Uma câmera no painel do carro filma (ou tira fotos) da estrada. Via processamento de imagem, as placas de sinalização são detectadas pelo sistema, que emite um aviso ao motorista. Trabalho feito em MATLAB.
Revisão bibliográfica
Sistemas diversos
- Usa um sistema centralizado, semelhante ao GPS
| Anotações do artigo
|
|
O trabalho proposto segue uma linha bem diferente dos demais trabalhos feitos anteriormente para o mesmo intuito. Foi um dos primeiros trabalhos a não utilizar técnicas baseadas na visão, ou seja, técnicas que utilizam o processamento de imagens provenientes de câmeras acopladas ao sistema. Por isso, o presente trabalho não está sujeito aos obstáculos enfrentados por estas técnicas como problemas relacionados às condições de tempo, luminosidade, ângulo, etc, que devem ser contornados na detecção e reconhecimento de placas de sinalização.
A técnica utilizada envolve o uso de uma arquitetura Cliente-Servidor da qual o veículo (cliente) envia requisições periódicas contendo informações de posição geográfica através de um sistema de posição global(GPS) para uma base de dados (servidor). A base de dados que contém armazenada toda a informação referente as placas de sinalização em uma determinada região (posição geográfica, nome das ruas e uma breve descrição do conteúdo de cada placa) responde a requisição indicando qual placa de sinalização possui maior proximidade no ângulo de deslocamento do veículo.
| Vantagens e Desvantagens
|
|
Vantagens
Se comparado à outros sistemas que utilizam técnicas de detecção de regiões de interesse como o Histograma de Gradientes Orientados (HOG) ou Regiões de Máxima Estabilidade (MSER), o trabalho proposto possui uma latência muito pequena, como é possível observar no gráfico abaixo, do qual apresenta a relação entre os sistemas e o tempo de latência.
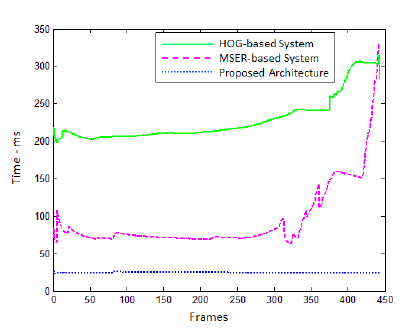 Fonte: Próprio Artigo
Fonte: Próprio Artigo
Desvantagens
Apesar de possuir baixa latência, a taxa de acerto do sistema depende totalmente da precisão do GPS utilizado. Caso ocorra o envio de uma posição diferente da posição do veículo, mesmo em dezenas de metros, o sistema pode responder a requisição com uma placa de sinalização incorreta. Outra questão é que para o perfeito funcionamento do sistema, é requerido um link de boa confiabilidade e taxas de transmissão e recepção aceitáveis.
|
|
Trabalhos em português/Trabalhos brasileiros
| Anotações do trabalho
|
|
O trabalho proposto apresenta uma arquitetura híbrida, que é formada por um mecanismo de atenção visual e uma rede neural, para localizar e reconhecer placas de sinalização. Sendo assim, esta arquitetura é divida em dois módulo: Um módulo para detecção e um para o reconhecimento. A figura 1 abaixo apresenta o fluxograma desta arquitetura.
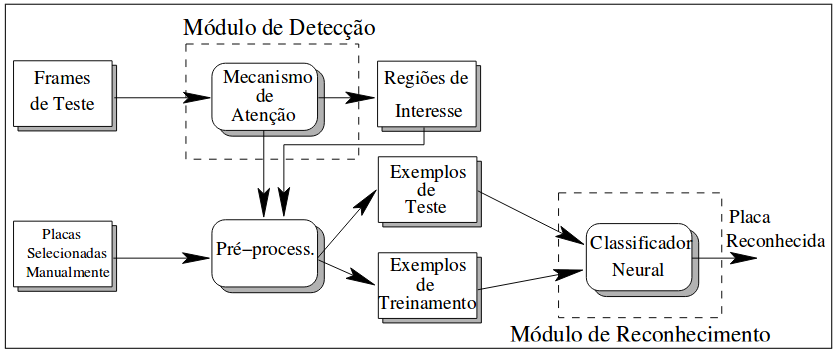 Figura 1 - Arquitetura geral do sistema: os retângulos representam os dados e os retângulos arredondados representam os processos
Fonte: Próprio Trabalho
Figura 1 - Arquitetura geral do sistema: os retângulos representam os dados e os retângulos arredondados representam os processos
Fonte: Próprio Trabalho
| Detecção
|
|
O módulo de detecção foi implementado a partir da adaptação do modelo proposto por Itti e Colegas [Itti et al., 1998] que é apresentado pelo figura 2.
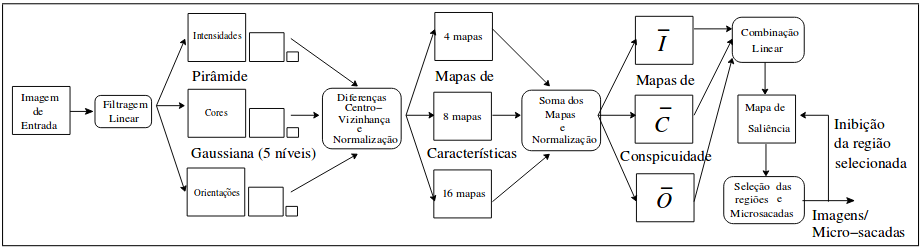 Figura 2 - Arquitetura do módulo de detecção
Fonte: Próprio Trabalho
Figura 2 - Arquitetura do módulo de detecção
Fonte: Próprio Trabalho
As etapas do módulo de detecção estão:
- Filtragem Linear: A etapa de filtragem linear consiste da extração de características como cor, intensidade e orientação. Para cada imagem de entrada são criado 4 canais de cores, obtidos através dos componentes RGB da imagem e através das equações:
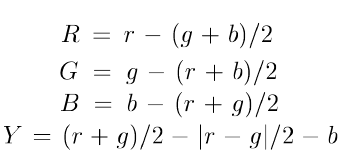
Onde, para cada canal, são geradas Pirâmides Gaussianas de cinco níveis. A intensidade da imagem é definida como  , ou seja, é a própria imagem em níveis de cinza, onde uma pirâmide Gaussiana de 5 níveis também é gerada. Por último, a orientação é obtida através de I aplicando-se Filtros Direcionais e gerando uma pirâmide Direcional. , ou seja, é a própria imagem em níveis de cinza, onde uma pirâmide Gaussiana de 5 níveis também é gerada. Por último, a orientação é obtida através de I aplicando-se Filtros Direcionais e gerando uma pirâmide Direcional.
- Diferenças Centro-Vizinhança (Center-Surround Differences): é implementada como a diferença entre escalas finas e grossas, ou seja, o centro é um pixel da imagem na escala
 e a vizinhaça é o pixel correspondente em outra imagem na escala e a vizinhaça é o pixel correspondente em outra imagem na escala  da representação piramidal. A diferença entre duas imagens, denotada por da representação piramidal. A diferença entre duas imagens, denotada por  , é obtida pela interpolação das imagens para a escala fina e subtração ponto a ponto. A utilização de várias escalas produz extração de características multiescala, resultando em 28 Mapas de Características. O número de mapas é definido pela combinação das escalas c e v e pela orientação. , é obtida pela interpolação das imagens para a escala fina e subtração ponto a ponto. A utilização de várias escalas produz extração de características multiescala, resultando em 28 Mapas de Características. O número de mapas é definido pela combinação das escalas c e v e pela orientação.
- Mapa de saliência: constitui-se como a soma dos mapas de características nas diversas escalas obtidas, resultando em três mapas de conspicuidade (Intensidade, Cor e Orientação). O mapa de saliência é utilizando então para determinar a região de interesse, da qual corresponde aos pixels de maior valor do mapa.
|
| Reconhecimento
|
|
Para o módulo de reconhecimento foi utiliada uma Rede Neural Multilayer Perceptron com algoritmo de treinamento Back Propagation(MLP-BP), por se tratar de uma técnica de classificação tradicional, de fácil utilização e com inspiração biológica.
|
| Experimentos e Resultados
|
|
A construção do banco de imagens foi baseado um vídeo filmado a partir de um veículo em movimento, durante uma viagem com dia claro entre as cidades de João Pessoa e Campina Grande. O hardware de aquisição consistiu de uma câmera CCD comum em um tripé, montado na frente do assento direito do carro (assento do passageiro).
Os conjuntos de treinamento e teste foram compostos de três classes de imagens: placas pare, placas proibido ultrapassar e imagens sem placas, cada classe contendo 14 imagens.
Para a tarefa de classificação das imagens, foi utilizada uma Rede com a seguinte arquitetura: 400 neurônios na camada de entrada (imagens de entrada de tamanho 20x20), 200 neurônios na camada escondida (empiricamente definida como tendo metade dos neurônios da camada de entrada) e 3 neurônios na camada de saída).
Resultados Iniciais
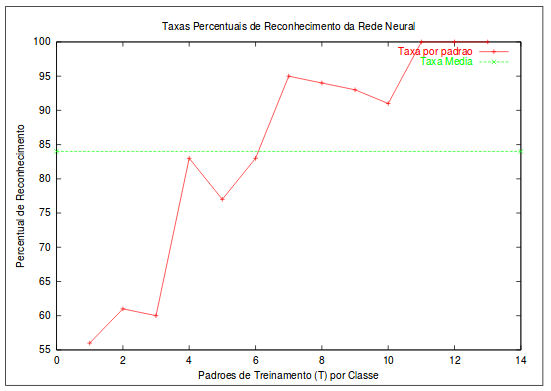 Figura 3 - Gráfico de taxa de acerto da Rede Neural
Fonte: Próprio Trabalho
Figura 3 - Gráfico de taxa de acerto da Rede Neural
Fonte: Próprio Trabalho
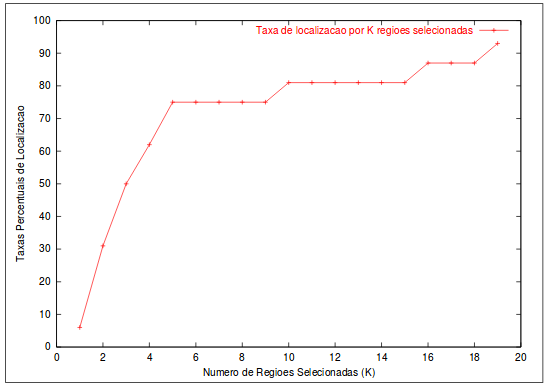 Figura 4 - Taxas percentuais de localização das placas em todas as imagens, quando consideramos um número K de regiões selecionadas
Fonte: Próprio Trabalho
Figura 4 - Taxas percentuais de localização das placas em todas as imagens, quando consideramos um número K de regiões selecionadas
Fonte: Próprio Trabalho
|
|
| Anotações do trabalho
|
|
O seguinte trabalho propõe a detecção e reconhecimento, em tempo real, de placas de sinalização de velocidade através de uma aplicação android utilizando técnicas de processamento de imagem para as etapas de detecção e reconhecimento. Para a etapa de detecção foi utilizado uma cascata de classificadores boosted baseados em características Haar-like.
| Detecção
|
|
Para o entendimento da etapa de detecção, é necessário apresentar alguns conceitos:
| Boosting
|
|
O Boosting é uma técnica de aprendizado de máquina que basicamente consiste em desenvolver um classificador forte a partir de classificadores fracos, em termos de níveis de predição [1]. Mas o que são classificadores fracos? Vamos entender através do exemplo do spam[2].
Podemos definir se um e-mail é um spam ou não através dos seguintes critérios:
- Se o e-mail possui apenas uma imagem(propaganda), então é um spam.
- Se o e-mail possui apenas links, então é um spam.
- Se o e-mail é de uma pessoa conhecida, então não é um spam.
- Se o e-mail possui a palavra "dinheiro" no seu corpo, então é um spam.
- Se o e-mail é da sua empresa, então não é um spam.
Definimos acima um série de classificadores fracos que, individualmente, não são fortes o suficiente para definir se um e-mail é um spam ou não. Para tornar uma classificação fraca em uma classificação forte, devemos então combinar os classificadores fracos em um único classificador forte utilizando esquemas de peso ou votação.
Algoritmo Boosting
O algoritmo Boosting funciona da seguinte forma:
- Do conjunto total de dados é retirado uma parcela para o treinamento. Na figura 1 abaixo nosso conjunto possui os elementos pertencentes a classe (+) e a classe (-).
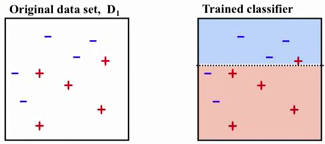 Figura 1 - Conjunto para Treinamento
Fonte: [3]
Figura 1 - Conjunto para Treinamento
Fonte: [3]
- Para o primeiro algoritmo base, são destacadas os elementos que foram erroneamente classificados. Estes elementos serão entrada para o próximo algoritmo base que se concentrará na classificação destes. A figura 2 abaixo apresenta três estaǵios de classificação.
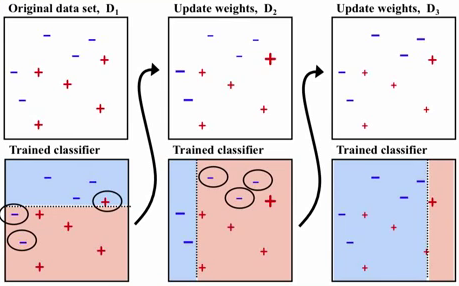 Figura 2 - Classificadores Fracos
Fonte: [4]
Figura 2 - Classificadores Fracos
Fonte: [4]
- Ao final do processo, os classificadores fracos são ponderados através de pesos referentes à relevância de cada um e combinados para formar o classificador forte capaz de deduzir com alta precisão quais elementos pertencem à qual classe. O processo final é apresentado abaixo pela figura 3.
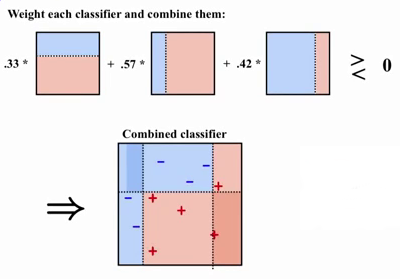 Figura 3 - Classificador Forte
Fonte: [5]
Figura 3 - Classificador Forte
Fonte: [5]
Adaboost
O algoritmo Adaboost foi o primeiro tipo de técnica Boosting apresentada por Freund and Schapire [6]. O nome é referente à Adaptive Boosting Algorithm, ou seja, o algoritmo Adaboost é basicamente um método boosting do qual é executado iterativamente e a cada iteração os pesos do classificadores fracos são reajustados [7]. O algoritmo Adaboost é definido pelas seguintes etapas[8]:
Dados de entrada
- Dados de treinamento:

- Distribuição
 com peso com peso 
- Número de interação T
- Classificador fraco W
Saída
Para cada interação é feito o seguintes passos:
- Treinar o classificador fraco com a distribuição D_t
- Obter a hipótese fraca e computar o erro
- Atualizar a distribuição utilizando o erro obtido
Ao final os classificadores são combinados para resultar em H.
|
|
|
Via processamento de imagens
- Traz um apanhado geral sobre vários tipos de técnicas. Usa pré-processamento, SIFT (Scale-Invariant Feature Transform e SVM(Support Vector Machine)
| Anotações do artigo
|
|
O seguinte trabalho propõe um sistema de detecção e reconhecimento de placas de sinalização de trânsito, dando foco na extração das características das regiões de interesse, especialmente na otimização desta etapa utilizando o algoritmo Scale-Invariant Feature Transform (SIFT) em conjunto com o procedimento de análise de componentes principais (Principal Component Analysis - PCA). Na etapa de classificação é utilizada a técnica de Máquinas de Vetores de Suporte (SVM).
| Scale-Invariant Feature Transform - SIFT
|
|
O SIFT(Scale-Invariant Feature Transform) é uma técnica utilizada para detecção e extração de regiões de interesse que são praticamente invariáveis a mudanças de iluminação, ruído, rotação e escala. Após a detecção das regiões de interesse (chamadas neste trabalho como pontos-chave) em uma imagem, é criado um descritor de característica para cada região. Estes descritores são comparados entre si e possibilitam o casamento entre diferentes imagens contendo o mesmo objeto. O algoritmo que executa esta técnica é apresentado pelos seguintes passos:
- Criação da pirâmide de imagens: O primeiro passo do algoritmo é criação de uma pirâmide de imagens ou de uma pirâmide Gaussiana. Primeiramente, para se obter a pirâmide, é realizado sucessivas convoluções entre a imagem original e um filtro gaussiano de fator σ multiplicado por uma constante k(0,k,2k,...), onde cada componente formado possui um nível de resolução menor(ou com efeito blur maior) é faz parte do conjunto denominado de oitavas.
A partir das oitavas são gerados os intervalos, onde cada intervalo é a diferença entre duas oitavas consecutivas aproximação do Laplaciano da Gaussiana)[1]. A figura 1 abaixo apresenta o espaço de escala e a diferença das Gaussianas. A figura 2 apresenta a aplicação deste processo sobre uma imagem.
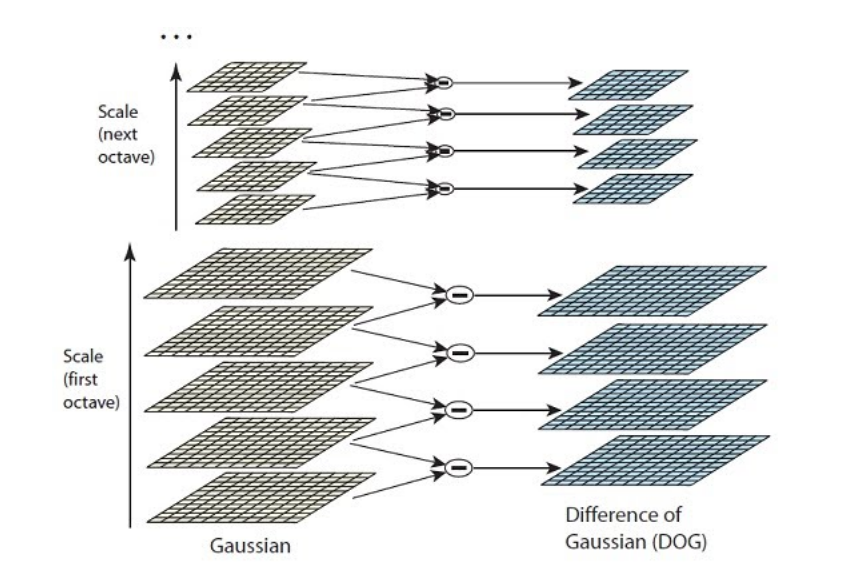 Figura 1 - Pirâmide Gaussiana
Fonte: [1]
Figura 1 - Pirâmide Gaussiana
Fonte: [1]

 Figura 2 - Aplicação em uma imagem
Fonte: Próprio artigo
Figura 2 - Aplicação em uma imagem
Fonte: Próprio artigo
- Localização dos pontos chaves: Os pontos chaves são encontrados comparando-se as regiões entre um determinado intervalo e as regiões dos intervalos vizinhos acima e abaixo. Os pontos chaves são identificados como os pontos de máximo(regiões totalmente pretas envoltas por áreas brancas) e pontos de mínimo(regiões brancas envoltas por área pretas) dos quais serão utilizados para a próxima etapa. Os pontos não identificados como pontos chaves, no caso, aqueles que possuem baixo contraste ou são localizados nas arestas, são eliminados.[2].
- Orientação do ponto-chave: Delimitando a área do ponto-chave, são determinados os gradientes e orientações de cada pixel, acumulados em um histograma de 36 posições. Para cada histograma, é determinado a posição máxima de maior magnitude e para este valor é criado um vetor espacial relacionando-o ao respectivo ponto-chave [2].
- Criação dos descritores locais: Por fim, para cada ponto chave, é estabelecido um descritor de característica utilizando uma janela de 16x16 ao redor do ponto. Um novo histograma é criado para a respectiva região e a união de todos os histogramas em uma matriz de 128 dimensões formará o descritor do ponto-chave[2].
Essas informações extraídas serão utilizadas posteriormente para a etapa de classificação.
|
| Análise de Componentes Principais - PCA
|
|
A análise de componentes principais (Principal Component Analysis) é uma técnica estatística que consiste em transformar um conjunto de variáveis em outro conjunto de dimensão menor capaz de fornecer o mesmo tipo de informação. Os componentes deste novo conjunto são denominados componentes principais. Os componentes principais apresentam importantes propriedades: cada componente principal é uma combinação linear de todas as variáveis originais, são independentes entre si e estimados com o propósito de reter, em ordem de estimação, o máximo de informação, em termos da variação total contida nos dados [3].A análise de componentes principais é associada à ideia de redução de massa de dados, com menor perda possível da informação. Procura-se redistribuir a variação observada nos eixos originais de forma a se obter um conjunto de eixos ortogonais não correlacionados.
Esta técnica é utilizada neste trabalho com o objetivo de otimizar a extração das características das regiões de interesse e consequentemente aumentar a precisão dos sistema de detecção e reconhecimento de placas de sinalização de trânsito.
|
| Máquina de Vetores de Suporte - SVM
|
|
Uma Máquina de vetores de suporte (Support vector machine -SVM) é uma técnica de aprendizagem utilizada para classificação de classes binárias. Os resultados da aplicação desta técnica são comparáveis e muitas vezes superiores aos obtidos por outros algoritmos de aprendizado como as Redes Neurais Artificiais (RNAs). Exemplos de aplicações de sucesso podem ser encontradas na categorização de textos, reconhecimento de imagens e na Bioinformática.
O objetivo do algoritmo é encontrar a melhor escolha para um hiperplano que classifica os dados de entrada em duas classes distintas. Os fatores mais importantes são as margens entre o hiperplano e os dados adjacentes ao hiperplano, correspondentes à cada classe.
O técnica SVM pode ser utilizada para multiclasses posicionando a SVM binária em um estrutura de árvore.
|
| Resultados
|
|
Os resultados alcançados estão apresentados pela tabela 1:
 Tabela 1 - Resultados
Fonte: Próprio artigo
Tabela 1 - Resultados
Fonte: Próprio artigo
|
|
- Compara diversos métodos: Redes Neurais artificiais (ANN), Vizinhos k-Próximos (kNN), SVM, Random Forest (RF) e HOG (Histogram of Oriented Gradients)
| Anotações do artigo
|
|
A proposta do trabalho é apresentar um sistema para detecção e reconhecimento para placas de sinalização de trânsito dando foco na comparação entre as principais técnicas de classificação utilizadas nos trabalhos anteriores. O sistema é particionado em três principais estágios: segmentação da região de interesse utilizando características de cor (saturação e matiz), análise do formato da placa (círculo, retângulo ou triângulo) e classificação através de diversas técnicas. Rede neural artificial (ANN), K-Vizinhos Mais Próximos (K-Nearest Neighbor - KNN), Máquina de vetores de suporte (Support Vectores Machine - SVM) e Random Forest (RF).
| Segmentação das Cores e Análise do Formato
|
|
O processo de segmentação das cores foi aplicado através de um esquema de binarização, como é apresentado pela tabela 1 abaixo.
 Tabela 1 - Segmentação das cores
Fonte: Próprio artigo
Tabela 1 - Segmentação das cores
Fonte: Próprio artigo
Para a análise do formato de cada placa de sinalização, foi aplicado uma técnica denominada Centroid-Based Graph (CBG), da qual resulta na classificação das regiões de interesse em formato de círculo, triângulo e retângulo.
|
| Histograma de Gradientes Orientados
|
|
Para extrair as características da imagem de uma possível placa de sinalização foi utilizada a técnica denominada Histograma de Gradientes Orientados (HOG). Primeiramente, a imagem é redimensionada em uma área de 100x100 pixels (no caso do trabalho proposto) para manter um equilíbrio entre a precisão do reconhecimento e o processamento envolvido.
O HOG é obtido através de uma densa grade de células normalizadas em relação ao contraste. Cada célula forma um histograma em escala positiva de 8 bits, onde cada posição é relacionada às magnitudes dos pixels pertencentes a cada célula. Através dos valores máximos dos histogramas, um vetor espacial é obtido e representa a informação que será utilizada posteriormente no processo de classificação.
|
| Técnicas de Classificação
|
|
Entre os processos utilizados para classificação estão:
- Rede Neural Artificial: Modelo matemático inspirado nas redes neurais biológicas. A ANN consiste em um grupo de neurônios artificias separados em camadas e interconectados. Cada neurônio processa a informação utilizando um modelo complexo de relacionamento entre as entradas e saídas com o objetivo de encontrar um padrão entre os dados.
- K-Vizinhos Mais Próximos: O princípio deste algoritmo é baseado no conceito de que os dados de uma mesma classe possuem características espaciais próximas ou semelhantes. O procedimento básico é determinar através de um probabilidade estatística relacionada à uma distância mínima k quais regiões pertencem à uma determinada classe de interesse.
- Máquina de vetores de suporte: (comentada em outros artigos).
- Random Forest: É um algoritmo computacional de aprendizagem que constrói uma elevada quantidade de árvores de decisão as quais são utilizadas para classificar um novo dado fornecido.
|
| Experimento e Resultados
|
|
O experimento foi realizando utilizando o banco de dados do sistema de placas de sinalização alemão. Deste banco de dados foram extraídas entre 300 à 700 imagens para treinamento ou teste de cada classe. Toda a classificação foi implementada utilizando a plataforma Matlab através de um computador com a seguinte especificação: 3GHz Pentium 4, 2GB RAM e Windows 32 bits.
A comparação das técnicas de classificação foi dividida em dois casos específicos:
- Caso 1: 75% da imagens seriam utilizadas para treinamento enquanto que o resto seria utilizado para os testes.
- Caso 2: Todas as imagens de treinamento e de testes seriam utilizadas.
A performance do sistema é apresentado pela tabela 2 (caso 1) e pela tabela 3 (caso 2) abaixo:
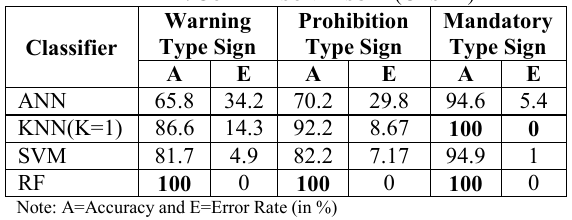 Tabela 2 - Resultado para o caso 1
Fonte: Próprio artigo
Tabela 2 - Resultado para o caso 1
Fonte: Próprio artigo
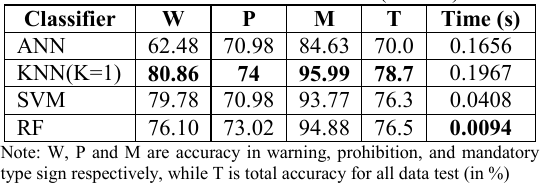 Tabela 3 - Resultado para o caso 2
Fonte: Próprio artigo
Tabela 3 - Resultado para o caso 2
Fonte: Próprio artigo
A conclusão feita é que o sistema utilizando a técnica de classificação Random Forest alcançou um nível de precisão bastante elevando, porém gerando grande latência ao sistema. Por outro lado, o sistema utilizando a Rede Neural Artifical, possuindo na maioria dos casos um precisão pobre, conseguiu atingir o menor valor de latência.
|
|
- Usa componentes de cor
| Anotações do artigo
|
|
O seguinte trabalho propõe um algo para detecção e reconhecimento de placas de sinalização que é apresentado pelo diagrama da figura 1 abaixo:
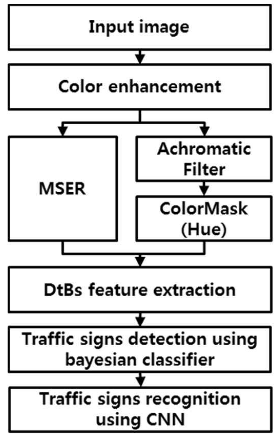 Figura 1 - Algoritmo Proposto
Fonte: Próprio artigo
Figura 1 - Algoritmo Proposto
Fonte: Próprio artigo
Durante a etapa de detecção, as imagens contendo possíveis placas de sinalização são preprocessadas descantando as regiões que possuem cores vermelhas e azuis, que são características das placas. Após o preprocessamento, as regiões que possuem as placas são segmentadas através da técnica denominada Maximally Stable Extremal Regions(MSER) em conjunto com filtros de imagem. Na etapa de detecção do formato da placa (triangular, circular e retangular), é utilizado o classificador Bayesian treinado com as características
| Aprimoramento das cores
|
|
Neste sistema, o aprimoramento das cores é aplicado para reduzir a taxa de erro de acordo com as variações de iluminação no ambiente onde é extraída a imagem da placa de sinalização. Além disso, com o aprimoramento das cores é possível diminuir também a latência do sistema na detecção, ressaltando as regiões de interesse. A figura 2 abaixo, apresenta a normalização da imagem em cores vermelha e azul destacando as regiões das placas com as respectivas cores.
 Figura 2 - Aprimoramento das cores
Fonte: Próprio artigo
Figura 2 - Aprimoramento das cores
Fonte: Próprio artigo
|
|
- Usa segmentação via cor e HOG (Histogram of Oriented Gradients)
| Anotações do artigo
|
|
Inclua aqui suas anotações
|
- Usa uma estrutura parecida, porém acrescenta o SVM
| Anotações do artigo
|
|
Inclua aqui suas anotações
|
- Usa os Momentos de Zernike e SVM
| Anotações do artigo
|
|
Inclua aqui suas anotações
|
- Usa detecção de cores e Projeção de Perfil
| Anotações do artigo
|
|
Inclua aqui suas anotações
|
- Usa um método de segmentação FCM (Fuzzy c-Means) e classificação CBIR (Content-Based Image Retrieval)
| Anotações do artigo
|
|
Inclua aqui suas anotações
|
- Usa espaço de cores HSV (matiz, saturação e valor), classificação por correlação e reconhecimento via distância euclidiana e filtro de Gabor
| Anotações do artigo
|
|
O objetivo do presente trabalho é apresentar um novo algoritmo para detecção, classificação e reconhecimento de placas de sinalização baseado no sistema de cores HSV(Hue, Saturation, Value) para a etapa de detecção e na correlação com um banco de placas existente para a etapa de classificação. Seguindo as etapas mencionadas, um vetor de características é formado através de filtros de Gabor que facilita o reconhecimento das placas usando a distância mínima, da qual é baseado na distância Euclidiana entre os vetores de características.
A figura 1 abaixo apresenta o fluxograma do algoritmo dividido em três subsistemas: detecção, classificação e reconhecimento.
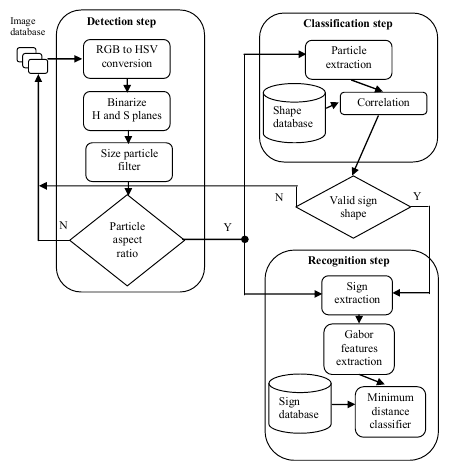 Figura 1 - Fluxograma do Algoritmo
Fonte: Próprio artigo
Figura 1 - Fluxograma do Algoritmo
Fonte: Próprio artigo
| Detecção
|
|
Na etapa de detecção, o primeiro procedimento é converter as imagens obtidas em um sistema RGB para um sistema HSV. O sistema HSV representa uma imagem em termos de matiz, saturação e brilho, como é apresentado pela figura 2 abaixo.
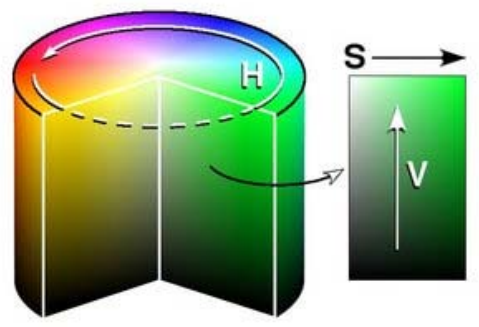 Figura 2 - Sistema HSV
Figura 2 - Sistema HSV
A característica de matiz representa o tipo da cor analisada. É possível observar na figura 2 que a matiz pode ser descrita em uma escala angular, porém normalizada entre valores de 0 a 255, sendo 0 a cor vermelha. Por sua vez, a saturação representa a oscilação da cor, também normalizada entre valores de 0 a 255. Quanto menor o valor de saturação, mais desbotada se torna a cor. Por fim, o brilho(na figura representado por V), representa a luminosidade, também normalizado entre valores de 0 a 255. Com brilho da cor estando em 0, a cor apresenta-se completamente escura, enquanto que o brilho da cor estando em 255, a cor apresenta-se totalmente branca.
Para identificar a regiões de interesse na imagem original foi realizado um realce da cor vermelha (cor característica da placas) através da aplicação dos valores de matiz e saturação de cada pixel no seguinte sistema:
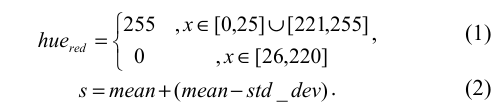
Onde mean é o valor médio da saturação do pixel e std_dev é o desvio padrão do histograma.
Os resultados são multiplicados resultando em uma imagem onde somente os pixels considerados vermelhos na imagem original existem. Os objetos encontrados na imagem são filtros utilizando a sua proporção em relação ao tamanho da imagem. No caso em que os objetos possuem proporção dentro do conjunto [0.8,1.2] são considerados como possíveis regiões de uma placa de sinalização, caso contrário são descartadas. A regiões de interesse obtidas são utilizadas, posteriormente, na etapa de classificação.
|
| Classificação
|
|
Na etapa de classificação, o objetivo é determinar se as regiões de interesse obtidas através da etapa de detecção possuem o formato triangular ou circular. Para isso, a regiões são isoladas da imagem obtida anteriormente, redimensionadas para uma área de 50x50 pixels e correlacionadas com uma imagem modelo através da equação (3) e das imagens apresentadas pela figura 3 abaixo:
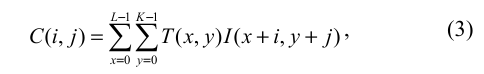
 Figura 3 - Imagens Modelos
Figura 3 - Imagens Modelos
Onde T(x,y) é a imagem modelo e I(x,y) é a imagem testada.
No caso em que o valor de correlação ultrapassar um limiar de 80%, a imagem em particular é considerada como uma placa no formato triangular ou circular, caso contrário esta é descartada.
|
| Reconhecimento
|
|
Um filtro de Gabor é um filtro passa banda que possui uma resposta ao impulsa definida por uma função harmônica multiplicada por um filtro Gaussiano. Portanto, um filtro bidimencional de Gabor constitui um plano sinusoidal complexo de uma determinada frequência e orientação, modulado por um envelope Gaussiano. A figura 4 abaixo apresenta a constituição de um filtro de Gabor através do procedimento mencionado anteriormente.
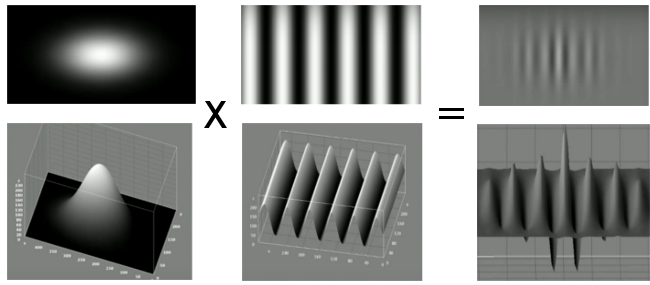 Figura 4 - Imagens Modelos
Fonte:Hemerson Pistori - Banco de Filtros de Gabor
Figura 4 - Imagens Modelos
Fonte:Hemerson Pistori - Banco de Filtros de Gabor
Um filtro de Gabor 2D é definido pela equação 4 abaixo:
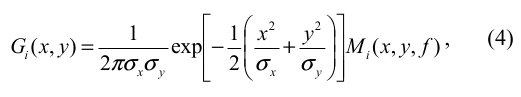
onde i=1,2, e:
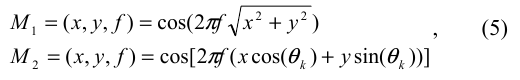
A frequência f provê a frequência a frequência de ressonância do filtro. É importante salientar que a atenuação das altas frequências implica em um suavização da imagem, enquanto a atenuação das baixas frequências implica em transições mais nítidas entre as regiões. O ângulo  corresponde ao deslocamento (orientação) na diagonal do filtro de Gabor. Por fim, os valores de corresponde ao deslocamento (orientação) na diagonal do filtro de Gabor. Por fim, os valores de  e e  representam o achatamento ou o esticamento do filtro de Gabor nos eixos x e y. Cada orientação é computada através da relação representam o achatamento ou o esticamento do filtro de Gabor nos eixos x e y. Cada orientação é computada através da relação  , onde k={1,...,n}. , onde k={1,...,n}.
O filtro de Gabor dado pela equação 4 possui a capacidade óptica de captura ambas posições de orientação e frequência de uma imagem digital. Neste trabalho os filtros foram configurados utilizando os seguintes parâmetros: , ,  , f = 1.4 e n = 5, o que significa , f = 1.4 e n = 5, o que significa  . Portanto, é criado um banco de filtros de Gabor composto por 5 canais com diferentes orientações. Cada filtro do banco é aplicado sobre as imagens obtidas na etapa de classificação através de um convolução, resultando em 5 novas imagens que formam um vetor de características da imagem original. . Portanto, é criado um banco de filtros de Gabor composto por 5 canais com diferentes orientações. Cada filtro do banco é aplicado sobre as imagens obtidas na etapa de classificação através de um convolução, resultando em 5 novas imagens que formam um vetor de características da imagem original.
Além das imagens de análise, o banco de filtros de Gabor também é aplicado sobre imagens de um banco composto por 10 imagens referentes à placas de sinalização e de cada placa também é extraído um vetor de características. A figura 5 abaixo apresenta as placas utilizadas no experimento.
 Figura 5 - Banco de Imagens
Fonte:Próprio Artigo
Figura 5 - Banco de Imagens
Fonte:Próprio Artigo
Possuindo os vetores de característica da imagem de entrada e das imagens do banco, o processo de classificação é realizado através do classificador de mínima distância, que obtém a mínima distância Euclidiana entre dois vetores de características.
|
| Resultados
|
|
O experimento foi realizado com o processamento de 313 imagens obtidas dentro de um carro ao longo das estradas Românias. As velocidades do veículo analisadas foram de 80km/h e 50km/h. Para capturar as imagens foi utilizada a câmera Sony XCD-V60CR à uma taxa de 30 fps em resolução de 630x480 pixels.
Com o objetivo de analisar a influência da iluminação sobre o experimento, for alterados os níveis de brilho das imagens analisadas em ±25 unidades, resultando em um banco com 939 imagens.
Os resultados são apresentados pelas tabelas 1 e 2 referentes às etapas de detecção/classificação e reconhecimento:
 Tabela 1 - Resultados para Detecção e Classificação
Fonte:Próprio Artigo
Tabela 1 - Resultados para Detecção e Classificação
Fonte:Próprio Artigo
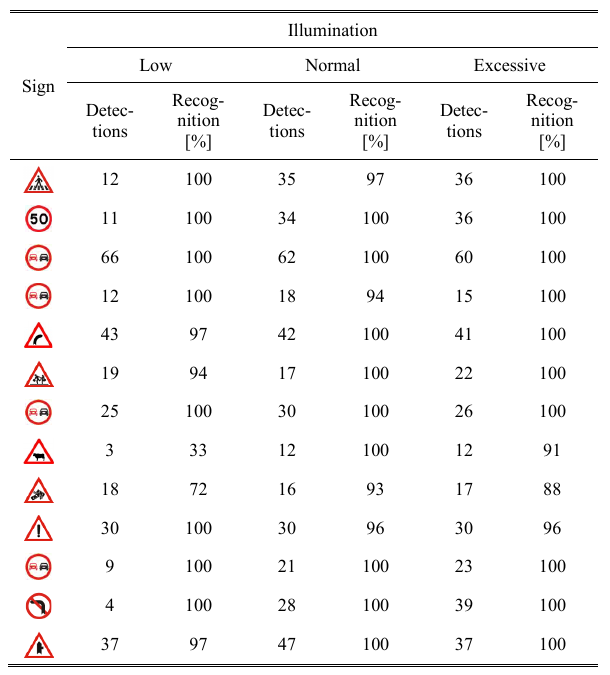 Tabela 2 - Resultados para Reconhecimento
Fonte:Próprio Artigo
Tabela 2 - Resultados para Reconhecimento
Fonte:Próprio Artigo
|
|
- Classificação via Filtro Vetorial Simples, Transformada Hough e Curve Fitting, e classificação via Momentos Pseudo-Zernike
| Anotações do artigo
|
|
O presente trabalho propõe o desenvolvimento de um sistema de reconhecimento de placas de sinalização de trânsito baseado no uso das propriedades de cor e forma na etapa de detecção, no uso dos momentos Pseudo-Zernike para a etapa de classificação e, por fim, no uso de Máquinas de Vetores de Suporte(SVM) para o reconhecimento final das placas.
O algoritmo proposto foi aplicado em 26 classes de placas de sinalização do sistema de sinalização de trânsito chinês, como é apresentado pela figura 1 abaixo:
 Figura 1 - 26 tipos de placas
Fonte: Próprio artigo
Figura 1 - 26 tipos de placas
Fonte: Próprio artigo
| Desenvolvimento
|
|
Segmentação da cor
Na etapa de detecção, é aplicado um algoritmo denominado Vetor Simples de Vetores(Simple Vector Filter - SVF) que nada mais é do que a segmentação das cores vermelha, amarela e azul que são as cores características das placas anteriormente apresentadas. Para isso, o algoritmo utiliza as seguintes relações:
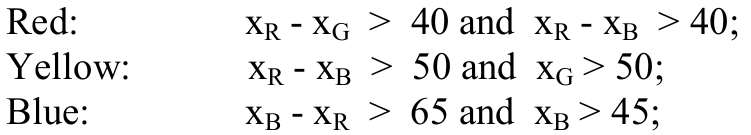
Aplicando o algoritmo sobre as placas da fígura 1, através da plataforma Matlab, temos o resultado apresentado pela figura 2 abaixo:
 Figura 2 - Algoritmo SVF
Fonte: Matlab
Figura 2 - Algoritmo SVF
Fonte: Matlab
Análise do Formato e Normalização
Após a segmentação das cores, o formato das regiões de interesse são obtidas através da Transformada de Hough. Esta transformada é um método para detectar formas que são facilmente parametrizadas (linhas, círculos, etc) em imagens digitais binárias. A ideia principal deste método é aplica uma transformada tal que todos os pontos pertencentes a uma determinada curvas sejam mapeados para um único pontos é um outro plano de parametrização[Transformada de Hough]. A figura 3 abaixo apresenta apresenta este procedimento para detecção de um reta.
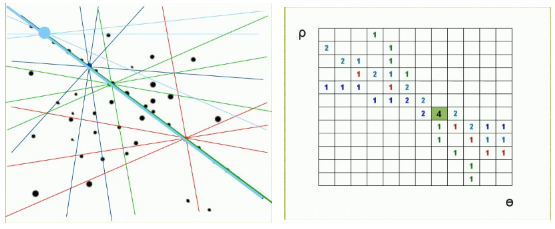 Figura 3 - Transformada Hough
Fonte: [Transformada de Hough]
Figura 3 - Transformada Hough
Fonte: [Transformada de Hough]
Onde a relação dos pontos com a reta é dada pelas equações apresentadas na figura 4 abaixo:
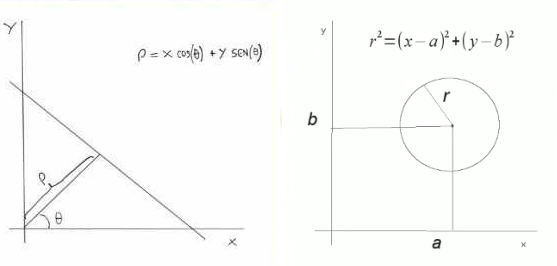 Figura 4 - (a) Detecção de reta, (b) Detecção de círculo
Fonte: [Transformada de Hough]
Figura 4 - (a) Detecção de reta, (b) Detecção de círculo
Fonte: [Transformada de Hough]
Ao fim deste processo temos a classificação das regiões de interesse nas classes que são apresentadas pela figura 5 abaixo:
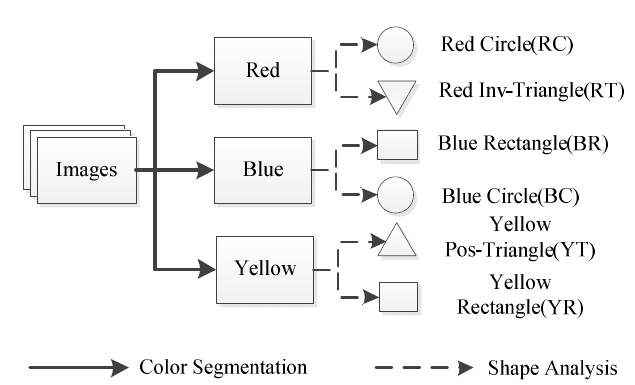 Figura 5 - Classificação do Formato
Fonte: Próprio artigo
Figura 5 - Classificação do Formato
Fonte: Próprio artigo
Defino ao fato que de que as regiões de interesse obtidas podem apresentar tamanhos diferentes, é aplicado sobre estas os algoritmo de Interpolação Bicúbica, do qual aplica sobre cada pixel uma média ponderada não-linear após o redimensionamento da imagem.
Extração da característica
Os momentos invariantes de uma imagem são funções derivadas de imagens previamente segmentadas que descrevem a distribuições espacial da intensidades (quantidade de cinza) do pixels das respectivas imagens ou regiões. Para isso as imagem são representadas através de um plano cartesiano ou um plano polar, onde cada pixel representa um ponto destes planos.
Os momentos são importantes para a etapa de reconhecimento pois resultam em uma descrição da imagem que é invariante à rotações, translações e redimensionamento em imagens. Os momentos de Zernike, além de possuírem estas características, são também ortogonais, tornando-os robustos a ruído e diminuindo a quantidade de dados. Os polinômios de Zernike, utilizados para se obter os momentos, são definidos através de coordenadas polares sobre um círculo unitários.
Os conjunto de Pseudo-Momentos de Zernike obtidos formam um vetor de características que será utilizado na etapa de classificação.
Classificação
A etapa de classificação utiliza Support Vectors Machine (SVM) já comentada em outros trabalhos.
|
| Experimento e Resultados
|
|
Foram coletadas aproximadamente 2600 imagens de placa de sinalização de trânsito coletadas sobre várias condições de tempo e localização. Para isso, uma câmera acoplada ao painel do veículo armazenava fotos do ambiente em uma resolução de 640x480 piles. Para o treinamento da SVM foram utilizadas cerca de 600 imagem redimensionadas para uma área de 51x51 pixels.
O desenvolvimento do sistema foi baseado na utilização da biblioteca LIBSVM para C++ e em OpenCV.
As tabelas 1 e 2 abaixo apresentam os resultados para a etapa de detecção/classificação e para a etapa de reconhecimento respectivamente:
 Tabela 1 - Resultados de Detecção/Classificação
Fonte: Próprio artigo
Tabela 1 - Resultados de Detecção/Classificação
Fonte: Próprio artigo
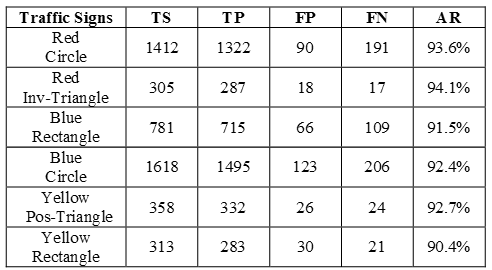 Tabela 2 - Resultados de Reconhecimento
Fonte: Próprio artigo
Tabela 2 - Resultados de Reconhecimento
Fonte: Próprio artigo
Como é possível observar através da tabela 2, o sistema conseguiu chegar à uma precisão maior que 90% em todos os casos demonstrando a robustez do sistema. Porém, é importante saliente que em condições mais adversas, como placas desbotadas, oclusão e influências de outras placas podem alterar significativamente este resultado.
Por fim, o sistema apresentou a seguinte latência: a segmentação das cores exigiu na média 60ms.
|
|
- Filtro Bilateral, Detector de Bordas Canny, Rede Neural Convolucional(CNN) e Máquina de Vetores de Suporte (SVM)
- Maximally Stable Extremal Regions (MSER), Histograma de Gradientes Orientados (HOG) e Cascata de SVMs.
Análise dos Trabalhos
Tabela de Técnicas Analisadas
| Trabalho | Ano | Extração da Região de Interesse | Classificação | Reconhecimento |
| Gao | 2014 | N/A | Scale-Invariant Feature Transform (SIFT)+ Análise dos Componentes Principais (PCA) | Máquina de Vetores de Suporte(SVM) |
| Wahyono | 2014 | Segmentação das Cores (Binarização de Matiz e Saturação) + Classificação da Forma(Centroid-Based Graph) | Histograma de Gradientes Orientados(HOG) |
Rede Neural Artificial(ANN)
K-Vizinhos mais Próximos
Máquina de Vetores de Suporte(SVM)
Random Forest(RF)
|
| Jang | 2016 | Normalização das Cores Vermelhas e Azul + Maximally stable extremal regions (MSER) | Bayesian com vetor Distance to Border(DtB) | Rede Neural Convolucional |
| Mariut | 2011 | Plano HSV + Binarização de Matiz e Saturação + Size Filter | Correlação com Banco de Imagens | Banco de Filtros de Gabor + Banco de Imagens |
| Chen | 2011 | Filtro Simples de Vetores(Segmentação de Cores) |
Transformada de Hough
Interpolação Bicúbica
Pseudo-Momentos de Zernike
| Máquina de Vetores de Suporte(SVM) |
| Lin | 2016 | Filtro Bilateral + Detector de Bordas Canny | Rede Neural Convolucional(CNN) | Máquina de Vetores de Suporte(SVM) |
| Greenhalgh | 2012 | Maximally Stable Extremal Regions (MSER) | Histograma de Gradientes Orientados (HOG) | Cascata de SVMs |
Legenda:
Complexidade Baixa
Complexidade Média
Complexidade Alta
Trabalhos Propostos
| Trabalho | Extração da Região de Interesse | Classificação | Reconhecimento |
| 1 | Maximally Stable Extremal Regions (MSER) | Rede Neural Convolucional(CNN) | Cascata de Máquina de Vetores de Suporte(SVM) |
| 2 | Pirâmide Gaussiana + Transformada Hough | Histograma de Gradientes Orientados(HOG) | Rede Neural Convolucional |
| 3 | Plano HSV + Binarização | Histograma de Gradientes Orientados(HOG) | Cascata de Máquina de Vetores de Suporte(SVM) |
Estudo das Técnicas
Histograma de Gradientes Orientados (HOG)
| Conceitos
|
|
Para o total entendimento do HOG é necessário introduzir alguns conceitos importantes como a representação da imagem e os próprios descritores
| Intensidade e Níveis de Cinza
|
|
A luz sem cor, chamada de luz monocromática, possui como único atributo a intensidade. Pelo fato de a intensidade ser percebida como variações de preto a tons de cinza até chegar ao branco, o termo níveis de cinza costuma ser utilizado para denotar a intensidade monocromática. Em termos de hardware, a intensidade quantificada resulta na resolução de intensidade. O número de níveis de intensidade é igual a  , sendo k um número inteiro. O número mais comum é 8 bits, resultando em um escala de 256 níveis de intensidade[4]. , sendo k um número inteiro. O número mais comum é 8 bits, resultando em um escala de 256 níveis de intensidade[4].
Em uma imagem, a resolução de intensidade, está diretamente relacionada com a resolução espacial, ou seja, para cada píxel da imagem e definido um nível de intensidade e este processo, denominado de quantização, é utilizado para a conversão de imagens em dados computacionais. No processamento de imagens, uma imagem é muitas vezes, convertida para níveis de cinza, dependendo do tipo de aplicação. Em nosso, trabalho a intensidade será utilizada para a geração dos gradientes.
|
| Gradientes
|
|
A ferramenta ideal para representar a intensidade no ponto  de uma imagem f, é o gradiente denotado por de uma imagem f, é o gradiente denotado por  , e definido como o vetor: , e definido como o vetor:
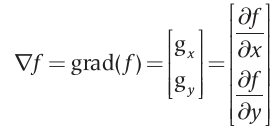
Este vetor gradiente tem a importante propriedade geométrica de apontar no sentido de maior taxa de variação de  no ponho . A magnitude no ponho . A magnitude  do vetor determina o valor da taxa de variação na direção do vetor gradiente e é definidor por: do vetor determina o valor da taxa de variação na direção do vetor gradiente e é definidor por:
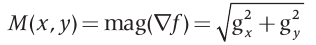
Onde  e são imagens do mesmo tamanho que a imagem original, criadas quando e são imagens do mesmo tamanho que a imagem original, criadas quando  e e  podem variar ao longo de todas as posições de pixels em . podem variar ao longo de todas as posições de pixels em .
A direção do vetor gradiente, assim como os demais componentes citados, também é uma imagem de mesmo tamanho que a original criada pela divisão de  pela imagem pela imagem  . O ângulo do vetor é definido como: . O ângulo do vetor é definido como:
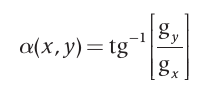
No nosso trabalho, os gradientes serão extraídos através dos histogramas das imagens.
|
| Representação
|
|
Após a segmentação da região de interesse na imagem, é necessário que esta região seja representada adequadamente para o futuro processamento computacional. Esta representação envolve utilizar características externas (bordas) e internas (pixels) e descrever a região com base em fatores diretamente relacionados à representação escolhida[4]. No caso das bordas, por exemplo, pode-se calcular a distância entre duas bordas adjacentes para determinar o tamanho da região de interesse.
A decisão de qual representação utilizar está relacionada às características da região das quais serão utilizadas para o processamento computacional. Um representação externa é escolhido quando o foco principal é o formato, enquanto que uma representação interna é escolhida quando o foco principal são cores e texturas[4].
|
| Descritores
|
|
Os descritores são formas de converter características relacionadas às representações que podem ser entendidas computacionalmente. Proporcionalmente, existem dois tipos de descritores: para características externas e características internas. Por exemplo, para as bordas de uma região de interesse, um descritor seria seu comprimento, do qual é aproximado pelos pixels ao longo da fronteira [4]. Neste trabalho focaremos nos descritores regionais devido ao algoritmo na etapa de detecção do sistema proposto.
Descritores Topológicos
Os descritores topológicos são descritores que representam adequadamente uma características de imagem e não são afetados por transformações na imagem. Por exemplo, se um descritor topológico é definido como o número de buracos na imagem, esta propriedade, obviamente, não será afetada por transformações de alongamento ou de rotação na imagem.
Descritores Baseados em Textura
Uma abordagem para descritores regionais é quantificar seu conteúdo através da textura da região. Apesa de que a textura não tenho um conceito formal, intuitivamente esse descritor fornece medidas de suavidade, rugosidade e regularidade. As três principais abordagens utilizadas no processamento de imagem para descrever a textura de uma região são[4]:
- Abordagem estatística: produzem caracterizações das texturas como suave, rugosa, granulada, e assim por diante;
- Abordagem estrutural: lidam com arranjos primitivos das imagem, como linhas paralelas espaçadas regularmente;
- Abordagem espectral: são baseadas em propriedades do espectro de Fourier;
Abordagens estatísticas
Uma das abordagens mais simples para descrever uma textura é usar momentos estatísticos do histograma de intensidades.
|
|
Máquina de Vetores de Suporte (SVM)
Referências
- ↑ 1,0 1,1 COUTINHO, D.P.; MARROQUIM R. SIFT - Scale Invariant Feature Transform. LCG Computer Graphics Lab, Universidade Federal do Rio de Janeiro, 2013
- ↑ 2,0 2,1 2,2 BELO, F. A. Desenvolvimento de Algoritmos de Exploração e Mapeamento Visual para Robôs Móveis de Baixo Custo. Diss. PUC-Rio, 2006.
- ↑ VARELLA, C. A. Análise de componentes principais. Universidade Federal Rural do Rio de Janeiro, Seropédica, 2008
- ↑ 4,0 4,1 4,2 4,3 4,4 GONZALEZ, Rafael C.; WOODS, Richard C. Processamento digital de imagens, Tradução: Cristina Yamagami e Leonardo Piamonte. 3ª Edição. São Paulo: Pearson. 2010
- ↑ 5,0 5,1 MARQUES, Ogé F.; VIEIRA Hugo.Processamento Digital de Imagens. Rio de Janeiro: Brasport. 1999
- ↑ 6,0 6,1 GONZALEZ, Rafael C.; WOODS, Richard E.; EDDINS, Steven L.Digital image processing using MATLAB. 2º Edition. India: McGraw. 2010.





































![{\displaystyle [0,L-1]}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/519ec65a9436d3a0094d9c7df1fb388723f0098f)










