a negar receber mensagens vindas de clientes com domínio de email de remetente desconhecido. Dica: ver a documentação oficial do postfix.
1.20.5 Dicas
Atenção para vários problemas comuns na implantação do correio eletrônico:
Domínio DNS sem registro MX: sem isso os MTAs não sabem como enviar mensagens para esse domínio
Registro MX aponta um nome de host desconhecido: causa o mesmo problema acima
Nome de host configurado como localhost no Postfix: o nome de host (parâmetro myhostname em /etc/postfix/main.cf) deve ser o nome DNS do servidor onde roda o Postfix.
Erros de configuração (sintaxe) em /etc/postfix/main.cf: tais erros podem fazer com que um dos subsistemas do Postfix aborte sua execução, impedindo que se processe uma mensagem. Por exemplo, se um parâmetro usado pelo subsistema smtpd (que recebe mensagens com protocolo SMTP) estiver errado, o smtpd não iniciam, ou termina abruptamente, abortando a recepção de mensagens.
1.21 27/11: Email (cont.)
Dovecot é um MDA de fácil instalação que suporta acessos com IMAP e POP3. As caixas de entrada podem ser armazenadas nos formatos mailbox ou Maildir.
O MTA precisa ser modificado para gravar as mensagens em formato Maildir. Assim, deve-se adicionar a seguinte linha a /etc/postfix/main.cf:
home_mailbox = Maildir/
Para iniciar o Dovecot:
servicedovecotstart
1.21.1 Webmail
Webmail é um MUA baseado em web, portanto acessível com um navegador. A popularização dos webmails se deu pela facilidade de uso, pois dispensam a instalação de um software MUA em computadores de usuários. Existem atualmente diversos webmail disponíveis, tais como:
IMP e MIMP, sua versão com Ajax (Asynchronous Javscript Programming)
A grande maioria dos webmails usam o protocolo IMAP para acessarem as caixas de email de usuários. Algumas exceções são Uebimiau, projeto de webmail brasileiro que usa também POP3, e SqWebMail, que acessa diretamente as caixas de entrada em disco.
Os webmails são desenvolvidos em uma linguagem de programação para web, tal como PHP e Java, e usualmente precisam de uma infraestrutura de software para poderem funcionar. Essa estrutura é composta de um servidor web com suporte à linguagem de programação do webmail (ex: Apache com extensão PHP), um banco de dados (ex: MySQL, PostgreSQL ou Sqlite), um servidor IMAP com acesso às caixas de email de usuários, e um MTA para envio de mensagens.
1.21.2 Atividades
Instalar o Dovecot, e usá-lo para acessar a caixa de entrada e pastas IMAP.
1.23 04/12: Prova 2 – Serviços de Rede
Prezado(a) Gerente de Redes,
Foi definida a necessidade da criação de uma máquina com a função de roteador para interligação entre as filias e a matriz, seguindo o esquema da figura abaixo.
Além disso, é necessário que cada filial possua um servidor DNS para atender ao domínio filialX.br, um servidor de correio eletrônico, um servidor Apache com as características abaixo e um webmail acessível somente da rede daquela filial. Com exceção do DNS, todos os outros serviços devem rodar em uma máquina interna na rede (ex.: 10.0.1.24) com as devidas configurações no roteador.
Atenciosamente,
Diretoria de TI
1.23.1 Observações:
X varia de 03 à 16 ( 192.168.2.113 ==> 13 etc). NÃO serão aceitas mudanças de nome ou IP, siga rigorosamente os dados/atributos descritos.
As máquinas na rede das filiais (ex.: 10.0.X.24) deverão pingar as máquinas da matriz (ex.: 10.0.1.24). Avise o professor para fazer os testes.
Servidor Apache:
Porta de acesso 3030
Módulo PHP ativo e página em PHP
Outras configurações são inferidas do texto acima.
Todas as máscaras de rede: 255.255.255.0.
1.26 16/12: Recuperação
Prezado Gerente de Redes,
A rede e o servidor da empresa devem passar por uma remodelagem. Atualmente temos os seguintes problemas:
Falta de espaço para usuários;
Uso inadequado do espaço no home;
Problema na expansão do sistema de disco;
Falta de serviços de rede.
Para resolver tais problemas foram comprados 4 novos discos rígidos de 8GB para o servidor principal e uma nova placa de rede, que possibilitará que o servidor principal tenha a função de roteador também, e um novo servidor para os serviços.
Os 4 novos discos do roteador deverão ser configurados da seguinte forma:
Garantir a segurança dos dados no caso de falha de um dos discos e melhoria no desempenho (respectivamente);
Facilitar futuras expansões de espaço;
2 Partições com pontos de montagem em /newhome/ (4GB) e /docs/ (4GB)
Montagem no boot
Migração de todos os diretórios de usuários para o /newhome/
Aplicação de políticas de cotas (criando usuário padrão para cada setor e definir cotas a partir do usuário padrão)
Diretório padrão para o "home" dos usuários deve ser /newhome/
A remodelagem da rede segue o esquema da figura abaixo:
Os serviços que devem ser instalados e configurados no novo servidor são:
DNS para atender ao domínio recX.br
Servidor de correio eletrônico,
Servidor Apache com as características abaixo
Webmail acessível somente com autenticação HTTP
Atenciosamente,
Diretoria de TI
Política de Cotas:
Criar usuário padrão para cada setor e definir cotas a partir do usuário padrão.
Cada usuário do Engenharia: 200MB (soft) 500MB (hard)
Cada usuário do Comercial: 100MB (soft) 200MB (hard)
X varia de 03 à 16 ( 192.168.2.113 ==> 13 etc). NÃO serão aceitas mudanças de nome ou IP, siga rigorosamente os dados/atributos descritos.
As máquinas na rede interna (ex.: 172.0.X.24) deverão pingar as máquinas da matriz (ex.: 10.0.1.24).
O Servidor Apache deve estar acessível de fora da rede interna.
Servidor Apache:
Porta de acesso 7070
Módulo PHP ativo e página em PHP
Outras configurações são inferidas do texto acima.