Mudanças entre as edições de "MI1022806 2021 1 AULA05"
Ir para navegação
Ir para pesquisar
(Criou página com '=Conjuntos de Instruções= Um programador de linguagem de alto nível normalmente conhece muito pouco acerca da arquitetura da máquina que está usando. O conjunto de inst...') |
|||
| (Uma revisão intermediária pelo mesmo usuário não está sendo mostrada) | |||
| Linha 1: | Linha 1: | ||
| − | = | + | =Lista de Exercícios para (AT1)= |
| − | + | ;Nota: Nossa primeira avaliação será dia 29/06/2021 conforme previsto. Esta lista de exercícios servirá de guia de estudos para vocês, não vou corrigi-la e também vocês não precisarão entregá-la mas vou tirar todas as dúvidas de vocês via grupo do Whatsapp. | |
| − | + | ==Questões== | |
| − | + | ===Parte1=== | |
| − | + | #Por que estudar microprocessadores? | |
| + | #O que é um microprocessador? | ||
| + | #Disserte sobre o que significa, quando começou e quando terminou a chamada "lei de Moore". | ||
| + | #Explique o que significa ''single-core'' e ''multi-core'' em se tratando arquitetura de microprocessadores. | ||
| + | #O que você entende por ''um computador''? | ||
| + | #Quais os principais tipos de computador? | ||
| + | #O que é um ''Cluster'' e como funciona? | ||
| + | #O que são e para que servem os ''Mainframes''? | ||
| + | #O que difere um computador ''Desktop'' para um Supercomputador? | ||
| + | #No que se difere os "ditos" sistemas embarcados microcontrolados dos outros tipos de computadores? | ||
| + | #Cite 5 dispositivos eletrônico que você conheça que possuam Sistemas Embarcados? | ||
| + | #O que é RFID? | ||
| + | #Complete o desenho abaixo no que se refere a arquitetura e organização de um computador.[[imagem: fig067_MI1022806.png|400px|center]] | ||
| + | #O que é memória cache? | ||
| + | #O que é ''Hardware''? | ||
| + | #Fale sobre as três operações básicas realizados por um computador e o que cada uma delas faz. | ||
| + | #Complete a figura abaixo com as seis camadas de abstrações propostas por Tenenbaum, 1999.[[imagem: fig068_MI1022806.png|400px|center]] | ||
| + | #O que um ''Firmware''? | ||
| + | #O que é um ''Software''? | ||
| + | #Quais as principais etapas de um algoritmo para a obtenção de uma solução computacional? | ||
| + | #O que é linguagem de máquina? | ||
| + | #O modelo computacional idealizado por Von Neumann é baseado quais componentes principais? | ||
| + | #Qual aspecto mais importante do modelo de Von Neumann? | ||
| + | #Qual a principal diferença entre a arquitetura de Von Neumann e de Havard? | ||
| + | #Fale sobre o modelo de barramento de sistema. | ||
| + | #O que é um sinal de ''clock''? | ||
| + | #Como é composto um sistema de computador típico? | ||
| − | + | ===Parte 2=== | |
| − | == | + | #A que é a CPU e pelo que é responsável? |
| + | #O que é uma instrução? | ||
| + | #Qual é um formato típico de uma instrução de 8 bits? | ||
| + | #O que é mnemónico? | ||
| + | #Por que a maioria dos programas são escritas em linguagens de alto nível ao contrário de linguagem de máquina? | ||
| + | #Como fica um programa depois de compilado? | ||
| + | #Quais são as etapas básicas de funcionamento de um microprocessador? | ||
| + | #Quais são os elementos de uma estrutura generalizada de um microprocessador? | ||
| + | #Para que serve a ULA? | ||
| + | #Para que serve a FPU? | ||
| + | #Para que servem os registradores e como são divididos? | ||
| + | #Para que serve o Acumulador? | ||
| + | #Para que serve o Registrador de flags? | ||
| + | #O que são PC e IR? | ||
| + | #O que são MBR e MAR? | ||
| + | #Para que serve o Stack Pointer (SP)? | ||
| + | #O significa LIFO? Explique. | ||
| + | #Como estão divididos os registrador do processador ARM7? | ||
| + | #Quantos registradores possuem o ATMega328P? | ||
| + | #Como funciona a UC? | ||
| + | #O que é ciclo de instrução? | ||
| + | #O que é "uma busca de dados"? | ||
| + | #Para que serve as interrupções? | ||
| + | #Sobre o desempenho de microprocessadores é correto dizer que depende somente do ''clock''? | ||
| + | #Qual a causa da CPU trabalhar com "rajadas longas" ou "rajadas curtas"? | ||
| + | #Suponha que queiramos executar uma instrução de máquina que soma três números que estão na memória e salve o resultado em outro endereço de memória<pre>int a=10, b=20, c=30, t; \\sendo a no endereço 100, b no 101, c no 102 e t no 104</pre>Coloque todas as etapas (PC, IR, MAR e MBR) para fazer t=a+b e depois t=t+c no mesmo programa. | ||
| + | #O que é um barramento? | ||
| + | #Como funciona o barramento de dados? | ||
| + | #Como funciona o barramento de endereços? | ||
| + | #Como funciona o barramento de controle? | ||
| + | #Cite os sinais típicos de controle? | ||
| + | #Qual a diferença entre um microcontrolador e um microcomputador? | ||
| − | + | ====Respostas==== | |
| − | + | {{collapse top|[26]}} | |
| + | <pre> | ||
| + | ;int a=10, b=20, c=30, t; \\sendo a no endereço 100, b no ;101, c no 102 e t no 104 | ||
| − | == | + | 200: M[104] = M[100] + M[101] |
| + | 201: M[104] = M[104] + M[103] | ||
| − | + | PC = 200; | |
| − | + | IR <- (M[104] = M[100] + M[101]) | |
| − | + | PC = PC + 1 | |
| − | + | MAR = 100 | |
| − | + | MBR <- 10 | |
| − | + | R1 = MBR | |
| − | + | MAR = 101 | |
| − | + | MBR <- 20 | |
| − | + | R2 = MBR | |
| − | + | R3 = R1 + R2 | |
| − | + | MAR = 104 | |
| − | + | MBR = R3 | |
| − | + | IR <- (M[104] = M[102] + M[104]) | |
| − | + | PC = PC + 1 | |
| − | + | MAR = 102 | |
| − | + | MBR <- 30 | |
| − | + | R1 = MBR | |
| − | + | MAR = 104 | |
| − | + | MBR <- 30 | |
| − | + | R2 = MBR | |
| − | + | R3 = R1 + R2 | |
| − | + | MAR = 104 | |
| − | + | MBR = R3 | |
| − | + | M[104] <- 60 | |
| − | = | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | [ | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | [ | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | [ | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | = | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | < | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | < | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | < | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | = | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | = | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | < | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
</pre> | </pre> | ||
| − | + | ;Código que faz isso na prática em ASM | |
| − | <pre | + | <pre> |
| − | + | ; Comecamos armazenando 4 valores na memoria | |
| − | + | ; int a=10, b=20, c=30, t; \\sendo a no endereço 100, b no ;104, c no 108 e t no 10C | |
| − | + | ||
| + | |||
| + | mov R0, #10 | ||
| + | mov R1, #0 | ||
| + | mov R2, #16 ; 4 valores (4 bytes cada valor 4x4=16) | ||
| + | mov R3, #0x100 ; endereço base | ||
| + | loop str R0, [R3,R1] | ||
| + | add R1, R1, #4 ; endereços têm que ser múltiplos de 4 | ||
| + | add R0, R0, #10 | ||
| + | cmp R1, R2 | ||
| + | blt loop | ||
| + | ;principal | ||
| + | |||
| + | ldr R4, [R3,#0] ; primeiro endereço a=10 em 0x100 | ||
| + | ldr R5, [R3,#4] ; b=20 em 0x104 | ||
| + | add R6, R4,R5 ; t=a+b | ||
| + | ldr R4, [R3,#8] ; c=30 em 0x108 | ||
| + | add R6, R6,R4 ; t=t+c | ||
| + | str R6, [R3,#12] ; t em 0x10C | ||
| + | |||
| + | fim | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
</pre> | </pre> | ||
| − | + | {{collapse bottom}} | |
| − | + | ===Parte 3=== | |
| − | |||
| − | |||
| − | |||
| − | |||
| + | #Converta o número 1488d: | ||
| + | ##base 2 | ||
| + | ##base 8 | ||
| + | ##base 16 | ||
| + | #Converta os números abaixo para base decimal: | ||
| + | ##A3BDh | ||
| + | ##110100101.101b | ||
| + | ##1683o | ||
| + | #Converta os números abaixo para binário com sinal e amplitude de 8bits: | ||
| + | ##-70d | ||
| + | ##70d | ||
| + | ##53h | ||
| + | ##232o | ||
| + | #Converta o número decimal (positivo) em negativo utilizando complemento de 1: | ||
| + | ##17d | ||
| + | ##34d | ||
| + | ##89d | ||
| + | ##112d | ||
| + | #Por que 0d=00000000b=11111111b em complemento de 1? | ||
| + | #Converta o número decimal (positivo) em negativo utilizando complemento de 2: | ||
| + | ##17d | ||
| + | ##34d | ||
| + | ##89d | ||
| + | ##127d | ||
| + | #Quais os números representados pelo complemento de 2 abaixo: | ||
| + | ##001101101b | ||
| + | ##111001010b | ||
| + | ##001111100b | ||
| + | ##101010101b | ||
| + | #Se os números abaixo fossem representados por notação de Excesso 128, quais seriam? | ||
| + | ##00110110b | ||
| + | ##11100101b | ||
| + | ##00111110b | ||
| + | ##10101010b | ||
| + | #O que é ''overflow''? Exemplifique. | ||
| + | #O que é ''carry''? Exemplifique. | ||
| + | #Explique como são representados os números reais em computadores? | ||
| + | #Explique o que acontece quando se rotaciona um número binário para esquerda ou para direita? | ||
| + | #Como é feita a notação de ponto flutuante? | ||
| + | #Seja o byte 11111101b determinar: | ||
| + | ##O bit de sinal | ||
| + | ##O expoente | ||
| + | ##A mantissa | ||
| + | ##Valor decimal (considerando notação de excesso para expoente e ponto fixo para mantissa) | ||
| + | #Seja o decimal 1,25d represente ele com notação de ponto flutuante de 8bits. | ||
| + | #Para que serve a normalização do ponto flutuante? | ||
| + | #O que é o bit escondido? | ||
| + | #Explique o cuidado de se definir o intervalo e precisão de valores representáveis. | ||
| + | #Qual o cuidado que o projetista de ''hardware''' tem que ter com ''Overflow'' e ''Underflow''? | ||
| + | #Converta os valores decimais abaixo para a notação IEEE 754, precisão simples: | ||
| + | ##2019.8125d | ||
| + | ##570.5625d | ||
| + | #Converta os valores ponto flutuante abaixo, notação IEEE 754 precisão simples, para base decimal: | ||
| + | ##1110 0001 1110 0001 0000 0000 0000 0000 | ||
| + | ##0010 1010 1001 0101 1000 0000 0000 0000 | ||
| − | + | ===Parte 4=== | |
| − | + | #Escreva um programa em ARM que implementa um loop com 20 iterações, incrementando uma variável do valor 0 a 19 e somando o valor 17, a cada iteração, ao valor inicial (=7) armazenado em R1. | |
| − | + | #Escreva o programa em ARM que implementa as operações lógicas (AND, OR, XOR, NXOR, NAND E NOR) entre dois valores, armazenados em R4 e R5. | |
| − | + | #Implemente um programa ARM que resolve a equação: Y = (A - B) / (C + D x E). Dica: armazene A em R0, B, em R1, C, em R2, D, em R3 e E, em R4. | |
| − | + | #Implemente um programa em ARM que lê e compara os valores armazenados em R1, R2 e R3 e devolve o maior dentre eles em R4, e o menor, em R5. | |
| − | + | #Implemente um programa em ARM que coloque em ordem crescente 10 valores da memória. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | ====Respostas==== | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | ''* Algumas respostas! | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | {{collapse top|Solução [1]}} | |
| − | + | <pre> | |
| − | + | ;PROGRAMA QUE IMPLEMENTA R1 = R1 + 5, 40 VEZES | |
| − | + | ; i.e., R1 = R1 x 200 | |
| − | + | ;******* | |
| − | + | mov r1, #7 ;valor inicial de R1 | |
| − | + | mov r2, #17 ;incremento de R1 | |
| − | + | mov r3, #20 ;numero de loops | |
| − | + | mov r4, #0 ;valor inicial do contador | |
| − | + | ;***INICIA LOOP *** | |
| − | + | loop add r1, r1, r2 ;r1 = r1 + r2 (7+17) | |
| − | + | add r4,r4, #1 ;r4 = r4 + 1 | |
| − | + | cmp r4,r3 ;r4 < r3? | |
| − | + | blt loop ; se for menor pula pro loop | |
| − | + | fim | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
</pre> | </pre> | ||
| − | + | {{collapse bottom}} | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
----- | ----- | ||
Edição atual tal como às 14h50min de 25 de maio de 2021
Lista de Exercícios para (AT1)
- Nota
- Nossa primeira avaliação será dia 29/06/2021 conforme previsto. Esta lista de exercícios servirá de guia de estudos para vocês, não vou corrigi-la e também vocês não precisarão entregá-la mas vou tirar todas as dúvidas de vocês via grupo do Whatsapp.
Questões
Parte1
- Por que estudar microprocessadores?
- O que é um microprocessador?
- Disserte sobre o que significa, quando começou e quando terminou a chamada "lei de Moore".
- Explique o que significa single-core e multi-core em se tratando arquitetura de microprocessadores.
- O que você entende por um computador?
- Quais os principais tipos de computador?
- O que é um Cluster e como funciona?
- O que são e para que servem os Mainframes?
- O que difere um computador Desktop para um Supercomputador?
- No que se difere os "ditos" sistemas embarcados microcontrolados dos outros tipos de computadores?
- Cite 5 dispositivos eletrônico que você conheça que possuam Sistemas Embarcados?
- O que é RFID?
- Complete o desenho abaixo no que se refere a arquitetura e organização de um computador.
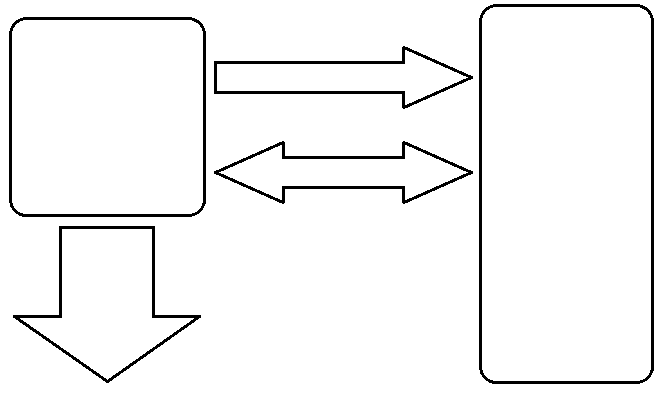
- O que é memória cache?
- O que é Hardware?
- Fale sobre as três operações básicas realizados por um computador e o que cada uma delas faz.
- Complete a figura abaixo com as seis camadas de abstrações propostas por Tenenbaum, 1999.
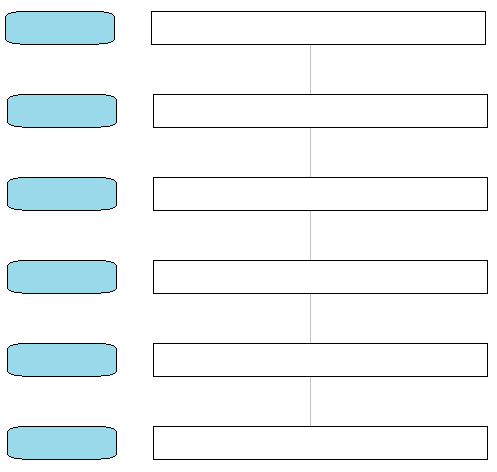
- O que um Firmware?
- O que é um Software?
- Quais as principais etapas de um algoritmo para a obtenção de uma solução computacional?
- O que é linguagem de máquina?
- O modelo computacional idealizado por Von Neumann é baseado quais componentes principais?
- Qual aspecto mais importante do modelo de Von Neumann?
- Qual a principal diferença entre a arquitetura de Von Neumann e de Havard?
- Fale sobre o modelo de barramento de sistema.
- O que é um sinal de clock?
- Como é composto um sistema de computador típico?


Parte 2
- A que é a CPU e pelo que é responsável?
- O que é uma instrução?
- Qual é um formato típico de uma instrução de 8 bits?
- O que é mnemónico?
- Por que a maioria dos programas são escritas em linguagens de alto nível ao contrário de linguagem de máquina?
- Como fica um programa depois de compilado?
- Quais são as etapas básicas de funcionamento de um microprocessador?
- Quais são os elementos de uma estrutura generalizada de um microprocessador?
- Para que serve a ULA?
- Para que serve a FPU?
- Para que servem os registradores e como são divididos?
- Para que serve o Acumulador?
- Para que serve o Registrador de flags?
- O que são PC e IR?
- O que são MBR e MAR?
- Para que serve o Stack Pointer (SP)?
- O significa LIFO? Explique.
- Como estão divididos os registrador do processador ARM7?
- Quantos registradores possuem o ATMega328P?
- Como funciona a UC?
- O que é ciclo de instrução?
- O que é "uma busca de dados"?
- Para que serve as interrupções?
- Sobre o desempenho de microprocessadores é correto dizer que depende somente do clock?
- Qual a causa da CPU trabalhar com "rajadas longas" ou "rajadas curtas"?
- Suponha que queiramos executar uma instrução de máquina que soma três números que estão na memória e salve o resultado em outro endereço de memória
int a=10, b=20, c=30, t; \\sendo a no endereço 100, b no 101, c no 102 e t no 104
Coloque todas as etapas (PC, IR, MAR e MBR) para fazer t=a+b e depois t=t+c no mesmo programa. - O que é um barramento?
- Como funciona o barramento de dados?
- Como funciona o barramento de endereços?
- Como funciona o barramento de controle?
- Cite os sinais típicos de controle?
- Qual a diferença entre um microcontrolador e um microcomputador?
Respostas
| [26] |
|---|
;int a=10, b=20, c=30, t; \\sendo a no endereço 100, b no ;101, c no 102 e t no 104 200: M[104] = M[100] + M[101] 201: M[104] = M[104] + M[103] PC = 200; IR <- (M[104] = M[100] + M[101]) PC = PC + 1 MAR = 100 MBR <- 10 R1 = MBR MAR = 101 MBR <- 20 R2 = MBR R3 = R1 + R2 MAR = 104 MBR = R3 IR <- (M[104] = M[102] + M[104]) PC = PC + 1 MAR = 102 MBR <- 30 R1 = MBR MAR = 104 MBR <- 30 R2 = MBR R3 = R1 + R2 MAR = 104 MBR = R3 M[104] <- 60
; Comecamos armazenando 4 valores na memoria ; int a=10, b=20, c=30, t; \\sendo a no endereço 100, b no ;104, c no 108 e t no 10C mov R0, #10 mov R1, #0 mov R2, #16 ; 4 valores (4 bytes cada valor 4x4=16) mov R3, #0x100 ; endereço base loop str R0, [R3,R1] add R1, R1, #4 ; endereços têm que ser múltiplos de 4 add R0, R0, #10 cmp R1, R2 blt loop ;principal ldr R4, [R3,#0] ; primeiro endereço a=10 em 0x100 ldr R5, [R3,#4] ; b=20 em 0x104 add R6, R4,R5 ; t=a+b ldr R4, [R3,#8] ; c=30 em 0x108 add R6, R6,R4 ; t=t+c str R6, [R3,#12] ; t em 0x10C fim |
Parte 3
- Converta o número 1488d:
- base 2
- base 8
- base 16
- Converta os números abaixo para base decimal:
- A3BDh
- 110100101.101b
- 1683o
- Converta os números abaixo para binário com sinal e amplitude de 8bits:
- -70d
- 70d
- 53h
- 232o
- Converta o número decimal (positivo) em negativo utilizando complemento de 1:
- 17d
- 34d
- 89d
- 112d
- Por que 0d=00000000b=11111111b em complemento de 1?
- Converta o número decimal (positivo) em negativo utilizando complemento de 2:
- 17d
- 34d
- 89d
- 127d
- Quais os números representados pelo complemento de 2 abaixo:
- 001101101b
- 111001010b
- 001111100b
- 101010101b
- Se os números abaixo fossem representados por notação de Excesso 128, quais seriam?
- 00110110b
- 11100101b
- 00111110b
- 10101010b
- O que é overflow? Exemplifique.
- O que é carry? Exemplifique.
- Explique como são representados os números reais em computadores?
- Explique o que acontece quando se rotaciona um número binário para esquerda ou para direita?
- Como é feita a notação de ponto flutuante?
- Seja o byte 11111101b determinar:
- O bit de sinal
- O expoente
- A mantissa
- Valor decimal (considerando notação de excesso para expoente e ponto fixo para mantissa)
- Seja o decimal 1,25d represente ele com notação de ponto flutuante de 8bits.
- Para que serve a normalização do ponto flutuante?
- O que é o bit escondido?
- Explique o cuidado de se definir o intervalo e precisão de valores representáveis.
- Qual o cuidado que o projetista de hardware' tem que ter com Overflow e Underflow?
- Converta os valores decimais abaixo para a notação IEEE 754, precisão simples:
- 2019.8125d
- 570.5625d
- Converta os valores ponto flutuante abaixo, notação IEEE 754 precisão simples, para base decimal:
- 1110 0001 1110 0001 0000 0000 0000 0000
- 0010 1010 1001 0101 1000 0000 0000 0000
Parte 4
- Escreva um programa em ARM que implementa um loop com 20 iterações, incrementando uma variável do valor 0 a 19 e somando o valor 17, a cada iteração, ao valor inicial (=7) armazenado em R1.
- Escreva o programa em ARM que implementa as operações lógicas (AND, OR, XOR, NXOR, NAND E NOR) entre dois valores, armazenados em R4 e R5.
- Implemente um programa ARM que resolve a equação: Y = (A - B) / (C + D x E). Dica: armazene A em R0, B, em R1, C, em R2, D, em R3 e E, em R4.
- Implemente um programa em ARM que lê e compara os valores armazenados em R1, R2 e R3 e devolve o maior dentre eles em R4, e o menor, em R5.
- Implemente um programa em ARM que coloque em ordem crescente 10 valores da memória.
Respostas
* Algumas respostas!
| Solução [1] |
|---|
;PROGRAMA QUE IMPLEMENTA R1 = R1 + 5, 40 VEZES ; i.e., R1 = R1 x 200 ;******* mov r1, #7 ;valor inicial de R1 mov r2, #17 ;incremento de R1 mov r3, #20 ;numero de loops mov r4, #0 ;valor inicial do contador ;***INICIA LOOP *** loop add r1, r1, r2 ;r1 = r1 + r2 (7+17) add r4,r4, #1 ;r4 = r4 + 1 cmp r4,r3 ;r4 < r3? blt loop ; se for menor pula pro loop fim |
![]()
![]()
![]()