Mudanças entre as edições de "SOP29005-2019-1"
| (30 revisões intermediárias por 2 usuários não estão sendo mostradas) | |||
| Linha 33: | Linha 33: | ||
* [http://wiki.inf.ufpr.br/maziero/doku.php?id=so:livro_de_sistemas_operacionais Livro do Prof.Maziero] | * [http://wiki.inf.ufpr.br/maziero/doku.php?id=so:livro_de_sistemas_operacionais Livro do Prof.Maziero] | ||
* [http://deptinfo.unice.fr/~rr/l3systres/ Université Nice Sophia Antipolis] | * [http://deptinfo.unice.fr/~rr/l3systres/ Université Nice Sophia Antipolis] | ||
| + | |||
| + | Arliones: | ||
| + | |||
| + | *[https://www.dropbox.com/s/dt80g3tml65rpmg/SOP29005-parte6.odp?dl=0] | ||
| + | *[https://www.dropbox.com/s/7lneavq0go9kz2t/SOP29005-parte7.odp?dl=0] | ||
===Leitura Recomendada=== | ===Leitura Recomendada=== | ||
| Linha 1 160: | Linha 1 165: | ||
O exemplo abaixo é de caráter puramente didático. 4 tarefas são criadas: | O exemplo abaixo é de caráter puramente didático. 4 tarefas são criadas: | ||
| − | *uma tarefa para piscar periodicamente o LED built-in do Arduino | + | *uma tarefa para piscar periodicamente o LED built-in do Arduino UNO; |
*Uma tarefa que conta interrupções INT0 e mostra a contagem; | *Uma tarefa que conta interrupções INT0 e mostra a contagem; | ||
*Uma tarefa que faz leitura da interface serial usando uma abordagem espera ocupada e sinaliza | *Uma tarefa que faz leitura da interface serial usando uma abordagem espera ocupada e sinaliza | ||
| Linha 1 513: | Linha 1 518: | ||
**Substituição de Páginas | **Substituição de Páginas | ||
| − | ==Exercícios para guiar o estudo== | + | ==Exercícios para guiar o estudo do Cap.9 - Memória Virtual == |
| − | #Descreva as etapas da rotina de serviço de erros de páginas | + | #Explique o que é um serviço de páginas por demanda e o que é um erro de falta de falta ("page fault"). |
| + | #Considere que um acesso a memória física sem erro de página leva 100ns e com erro de página é 10ms. Qual o tempo médio de acesso (tempo de acesso efetivo) considerando uma probabilidade de erro de acesso de 0.01? | ||
| + | #Descreva as etapas da rotina de serviço de erros de páginas considerando a substituição de páginas. (lembrar da Figura 9.6 do Silberchatz) | ||
#O que é um "quadro vítima" do ponto de vista de um algoritmo de substituição de páginas? | #O que é um "quadro vítima" do ponto de vista de um algoritmo de substituição de páginas? | ||
| − | #Quantos acesso a memória de | + | #Quantos acesso a memória de retaguarda seriam necessárias no caso de não existir mais quadros livres na substituição de páginas? |
| − | # | + | #Explique como é usado o "dirty bit" (bit de modificação) no contexto de substituição de páginas? |
| − | + | #Explique por que usando a paginação sob demanda pode-se fazer com que o processo tenha espaço de endereçamento muito maior que a memória fśicia? | |
| − | # | + | #Para se ter a paginação sob demanda deve-se resolver dois problemas através dos seguintes algoritmos: substituição de páginas e alocação de quadros. Explique brevemente do que tratam estes algoritmos. |
| + | #Como avaliamos quão bom é um algoritmo de substituição de páginas? Descreva brevemente o procedimento citando "sequência de referência". | ||
| + | #Elabore um exemplo do funcionamento do algoritmo de substituição de páginas FIFO considerando 3 blocos ("frames" de memória física) para a sequência de referência: 0 0 1 1 7 2 7 6 5 4 2 3 1 3 5 6 | ||
| + | #Explique o que é a anomalia de Belady. | ||
| + | #Elabore um exemplo do funcionamento do algoritmo ÓTIMO de substituição de páginas considerando 3 blocos ("frames" de memória física) para a sequência de referência: 0 0 1 1 7 2 7 6 5 4 2 3 1 3 5 6 | ||
| + | #O algoritmo ÓTIMO de substituição de páginas pode ser implementado na prática? Explique. | ||
| + | #Elabore um exemplo do funcionamento do algoritmo substituição de páginas LRU considerando 3 blocos ("frames" de memória física) para a sequência de referência: 0 0 1 1 7 2 7 6 5 4 2 3 1 3 5 6 Qual a similaridade deste algoritmo com o algoritmo ótimo? | ||
| + | #Existem algoritmos de substituição de página por aproximação ao LRU. Cite e explique brevemente 3 destas variações. | ||
| + | #Descreva brevemente o princípio de funcionamento dos algoritmos de substituição de páginas LFU e MFU | ||
| + | #Descreva como funciona o algoritmo de alocação de quadros proporcional. | ||
| + | #Qual a diferença entre alocação Global versus alocação Local de Quadros. | ||
<syntaxhighlight lang=cpp> | <syntaxhighlight lang=cpp> | ||
| Linha 1 584: | Linha 1 601: | ||
</syntaxhighlight> | </syntaxhighlight> | ||
| + | |||
| + | =AULA 34 - Dia 14/06/2019= | ||
| + | |||
| + | *Interface de Sistema de Arquivos (cap.12) | ||
| + | |||
| + | =AULA 35 - Dia 19/06/2019= | ||
| + | |||
| + | ==Objetivos== | ||
| + | |||
| + | *Implementação de Sistemas de Arquivos (cap.12) | ||
| + | |||
| + | =AULA 36 - Dia 26/06/2019= | ||
| + | |||
| + | ==Objetivos== | ||
| + | |||
| + | *Subsistema IO: cap.13 | ||
| + | |||
| + | =AULA 37 - Dia 28/06/2019= | ||
| + | |||
| + | ==Objetivos== | ||
| + | |||
| + | *Finalização de Subsistema IO: cap.13 | ||
| + | *Preparação para avaliação | ||
| + | |||
| + | ==Principais pontos para Estudo para Avaliação II== | ||
| + | |||
| + | *Cap.8 | ||
| + | **Seções de 8.1 (menos 8.1.4 e 8.1.5) a 8.4 - Seção 8.6 - Segmentação | ||
| + | *Cap.9 | ||
| + | **Seções 9.1, 9.2.1(introdução também), 9.3 , 9.4.1 (introdução também),9.4.2 e 9.5.1 (introdução também) | ||
| + | *cap.10 | ||
| + | **Seções 10.1 E 10.3 | ||
| + | *cap.11 | ||
| + | **Seções 11.1 e 11.2 | ||
| + | **Caso de estudo da implementação no Unix (figura Slide do Arliones) | ||
| + | *Cap.12 | ||
| + | **Seção 12.1.1 | ||
| + | *Cap.13 | ||
| + | **Seção 13.1 (+Fig.13.6) E 13.5 | ||
| + | |||
| + | ==Explanação sobre montagem de sistemas de arquivos e relação com devide drivers === | ||
| + | |||
| + | [[arquivo:SOP2019-1-ExemploMontagemSistema.png]] | ||
| + | |||
| + | |||
| + | Abrir um terminal e conferir: | ||
| + | |||
| + | df -h | ||
| + | |||
| + | =AULA 38 - Dia 3/07/2019= | ||
| + | |||
| + | *Segunda avaliação | ||
| + | |||
| + | =AULA 39 - Dia 5/07/2019= | ||
| + | |||
| + | *Apresentação Individual dos Projetos | ||
| + | |||
| + | =AULA 40 - Dia 10/07/2019= | ||
| + | |||
| + | *Recuperação Final | ||
| + | *Pontos para Recuperação | ||
| + | |||
| + | ==Pontos para Recuperação== | ||
| + | |||
| + | *Cap.2 (introdução) | ||
| + | **2.1 | ||
| + | **2.3, 2.4 | ||
| + | **2.7.1 (e introdução do 2.7) | ||
| + | *Cap.3 (introdução) | ||
| + | **3.1, 3.2,3.3,3.4 | ||
| + | *Cap.4 (introdução) | ||
| + | **4.1, 4.3.1 (também introdução) | ||
| + | *Cap.5 (introdução) | ||
| + | **5.1,5.2,5.3 (menos o 5.3.2) | ||
| + | *Cap.6 (introdução) | ||
| + | **6.1,6.2,6.3,6.5 e 6.6 | ||
| + | *Cap.7 (introdução) | ||
| + | **7.1 | ||
| + | *Cap.8 | ||
| + | **Seções de 8.1 (menos 8.1.4 e 8.1.5) a 8.4 - Seção 8.6 - Segmentação | ||
| + | *Cap.9 | ||
| + | **Seções 9.1, 9.2.1(introdução também), 9.3 , 9.4.1 (introdução também),9.4.2 e 9.5.1 (introdução também) | ||
| + | *cap.10 | ||
| + | **Seções 10.1 E 10.3 | ||
| + | *cap.11 | ||
| + | **Seções 11.1 e 11.2 | ||
| + | **Caso de estudo da implementação no Unix (figura Slide do Arliones) | ||
| + | *Cap.12 | ||
| + | **Seção 12.1.1 | ||
| + | *Cap.13 | ||
| + | **Seção 13.1 (+Fig.13.6) E 13.5 | ||
| + | |||
| + | =APOIO AO PROJETO= | ||
| + | |||
| + | ==ETAPA 3.1 - Transmissão de Byte== | ||
<syntaxhighlight lang=cpp> | <syntaxhighlight lang=cpp> | ||
| Linha 1 689: | Linha 1 801: | ||
MTX.enviar_byte(0xFA); | MTX.enviar_byte(0xFA); | ||
Serial.println("TaskSender: aguardando"); | Serial.println("TaskSender: aguardando"); | ||
| − | while(MTX.getStatus()==false); | + | while(MTX.getStatus()==false); // ATENÇÂO: Esta espera OCUPADA deve ser revista. Usar um mecanismo tipo um semáforo para avisar o fim da serialização. Substituir getStatus (e o qhile) por WaitFIM()... |
Serial.println("TaskSender: MTX liberado"); | Serial.println("TaskSender: MTX liberado"); | ||
} | } | ||
| Linha 1 698: | Linha 1 810: | ||
} | } | ||
</syntaxhighlight> | </syntaxhighlight> | ||
| + | |||
| + | ==ETAPA 3.2 - Arquitetura do Nodo== | ||
| + | |||
| + | |||
| + | [[Arquivo:SOP-2019-1-ArquiteturaNodo.png]] | ||
| + | |||
| + | Vamos assumir que o quadro será transmitido em modo texto (segundo a tabela ASCII). Deve-se portanto fazer algumas mudanças para evitar | ||
| + | que alguns bytes do quadro sejam interpretados erroneamente | ||
| + | |||
| + | *MAC das Equipes | ||
| + | **EQ 1 - B1001 | ||
| + | **EQ 2 - B1010 | ||
| + | **EQ 3 - B1011 | ||
| + | **EQ 4 - B1100 | ||
| + | **EQ 5 - B1101 | ||
| + | **EQ 6 - B1110 | ||
| + | **EQ 7 - B1111 | ||
| + | |||
| + | *ID das Portas | ||
| + | Sempre começar em 1 | ||
| + | |||
| + | Resta ainda um problema que seria o BCC que pode resultar em qualquer valor. Para evitar confundir com STX ou ETX fazer um OU com B10000000 no resultado final. | ||
| + | A ideia é colocar sempre um bit a 1 na posição mais significativa. | ||
| + | |||
| + | *SUGESTÃO DE ESTRUTURA DA TaskSender | ||
| + | |||
| + | A Task Emissora deve aguardar por informação em um Set de Filas do RTOS composto por TxQueue e FwQueue. | ||
| + | |||
| + | <syntaxhighlight lang=cpp> | ||
| + | TaskEmissora() | ||
| + | { | ||
| + | for (;;) { | ||
| + | Espera no Set de Queues | ||
| + | Se Dados na Tx Queue | ||
| + | Montar Quadro com dado da TxQueue | ||
| + | Enviar Quadro | ||
| + | Se Dados na FwQueue | ||
| + | Enviar quadro do topo da FwQueue | ||
| + | Fim-Se | ||
| + | } | ||
| + | } | ||
| + | </syntaxhighlight> | ||
| + | |||
| + | Como os quadros são de tamanho fixo, a transmissão de quadro deve ser trivial: para enviando cada byte... | ||
=Conteúdo= | =Conteúdo= | ||
Edição atual tal como às 11h24min de 20 de setembro de 2019
- Professor: Eraldo Silveira e Silva
- Atendimento paralelo: .
- Plano de Ensino: ver SIGAA ou
- Plano de ensino
- Cronograma: ver SIGAA
Diário de Aulas
AULA 1 - Dia 13/02/2019
Objetivos/Conteúdos
- Apresentação do Plano de Ensino
- Objetivos e Conteúdo Programático da Disciplina (ver SIGAA)
- Forma de Avaliação (ver SIGAA)
- Introdução a Sistemas Operacionais (Cap1. do Silberschatz)
- O que faz um sistema operacional (1.1)
- Organização e Arquitetura de um Sistema Computacional (1.2 e 1.3)
- Importância da Interrupção e Timers (1.2.1)
- Estrutura de Armazenamento (1.2.2)
- Estrutura de IO (1.2.3)
- Estrutura e Operações de um Sistema Operacional (1.4 e 1.5)
Material de Referência
- Apresentação sobre histórico visão geral e estruturas básicas de um SO
- Slides Silberschatz Oitava Edição
- Tradução Slides Silberschatz
- Livro do Prof.Maziero
- Université Nice Sophia Antipolis
Arliones:
Leitura Recomendada
- Cap.1 do Silberschatz principalmente:
- 1.1 a 1.9
Exercícios Práticos de Apoio a Aula
Na sequência. com fins motivacionais, são apresentados alguns exercícios ilustrando conceitos de processos, arquivos e permissionamento.
-
Comando para ver todos os processos no linux:
$ ps aux </syntaxhighlight> -
Colocar 2 processos se executando no contexto de um terminal e verificar número dos processos e então "destruí-los":
$ yes > /dev/null $ yes > /dev/null $ ps $ kill -9 <pid_yes> $ kill -9 <pid_yes> </syntaxhighlight> Observe que dois processos foram criados a partir do programa "yes". Os processos associados ao terminal são visualizados e então destruídos. Tente destruir também o interpretador de comando (shell) associado ao terminal. -
Criar um terminal adicional
$ xterm </syntaxhighlight> Ir no terminal criado e listar os processos que se executam associados a este terminal. Verificar qual o dispositivo de entrada e saída associado a ele. Voltar ao terminal original e enviar uma mensagem. Destruir o terminal criado:$ echo Alo Terminal > /dev/pts/2 $ kill -9 <pid_terminal> </syntaxhighlight> -
Comunicação entre processos:
$ cat /etc/passwd | grep home | wc -l </syntaxhighlight> -
Retirando a permissão de leitura de um arquivo em nível de usuário proprietário:
$ echo Alo Mundo > alfa.txt $ ls -l alfa.txt $ cat alfa.txt $ chmod u-r alfa.txt $ cat alfa.txt $ chmod u+r alfa.txt $ cat alfa.txt </syntaxhighlight>
AULA 2 - Dia 15/02/2019
- continuação
AULA 3 - Dia 20/02/2019
Objetivos/Conteúdos
- Estruturas do Sistema Operacional (cap.2)
- Serviços do Sistema Operacional (2.1)
- Interfaces com Usuários (2.2)
- Chamadas do Sistema (2.3)
- Tipos de Chamadas de Sistema (2.4) ver Fig.2.8
- Chamadas de Controle de Processos
- Arquiteturas e Estruturas de Sistemas Operacionais (2.7)
- Máquinas Virtuais (2.8)
Material de Referência
- [http://docente.ifsc.edu.br/arliones.hoeller/sop/slides/SOP29005-parte1.pdf Apresentação sobre histórico visão geral
- [3]
Leitura Recomendada
- Cap.2 do Silberschatz principalmente:
- 2.1 a 2.8
Exercícios
- Estudar e executar o código em http://cs.lmu.edu/~ray/notes/gasexamples/
Detalhes das chamadas na arquitetura x86_64 ver em https://lwn.net/Articles/604287/
- Estudar e executar o código usando a função (em conformidade com a API POSIX) write() para o hello world:
- include <unistd.h>
main()
{
write(1,"Alo Mundo\n",10);
}
</syntaxhighlight>
- Use o comando strace para verificar todas as chamadas de sistema dos programas acima.
-
DESAFIO 1: Estude a seção "Mixing C and Assembly Language" da http://cs.lmu.edu/~ray/notes/gasexamples/ e construa uma função meu_hello_world() usando o código em assembly do exercício inicial. Estude como poderia disponibilizar esta e outras funções de interface (a sua API) em uma biblioteca. Note que esta função deve ser chamada da forma:
main()
{
meu_hello_world();
}
</syntaxhighlight>
Gere o assembly do código em C e discuta a diferença entre uma chamada de função e uma chamada de sistema.
-
DESAFIO 2: Estude o link http://blog.rchapman.org/posts/Linux_System_Call_Table_for_x86_64/ e melhore a função meu_hello_world para suportar uma mensagem adicional da forma:
- include <string.h>
main()
{
char *p="Tudo bem com vocês?";
meu_hello_world(p, strlen(p));
}
</syntaxhighlight>
Solução:
Solução
modificado de http://cs.lmu.edu/~ray/notes/gasexamples/
.global meu_hello_world
.text
meu_hello_world:
push %rdi # salva primeiro parâmetro
push %rsi # salva segundo parâmetro
mov $1, %rax # system call 1 é write
mov $1, %rdi # file handle 1 é stdout
mov $message, %rsi # endereço da string
mov $13, %rdx # número de bytes da string
syscall # chamada ao sistema
pop %rdx # o que havia sido passado em rsi (número de bytes) é colocado em rdx
pop %rsi # o que havia sido colocado em rdi (endereço da string) é colocado em rsi
mov $1, %rax # system call 1 is write
mov $1, %rdi # file handle 1 é stdout
syscall # nova chamada ao sistema
ret
message:
.ascii "Hello, World\n"
</syntaxhighlight>
AULA 4 - Dia 22/02/2019
Objetivos/Conteúdos
- Gerenciamento de Processos
- Conceito de Processo (3.1)
- O processo (3.1.1)
- Estado do Processo (3.1.2)
- Bloco de Controle de Processo (3.1.3)
- Threads (3.1.4)
- Scheduling (3.2)
- Filas de Scheduling (3.2.1)
- Schedulers
- Mudança de Contexto (3.2.3)
- Operações Sobre Processos (3.3)
Slides desta aula
- Apresentação sobre Gerenciamento de Processos
- Capítulo 3 do livro do Silberschatz
Laboratório em Sala
https://wiki.sj.ifsc.edu.br/index.php/SOP29005-2019-1#Processos_no_Linux_-_Modificado_por_Eraldo
Exercícios de Demonstração
- Executar em um terminal o comando top. Em um outro terminal executar:
yes > /dev/null &
yes > /dev/null &
- Parar um dos processos yes
kill -STOP <pid_yes>
- Continuar o processo
kill -CONT <pid_yes>
- Destruir todos
killall yes
AULA 5 - Dia 26/02/2019
Objetivos/Conteúdos
- Revisão de Processos
- Finalização de exercício: exec (Laboratório de Processos)
- Comunicação entre processos (3.4, 3.4.1 e 3.5.1)
- Memória compartilhada (slides 18 a 21)
- Laboratório memória compartilhada
Comunicação entre Processos
- Apresentação sobre Comunicação entre Processos
- Capítulo 3 do livro do Silberschatz.
AULA 6 - Dia 1/03/2019
Objetivos/Conteúdos
- Comunicação entre processos (3.4, 3.4.1 e 3.5.1)
- Revisão de Memória compartilhada (slides 18 a 21)
- Mais uma exercício
- Comunicação com Transmissão de Mensagens (3.4.2)
- Comunicação com Pipes (3.6.3.1)
- Exercício Pipes
- Comunicação com Pipes Nomeados (3.6.3.2)
AULA 7 - Dia 8/03/2019
Objetivos/Conteúdos
- Finalização do Cap.3 - Questionário de Revisão
Questionário - Processos
- Conceitue processo. Descreva e explique cada uma das seções de um processo na memória.
- Faça um diagrama e explique os possíveis estados de um processo no sistema. O que produz a transição entre estados?
- O que é um Bloco de Controle de Processo? Quais informações ficam armazenadas neste bloco?
- Faça um diagrama mostrando a alternância entre dois processos na CPU. Indique o procedimento de salvamento e restauração do estado do PCB.
- Explique o que é multiprogramação e escalonamento de processos.
- O que é a fila de processos prontos?
- Diferencie um processo limitado por IO de um processo limitado por CPU.
- Diferencie escalonamento de longo prazo de escalonamento de curto prazo.
- Discuta o papel da interrupção na troca de contexto entre processos.
- Explique como é o processo de criação de novos processos no UNIX/Linux através da chamada fork. O que acontece com a memória do novo processo?
- Explique como funciona a chamada exec no UNIX/Linux
- Explique como funciona a chamada wait no UNIX/Linux e como é possível retornar valores de um filho para o pai.
- Faça um esqueleto de um programa UNIX/Linux que ao se tornar processo cria 3 filhos e espera pela execução dos mesmos.
Questionário - Comunicação entre Processos
- Diferenciar processos independentes de processos cooperantes.
- Enumere e explique quatro razões para cooperação entre processos.
- A velocidade de processamento é uma das razões da cooperação entre processos. Discuta se um hardware com apenas uma CPU pode usufruir desta característica.
- Descreva os dois principais mecanismos de cooperação entre processos. Discuta a situação em que é possível usar a memória compartilhada e/ou a troca de mensagens.
- A memória compartilhada requer chamada ao sistema na sua operação? Discuta.
- Por que o processo de troca de mensagem deve ser mais lento que a memória compartilhada?
- Apresente em pseudocódigo uma proposta de funcionamento do problema do produtor consumidor usando memória compartilhada.
- A construção de uma solução para o problema produtor consumidor pode ser facilitado pelo uso da memória compartilhada? Discuta.
- Quais as duas operações básicas ma troca de mensagens? O que poderia motivar o uso de mensagens do tamanho fixo? Esta abordagem torna mais complexa a vida dos programadores?
- Enumere três métodos de implementação de uma lógica de ligação (link) entre processos.
- Explique o que é a comunicação direta em troca de mensagens. Descreva como são as duas primitivas de comunicação direta para esta abordagem e quais as 3 propriedades seguidas por esta comunicação.
- Descreva a variante assimétrica da troca direta de mensagens. O que muda em termos de primitiva de comunicação?
- Descreva o problema de hard-coding associado a nomeação direta e como pode ser contornado através da nomeação/comunicação indireta?
- O que é uma caixa postal? Como o Posix identifica uma caixa postal no caso de fila de mensagens?
- Dois processos podem usar mais do que uma caixa postal para se comunicar? Qual a condição para que isto ocorra?
- Descreva as duas operações básicas para a troca de mensagens com Caixa Postal.
- Descreva na comunicação indireta via Caixa Postal as 3 propriedades básicas.
- A questão do compartilhamento de caixas postais por múltiplos processos podem causar um problema na operação da recepção. Descreva quais as 3 possibilidades para contornar este problema.
- De que forma a caixa postal estando no espaço de endereçamento de um processo (propriedade) afeta a recepção por mensagens? Descreva.
- Quais as operações sobre uma caixa postal criada no espaço do sistema operacional deverão ser disponíveis? Descreva.
- A transmissão de mensagem pode ser com e sem bloqueio. Descreva as 4 possibilidades (síncrona/assíncrona).
- Discuta as 3 possibilidades de armazenamento de mensagens em buffer. Em que condições um remetente pode ser bloqueado?
AULA 8 - Dia 13/03/2019
Objetivos/Conteúdos
- Conceito de Threads (cap.4)
- Caracterização do contexto e chaveamento de contexto do thread
- Laboratório de Thread de Applicação
- Slides sobre Threads:
Laboratório Threads Aplicação
Ver https://wiki.sj.ifsc.edu.br/index.php/SOP29005-2019-1#Threads_de_aplica.C3.A7.C3.A3o
Slides para esta aula
- Apresentação sobre Gerenciamento de Processos
- Slides do Capítulo 4 do livro do Silberschatz
AULA 9 - Dia 15/03/2019
Objetivos/Conteúdos
- Caracterização do contexto e chaveamento de contexto do thread
- Laboratório: implementação de chaveamento de threads com apoio de sinais do linux.
Laboratório
AULA 10 - Dia 20/03/2019
Objetivos/Conteúdos
- escalnamento de processos (cap.5)
AULA 11 - Dia 22/03/2019
Objetivos/Conteúdos
- escalonamento de processos (cap.5)
- Implementação de um algoritmo de escalonamento round-robin (fazer em arquivo fonte separado)
- Definir um PCB (uma struct que reflita informações do thread: contexto, ID, data de criação)
- Implementar uma fila usando stl (ver https://www.geeksforgeeks.org/queuefront-queueback-c-stl/)
- Implementar as seguintes funções/:
- add_thread ( void (*thread_function)(void)) -> Cria um thread
- end_thread (); -> Termina um thread
- yield_thread(); -> Repassa o thread
Os threads devem ser declarados como uma função da forma:
void meu_thread(void)
{
}
AULA 12 - Dia 27/03/2019
Objetivos/Conteúdos
- Propor a finalização das funções de threads em nível usuário (apresentar a proposta inicial com stl).
- Revisar escalonamento colocando algumas perguntas chaves
- Finalizar o assunto de escalonamento apresetando escalonamento por prioridade;
Perguntas de Revisão sobre escalonamento
- Qual o papel do escalonador de curto prazo em um OS?
- Em um sistema de escalonamento NÃO preemptivo quais eventos fazem com que o escalonador atue no sentido de escolher novo processo para execução;
- Qual a diferença entre um escalonador de processos em um despachante de processos? Enumere o que o despachante deve fazer efetivamente.
- Enumere e explique os critérios (métricas) para avaliar algoritmos de escalonamento.
- Faça um gráfico de Grant mostrando como a ordem de chegada de processos impacta no tempo médio de espera pela CPU em um esquema de escalonamento FCFS (sem preempção).
AULA 13 - Dia 29/03/2019
Objetivos/Conteúdos
- Sincronização de Processos;
Desafio Inicial
Implemente o código abaixo no exemplo de threads desenvolvido em sala. Qual a saída presumida?
struct delta{
long alfa;
char epson[1000];
long beta;
} shar;
void runA(void) {
struct delta x = {0, 100};
for (;;) {
x.alfa=0;x.beta=0;
shar=x;
x.alfa=100;x.beta=100;
shar=x;
}
}
void runB(void) {
for (;;) {
printf("beta = %ld %ld \n",shar.alfa, shar.beta);
sleep(1);
}
}
</syntaxhighlight>
Desafio 2
Tente refazer o exercício anterior usando um procedimento de sincronização de processos.
/**
User-level threads example.
Orion Sky Lawlor, olawlor@acm.org, 2005/2/18 (Public Domain)
*/
#include <stdio.h>
#include <stdlib.h>
#include <ucontext.h> /* for makecontext/swapcontext routines */
#include <queue> /* C++ STL queue structure */
#include <vector>
#include<signal.h>
#include<unistd.h>
#include <ucontext.h>
#include <sys/time.h>
#define TIME_SLICE 1
typedef void (*threadFn)(void);
class thread_cb {
int id_thread;
public:
ucontext_t contexto;
thread_cb(threadFn p, int id)
{
getcontext(&contexto);
int stackLen=32*1024;
char *stack=new char[stackLen];
contexto.uc_stack.ss_sp=stack;
contexto.uc_stack.ss_size=stackLen;
contexto.uc_stack.ss_flags=0;
id_thread = id;
makecontext(&contexto,p,0);
};
ucontext_t *get_context() {
return &contexto;
};
};
std::queue<class thread_cb *> ready_pool;
int id_thread = 0;
class thread_cb *curr_thread=NULL;
void add_thread(threadFn func)
{
class thread_cb *p = new thread_cb(func, ++id_thread);
ready_pool.push(p);
}
void dispatcher(ucontext_t *old_task, ucontext_t *new_task)
{
if (old_task!=NULL)
swapcontext(old_task, new_task);
else
setcontext(new_task);
}
void scheduler_rr()
{
class thread_cb *next,*last;
if(curr_thread!=NULL) {
printf("Aqui\n");
ready_pool.push(curr_thread);
last=curr_thread;
next=ready_pool.front();
ready_pool.pop();
curr_thread=next;
dispatcher(last->get_context(), curr_thread->get_context());
} else {
next=ready_pool.front();
ready_pool.pop();
curr_thread = next;
dispatcher(NULL, next->get_context());
}
}
void sig_handler(int signo)
{
printf("SOP da Turma 2019-2: recebido SIGALRM\n");
alarm(TIME_SLICE);
if (ready_pool.empty()) {
printf("Nothing more to run!\n");
exit(0);
}
scheduler_rr();
}
void preparar_handler()
{
if (signal(SIGALRM, sig_handler) == SIG_ERR) {
printf("\nProblemas com SIGUSR1\n");
exit(-1);
}
alarm(TIME_SLICE);
}
struct delta{
long alfa;
char epson[1000];
long beta;
} shar;
int turn;
int flag[2];
#define TRUE 1
#define FALSE 0
void ent_rc(int p, int vt)
{
flag[p]=TRUE;
turn = vt;
if(p) p=0; else p=1;
while (flag[p] && turn == vt)
printf("Thread %d: esperando para acessar a região crítica\n", p);
}
void sai_rc(int p)
{
flag[p]=FALSE;
}
void runA(void) {
struct delta x = {0, 100};
for (;;) {
x.alfa=0;x.beta=0;
ent_rc(0,1);
shar=x; // regiao crítica
sai_rc(0);
x.alfa=100;x.beta=100;
ent_rc(0,1);
shar=x; // regiao crítica
sai_rc(0);
}
}
void runB(void) {
for (;;) {
ent_rc(1,0);
printf("shar alfa = %ld shar beta = %ld \n",shar.alfa, shar.beta); // regiao crítica
sai_rc(1);
sleep(1);
}
}
main()
{
add_thread(runA);
add_thread(runB);
preparar_handler();
for(;;);
}
AULA 14 - Dia 3/04/2019
Objetivos/Conteúdos
- Sincronização de Processos
AULA 15 - Dia 5/04/2019
Objetivos/Conteúdos
- Sincronização de Processos (slides Silberchatz cap.6)
- Laboratório de Pthreads e Semáforos (ver laboratório de programação concorrrente)
AULA 16 - Dia 10/04/2019
Objetivos
- Sincronização de Processos (slides Silberchatz cap.6)
- Revisão de Semáforos (rever a definição)
- Deadlock X Inanição (2 problemas diferentes) - cap.6.5.3
- A Inversão de Prioridades - cap. 6.5.4
- Problemas Clássicos de Sincronização
- O problema do Buffer Limitado - cap.6.6.1
- O problema dos Leitores/Gravadores - cap.6.6.2
- O problema do Almoço dos Filósofos - cap.6.6.3
- Monitores (cap.6.7)
- Almoço dos filósofos com monitores (6.7.2)
- Implementação dos Monitores com Semáforos (6.7.3)
Exercícios Adicionais
- Usando pthreads e semáforos fazer uma implementação do almoço dos filósofos conforme Fig.6.15 do Silberchatz. Verificar a condição de deadlock.
- Refazer a solução anterior acrescentando um semáforo iniciado com 4 para que somente no máximo 4 filósofos tentem acessar a "mesa" por vez.
- Implementar com o pthreads uma solução do problema leitores/gravador do cap.6.6.2. Criar um vetor de inteiros que em tempos randômicos entre 0 e 1s é atualizado inteiramente pelo gravador, de forma incremental: tudo 0, tudo 1 etc. Os leitores acessam a primeira e última posição do vetor, que deve sempre ser igual.
AULA 17 - Dia 12/04/2019
Objetivos
- Discutir projeto final. Dividir tarefas e grupos.
- Monitores: conceito
- Exercícios:
- Propor exercício aula passada. PAra o almoço dos filósofos fazer um contador de número de almoços em 1 segundo.
Projeto Final
Grupos=
- G1 -cap.2 - Guilherme e Roque e Lucas
- G2 - cap.3 - Amanda e Alexandro
- G3 - cap.4 - Osvaldo e MArcelo
- G4 - cap 5 - Camila e Jeneffer
- G5 - cap.6 - Sarom, Elisa e Tiago
- G6 - cap.7 - Guilherme Filipe e Eduarda
- G7 - CAp.8 e 9/
Meta ETAPA 1
- apresentação de 15 minutos com entrega de slides
- estar preparado para responder perguntas básicas
- Data: Dia 3 de maio
Previsão de 4 etapas: a etapa 2 deve ter uma parte prática.
Referências
- Site do FreeRTOS ver Mastering the FreeRTOS Real Time Kernel - a Hands On Tutorial Guide
- [5]
- [6]
Exercício
Implementação com deadlock
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <pthread.h>
#include <signal.h>
#include <semaphore.h>
#define NUM_FILOSOFOS 5
sem_t chop_stick[NUM_FILOSOFOS];
pthread_mutex_t mutex_cont;
int contador_jantar=0;
int filosofo(int n)
{
while (1) {
sem_wait(&chop_stick[n]);
sem_wait(&chop_stick[(n+1)%NUM_FILOSOFOS]);
//comendo
pthread_mutex_lock(&mutex_cont);
contador_jantar++;
pthread_mutex_unlock(&mutex_cont);
sem_post(&chop_stick[n]);
sem_post(&chop_stick[(n+1)%NUM_FILOSOFOS]);
}
}
int main()
{
pthread_t threads[NUM_FILOSOFOS];
int i,ret;
// Cria cinco threads que executarão a mesma função
for(i=0; i<NUM_FILOSOFOS; ++i){
sem_init(&chop_stick[i],0,1);
ret = pthread_create(&threads[i], NULL, (void*(*)(void*))filosofo,(void*)((long)i));
if(ret != 0){
printf("erro\n");
exit(EXIT_FAILURE);
}
}
// Aguarda o fim das threads
sleep(15);
printf ("valor do contador -parte 1 %d\n", contador_jantar);
sleep(15);
printf ("valor do contador -parte 2 %d\n", contador_jantar);
for(i=0; i<NUM_FILOSOFOS; ++i) {
//pthread_join(threads[i], NULL);
sem_destroy(&chop_stick[i]);
}
exit(0);
}
- Implementar a solução do almoço de filósofos com semáforo 4 (somente 4 entram na mesa) da aula passada. Fazer um contador de desemepenho (número de almoços em 1 segundo). Testar com semáforos de contagem 1, 2 e 3.
- Estudar e implementar a solução para almoço de filósofos apresentada em [7]
AULA 18 - Dia 17/04/2019
- Aula de exercícios
Lista de Exercício para Preparação da Prova 1
Questões relacionada a Estrutura de Sistemas Computacionais
-
Considere o seguinte código em um microcontrolador fictício em que cada instrução possui dois bytes e o endereço é mostrado a esquerda:
000B push A
0100 iret
A000 mov A,B
A002 mov R1,R0
A004 call B000h
B000 push A
B002 mov A, #1
B004 syscall
</syntaxhighlight>
Suponha que um processo está em execução e que a instrução mov A,B está sendo executada. O SP (stack pointer) aponta para a área de memória E000h neste momento. Considere que o sistema possui um OS PREEMPTÍVEL. Se ocorrer uma interrupção devido a um timer associado a um quantum de um OS exatamente durante a execução da instrução citada e considerando que o ponto de entrada da interrupção é 000B, pergunta-se:
(a) qual o valor do contador de programa neste momento? O que ele indica?
Solução
Se a instrução que está em execução está no endereço A000, a próxima instrução deve estar em A002. O valor do contador de programa deve estar configurado para este valor. Existe uma possibilidade deste contador de programa ser modificado pela instrução. É o caso do jump. Entretanto, não se aplicaria neste caso.
(b) o que deve acontecer com o contador de programa neste momento?
Solução
Se ocorrer uma interrupção durante a execução da instrução, possivelmente ela será atendida no final da mesma. O contador de programa será modificado para 000B de forma que a próxima instrução seja a entrada do handler de interrupção do timer. O valor do contador de programa antes de ser modificado será empurrado para pilha (movimentado para posição E000 e E001, sendo o stack pointer incrementado em 2). Desta forma poderá ser restabelecido após o retorno da interrupção.
(c) supondo que o OS, ao ser solicitado no handler, decide trocar o contexto para ativar um novo processo. Considere que o retorno do OS sempre é realizado pela instrução indicada no endereço 0100. Como a pilha deveria estar neste momento?
Solução
Sendo um OS com preempção, e tendo escolhido um novo processo, cabe a ele salvar todo o contexto do processo atual em um bloco de controle do processo. O OS deve reestabelecer cuidadosamente todo o contexto do novo processo. Como o retorno para o novo processo será feito pelo iret, então a pilha deve ser cuidadosamente preparada com o endereço do contador de programa do novo processo, de forma que quando for executado o iret, o processo continue a sua execução do ponto onde havia parado.
(d) qual o papel do quantum de tempo?
Solução
Em um sistema com multiprogramação o quantum define um período de tempo (slice) em que o OS tem a oportunidade de interromper o processo em execução e se for o caso chavear para um outro processo.
(e) caso ocorra uma interrupção devido a um dispositivo de I/O dentro ou fora do código do OS o que deve ocorrer? Poderá haver interferência na escolha de um novo processo?
Solução
En um sistema com preempção é possível que isto ocorra. Esta interrupção pode sinalizar a liberação de um recurso, tornando um processo elegível para escalonamento.
(f) Pode-se dizer que as chamadas ao sistema serão feitas sempre no mesmo endereço de entrada da interrupção do timer? Discuta.
Solução
São situações diferentes com pontos de entrada diferentes. Existe um ponto de entrada das chamadas de sistema (geradas por interrupção por software, por exemplo.
Ocorrem quando um processo chama o sistema operacional para que este preste algum serviço. Já a entrada do handler do timer é o ponto de atendimento desta interrupção. Neste caso para fazer com que o OS avalie a colocação de outro processo.
Questões relacionadas ao conceito e criação de threads e processos
-
Considere dois threads conforme abaixo.
char *p;
int x;
void thread1 ()
{
char *w;
int y;
w = malloc (10);
while (1) {
}
}
void thread2 ()
{
char z;
p = &z;
while (1) {
}
}
int main ()
{
// código de inicialização dos threads
}
Em que áreas (seções) da memória estão localizadas as variáveis x, p, z, w e y? Se o thread2 escrever em *p ele estará acessando qual área de memória?
Se o thread 1 escrever na área apontada por w ele estará escrevendo em qual área de memória?
Solução
Variável x e p: estão na área de DATA (dados globais vistos por todos os threads - mais especificamente na área BSS que são dados NÃO inicializados). Variávels w e y: estão na área de STACK do thread1. Variável z: está na área de STACK do thread2.
Se o thread2 esve na área apontada por p (ou seja *p), ele estará escrevendo no seu próprio STACK pois p aponta para z. Se o thread escreve na área apontada por w (ou seja *w) ele estará escrevendo na área de HEAP (dados dinâmicos do processo). Esta área é compratilhada por todos os processos. Notar que o malloc é thread safe, ou seja,, permite ser chamado por vários threads de forma concorrente.
-
Considere o código em um OS Unix (includes omitidos):
main()
{
int ret;
ret = fork();
// código omitido
}
Discuta o que acontece na chamada fork e quais as possibilidades de retorno em "ret"?
Solução
Existem 3 possibilidades: (i) retorna erro (-1) e neste caso não é criado nenhum processo. Nos dois casos seguintes correspondem a situação em que houve sucesso no fork e um processo filho foi criado commpartilhando o código do pai e com área de dados, pilha e heap separadas mas clonadas do pai. As possibilidades de retorno são: (ii) o fork retorna o PID do filho e neste caso o processo pai continua a sua execução normal sabendo este PID (se ele o armazenou) e (iii) é retornado 0 indicando que é o filho. Neste caso o filho continua a execução no mesmo ponto em que o estava o pai mas já dentro de seu novo espaço de dados.
-
Modifique o código do exercício anterior para que seja criada uma árvore com um pai, dois filhos e 3 processos "netos". Cada processo pai deve esperar por seus filhos.
Solução
main()
{
int ret;
ret = fork();
if (ret==-1) exit(1); // problema - encerra...
if (ret == 0) { // filho 1
for (i=0;i<3;i++) {// vou criar 3 filhos (os 3 netos solicitados) {
ret = fork();
if (ret==0) {
// o neto faz algo...
exit(0);
}
}
for (i=0;i<3;i++){ // sou o filho 1 esperando pelos meus filhos (netos)
wait(NULL);
}
} else { // pai
}
// código omitido
}
Questões relacionadas a threads, programação concorrente e sincronização de threads
-
Um sistema computacional possui uma CPU com 4 núcleos que podem ser usados para executar simultaneamente threads de um mesmo processo.
Elaborar um pseudocódigo (C-like) para computar a soma de um vetor de inteiros de tamanho 1024 (fornecido inicializado),
onde 4 threads dividem a tarefa na soma de partes destes vetores. Mais especificamente: o thread 1 soma itens de 0 a 253, o thread
2 de 254 a 511, o thread 3 de 512 a 767 e por fim, o thread 4 soma os utens de 768 a 1023. Cada thread acessa uma variável global soma_ac
que acumula o resultado da soma. No final, o thread associado ao programam principal
espera pela execução destes threads e apresenta o resultado final (sem realizar nenhuma soma). Faça um pseudocódigo baseado na biblioteca pthreads para resolver este problema. Use mutex ou semáforos
se necessário. Se existir uma região crítica deixe-a indicada em comentário.
-
Observe o algoritmo simples para cálculo da variância de uma população apresentado em [8]. Pode-se observar que se poderia fazer dois loops separados e paralelos (2 threads) para cálculo de Sum e Sumq e depois agrupá-los para o cálculo da variância (usar um terceiro thread, embora não seja necessário). Proponha um pseudocódigo usando semáforos para sincronização de threads de forma a resolver o problema.
-
Proponha um esqueleto de um código de um servidor e de um cliente usando pipes nomeados para implementar um serviço de consulta da quantidade de peças de um estoque de auto-peças. O cliente fornece um identificador de peça (inteiro de 2 bytes) e recebe um inteiro long de 4 bytes.
- Discuta o problema da inversão de prioridades no contexto de sincronização de processos. Apresente uma possível solução.
- Proponha um exemplo usando 3 processos que entram em estado de deadlock.
- Crie um exemplo de controle de acesso a uma região crítica em que o método de Peterson é utilizado. Explique o funcionamento do mecanismo.
- Mostre através de um exemplo porque pode existir problema de inconsistência em dados compartilhados entre dois processos. Inclua neste explicação o uso da palavra preempção, condição de corrida e sincronização de processos.
Questões relacionadas a políticas de escalonamento.
-
Considere 4 processos (A, B, C, D) com os seguintes tempos de CPU: 8, 5, 6, e 7 segundos respectivamente. Todos são processos CPU-bound (não fazem I/O), de mesma prioridade e escalonados segundo a política Round-Robin com um quantum de 5 segundos. Todos os processos chegam ao sistema (i.e., são disparados) respectivamente em 0, 4, 9 e 14 segundos. Calcule o tempo médio de espera e o tempo médio de resposta
do lote de processos.
-
Considere 4 processos (A, B, C, D) com os seguintes tempos de CPU: 2, 8, 3, e 5 segundos respectivamente. Todos são processos CPU-bound (não fazem I/O), e possuem as seguintes prioridades: A 3, B 1, C 2, D 3. Esses processos são escalonados segundo a política de prioridade estática. Todos os processos chegam ao sistema (i.e., são disparados) respectivamente em 0, 1, 2 e 3 segundos. Calcule o tempo médio de
espera e o tempo médio de resposta do lote de processos, considerando o escalonamento preemptivo e o não preemptivo.
AULA 19 - Dia 24/04/2019
- Avaliação 1
AULA 20 - Dia 26/04/2019
Objetivos
- Introdução ao Gerenciamento de Memória (Cap.8)
Exercício 1 - Examinando o posicionamento de código e dados
Implementar e executar o código abaixo
#include <stdio.h>
#include <stdlib.h>
int x;
int y=1;
int main(int argc, char *argv[])
{
char *p="IFSC";
printf("End da função main = %p\n",main);
printf ("End x = %p\n",&x);
printf ("End y = %p\n",&y);
printf ("End p = %p\n",&p);
printf ("End da string IFSC = %p\n",p);
p=malloc(10);
printf ("End da área alocada de 10 bytes = %p\n", p);
for(;;);
}
Colocar o processo em execução e em outro terminal verificar o PID e examinar a área alocada ao processo usando o comando pmap
pmap -x PID_PROCESSO
Comparar as áreas alocadas para verificar onde estão as variáveis
Executar 3 instâncias do programa e comparar os endereços.
Ver Fig.15.2 livro Prof.Maziero para verificar a diferença entre endeeços lógicos e físicos.
Executar o comando readelf para verificar como os endereços foram gerados em tempo de compilação/linkagem:
readelf -s a./out
Exercício 2 - Examinando a independência da posição do código
Implementar o código:
int x;
main()
{
x=1;
x=2;
}
Compilar:
gcc -g -O0 ex2.c -o ex2
Carregar o programa com o gdb
gdb ex2
Colocar breakpoint no main
b main
Executar
r
Disassemblar
disassemble
Deve aparece algo como:
0x00000000004004ed <+0>: push %rbp
0x00000000004004ee <+1>: mov %rsp,%rbp
=> 0x00000000004004f1 <+4>: movl $0x1,0x200b41(%rip) # 0x60103c <x>
0x00000000004004fb <+14>: movl $0x2,0x200b37(%rip) # 0x60103c <x>
0x0000000000400505 <+24>: pop %rbp
0x0000000000400506 <+25>: retq
</syntaxhighlight>
Verificar como o acesso a variável global fica independente da posição:
x/i $rip
Executar próxima instrução com n e voltar a disassemblar
n
Link Interessante:
https://carsontang.github.io/unix/2013/06/01/guide-to-object-file-linking/
https://www.recurse.com/blog/7-understanding-c-by-learning-assembly
https://stackoverflow.com/questions/29295875/gcc-why-global-variable-missing-in-dynamic-symbol-table
https://manybutfinite.com/post/anatomy-of-a-program-in-memory/
https://bneuburg.github.io/volatility/kaslr/2017/04/26/KASLR1.html
https://www.theurbanpenguin.com/aslr-address-space-layout-randomization/
http://www.daniloaz.com/en/differences-between-aslr-kaslr-and-karl/
AULA 21 - Dia 03/05/2019
Objetivos
- Apresentação/Seminário dos Alunos: Free RTOS
AULA 22 - Dia 08/05/2019
Objetivos
- Apresentação/Seminário dos Alunos: Free RTOS
- FreeRTOS no Arduino
- ETAPA 2 do Projeto
O ATmega238 usado no Arduino UNO
Ver [9]
O Arduino UNO
O FreeRtos para o Arduino
Ver [12]
Para instalar no IDE:
- Baixar o ZIP do link acima
- No IDE importar a biblioteca:
- sketch->IncluirBiblioteca->Adicionar do arquivo ZIP
Exemplo
O exemplo abaixo é de caráter puramente didático. 4 tarefas são criadas:
- uma tarefa para piscar periodicamente o LED built-in do Arduino UNO;
- Uma tarefa que conta interrupções INT0 e mostra a contagem;
- Uma tarefa que faz leitura da interface serial usando uma abordagem espera ocupada e sinaliza
para uma outra tarefa escrever na serial;
- Uma tarefa que escreve na serial e é bloqueada em um semáforo binário.
Um handler de interrupção foi associado a INT0 usando a biblioteca do Arduino
// Code based on Examples of Arduino and examples
// from https://github.com/feilipu/Arduino_FreeRTOS_Library
#include <Arduino_FreeRTOS.h>
#include <FreeRTOSVariant.h>
#include <task.h>
#include <semphr.h>
const byte interruptPin = 2; // colocar fio no pino 2
// 4 tarefas: pisca led, le dados serial, escreve dados na serial, e conta interrupções zero
void TaskBlink( void *pvParameters );
void TaskReadFromSerial( void *pvParameters );
void TaskPrintSerial( void *pvParameters );
void TaskINT0( void *pvParameters );
SemaphoreHandle_t xSemaphoreSerial = NULL;
SemaphoreHandle_t xSemaphoreINT0 = NULL;
int dadoRecebido = 0; // variável para o dado recebido
// função de setup
void setup() {
Serial.begin(9600);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB, on LEONARDO, MICRO, YUN, and other 32u4 based boards.
}
//criar dois semáforos binários
xSemaphoreSerial = xSemaphoreCreateBinary();
xSemaphoreINT0 = xSemaphoreCreateBinary();
// criar as 4 tarefas
xTaskCreate(
TaskBlink
, (const portCHAR *)"Blink" // A name just for humans
, 128 // This stack size can be checked & adjusted by reading the Stack Highwater
, NULL
, 2 // Priority, with 3 (configMAX_PRIORITIES - 1) being the highest, and 0 being the lowest.
, NULL );
xTaskCreate(
TaskReadFromSerial
, (const portCHAR *) "ReadFromSerial"
, 128 // Stack size
, NULL
, 1 // Priority
, NULL );
xTaskCreate(
TaskPrintSerial
, (const portCHAR *) "PrintSerial"
, 128 // Stack size
, NULL
, 1 // Priority
, NULL );
xTaskCreate(
TaskINT0
, (const portCHAR *) "Task da INT0"
, 128 // Stack size
, NULL
, 1 // Priority
, NULL );
//vPortSetInterruptHandler( mainINTERRUPT_NUMBER, ulExampleInterruptHandler );
attachInterrupt(digitalPinToInterrupt(interruptPin), ulMinhaInterruptHandler, FALLING);
// escalonador toma conta a partir daqui
}
void loop()
{
// nada a fazer aqui
}
/*--------------------------------------------------*/
/*---------------------- Tasks ---------------------*/
/*--------------------------------------------------*/
void TaskBlink(void *pvParameters) // This is a task.
{
(void) pvParameters;
/*
Blink
Turns on an LED on for one second, then off for one second, repeatedly.
Most Arduinos have an on-board LED you can control. On the UNO, LEONARDO, MEGA, and ZERO
it is attached to digital pin 13, on MKR1000 on pin 6. LED_BUILTIN takes care
of use the correct LED pin whatever is the board used.
The MICRO does not have a LED_BUILTIN available. For the MICRO board please substitute
the LED_BUILTIN definition with either LED_BUILTIN_RX or LED_BUILTIN_TX.
e.g. pinMode(LED_BUILTIN_RX, OUTPUT); etc.
If you want to know what pin the on-board LED is connected to on your Arduino model, check
the Technical Specs of your board at https://www.arduino.cc/en/Main/Products
This example code is in the public domain.
modified 8 May 2014
by Scott Fitzgerald
modified 2 Sep 2016
by Arturo Guadalupi
*/
// initialize digital LED_BUILTIN on pin 13 as an output.
pinMode(LED_BUILTIN, OUTPUT);
for (;;) // A Task shall never return or exit.
{
digitalWrite(LED_BUILTIN, HIGH); // turn the LED on (HIGH is the voltage level)
vTaskDelay( 1000 / portTICK_PERIOD_MS ); // wait for one second
digitalWrite(LED_BUILTIN, LOW); // turn the LED off by making the voltage LOW
vTaskDelay( 1000 / portTICK_PERIOD_MS ); // wait for one second
}
}
void TaskReadFromSerial(void *pvParameters) // This is a task.
{
(void) pvParameters;
/*
AnalogReadSerial
Reads an analog input on pin 0, prints the result to the serial monitor.
Graphical representation is available using serial plotter (Tools > Serial Plotter menu)
Attach the center pin of a potentiometer to pin A0, and the outside pins to +5V and ground.
This example code is in the public domain.
It was modified by Eraldo S.Silva just to read from serial and to signal in a Binary Semaphore
*/
for (;;)
{
Serial.println("Entrar com dados\n");
while (Serial.available() == 0); // espera ocupada lendo a serial - não é uma boa ideia...
// lê do buffer o dado recebido:
dadoRecebido = Serial.read();
xSemaphoreGive( xSemaphoreSerial );
vTaskDelay(1); // one tick delay (15ms) in between reads for stability - b
}
}
void TaskPrintSerial(void *pvParameters) // Task que imprime na serial - must be improved...
{
(void) pvParameters;
/*
*/
for (;;)
{
xSemaphoreTake( xSemaphoreSerial, portMAX_DELAY );
Serial.print("Recebido : ");
Serial.println(dadoRecebido);
}
}
//task to count INT0 occurrences
void TaskINT0(void *pvParameters) // Task que processa a INT0
{
(void) pvParameters;
int contINT0=0;
/*
created by Eraldo S. e Silva
*/
for (;;)
{
xSemaphoreTake( xSemaphoreINT0, portMAX_DELAY );
Serial.print("Cont INT0 : ");
Serial.println(contINT0++, DEC);
}
}
// Handler de Interrupção 0 - acorda a tarefa TaskINT0 que espera no semáforo
// Based on FreeRTOS Reference Manual
void ulMinhaInterruptHandler( void )
{
BaseType_t xHigherPriorityTaskWoken;
xHigherPriorityTaskWoken = pdFALSE;
xSemaphoreGiveFromISR( xSemaphoreINT0, &xHigherPriorityTaskWoken );
//portYIELD_FROM_ISR( xHigherPriorityTaskWoken ); parece não ter ...
}
ETAPA 2 do Projeto
Cada equipe contruirá aplicações que demonstrem o funcionamento dos mecanismos que foram estudados no capítulo.
Um dia de aula será reservado para uma oficina em que as equipes vão expor e explicar as aplicações desenvolvidas.
AULA 24 - Dia 10/05/2019
Objetivos
- Cap.8 - Gerenciamento de Memória - Vinculação de Endereços -
AULA 25 - Dia 15/05/2019
Correção da Avaliação
AULA 26 - Dia 17/05/2019
Cap.8 - Gerenciamento de Memória - Swapping - Paginação
AULA 27 - Dia 22/05/2019
Gerenciamento de Memória - Paginação
AULA 28 - Dia 24/05/2019
- Desenvolvimento do Projeto
AULA 29 - Dia 29/05/2019
Objetivos
- Desenvolvimento do Projeto
AULA 30 - Dia 31/05/2019
Apresentação Parte 2 do Projeto
AULA 31 - Dia 5/06/2019
- Apresentação de duas equipes (parte 2 do projeto)
- Cap.8 - Gerenciamento de Memória - Segmentação -
- Cap.9 - Memória Virtual
Exercício
Escreva um programa de computador que, dada a configuração de um sistema de paginação e um endereço de entrada, forneça informações sobre o endereço dado no referido sistema. Mais detalhes abaixo:
Entradas do programa:
Largura do endereço em bits
Tamanho das páginas em bytes
Arquivo com tabela de páginas
Endereço a ser traduzido
Saídas do programa:
Número de frames no sistema
Número da página (endereço lógico)
Número do frame (endereço físico) (Hit ou Page Fault?)
Deslocamento
Endereço físico
A tabela de páginas estará em um arquivo em modo texto contendo um mapeamento por linha, como o abaixo. Observe que o arquivo contém os números de página ou frame, e não endereços.
0-10
1-9
2-20
3-37
4-1
5-4
6-7
7-6
</syntaxhighlight>
arliones@socrates:~/workspace/paging_sim$ ./paging_sim
Usage: ./paging_sim ADDR_LEN PAGE_SIZE MAP_FILE ADDRESS
arliones@socrates:~/workspace/paging_sim$ ./paging_sim 16 1024 page_table.txt 5687
Frames in the system: 64
Requested page: 5
Requested frame: 4
Offset: 0x237 (567)
Logical Address: 0x1637 (5687)
Physical Address: 0x1237 (4663)
arliones@socrates:~/workspace/paging_sim$ ./paging_sim 16 1024 page_table.txt 10578
Frames in the system: 64
Requested page: 10
Requested frame: Page Fault
Offset: 0x152 (338)
Logical Address: 0x2952 (10578)
Physical Address: 0xfffffd52 (4294966610)
arliones@socrates:~/workspace/paging_sim$ ./paging_sim 32 4096 page_table.txt 8632
Frames in the system: 1048576
Requested page: 2
Requested frame: 20
Offset: 0x1b8 (440)
Logical Address: 0x21b8 (8632)
Physical Address: 0x141b8 (82360)
arliones@socrates:~/workspace/paging_sim$ ./paging_sim 32 4096 page_table.txt 68723
Frames in the system: 1048576
Requested page: 16
Requested frame: Page Fault
Offset: 0xc73 (3187)
Logical Address: 0x10c73 (68723)
Physical Address: 0xfffffc73 (4294966387)
arliones@socrates:~/workspace/paging_sim$ ./paging_sim 32 4194304 page_table.txt 354
Frames in the system: 1024
Requested page: 0
Requested frame: 10
Offset: 0x162 (354)
Logical Address: 0x162 (354)
Physical Address: 0x2800162 (41943394)
arliones@socrates:~/workspace/paging_sim$ ./paging_sim 32 4194304 page_table.txt 43554432
Frames in the system: 1024
Requested page: 10
Requested frame: Page Fault
Offset: 0x189680 (1611392)
Logical Address: 0x2989680 (43554432)
Physical Address: 0xffd89680 (4292384384)
</syntaxhighlight>
AULA 32 - Dia 7/06/2019
- Apresentação da Etapa 2 do trabalho
AULA 33 - Dia 12/06/2019
Objetivos
- Revisão de Paginação
- Memória Virtual
- Paginação por Demanda
- Desempenho de Paginação por Demanda
- Cópia-após-gravação
- Substituição de Páginas
Exercícios para guiar o estudo do Cap.9 - Memória Virtual
- Explique o que é um serviço de páginas por demanda e o que é um erro de falta de falta ("page fault").
- Considere que um acesso a memória física sem erro de página leva 100ns e com erro de página é 10ms. Qual o tempo médio de acesso (tempo de acesso efetivo) considerando uma probabilidade de erro de acesso de 0.01?
- Descreva as etapas da rotina de serviço de erros de páginas considerando a substituição de páginas. (lembrar da Figura 9.6 do Silberchatz)
- O que é um "quadro vítima" do ponto de vista de um algoritmo de substituição de páginas?
- Quantos acesso a memória de retaguarda seriam necessárias no caso de não existir mais quadros livres na substituição de páginas?
- Explique como é usado o "dirty bit" (bit de modificação) no contexto de substituição de páginas?
- Explique por que usando a paginação sob demanda pode-se fazer com que o processo tenha espaço de endereçamento muito maior que a memória fśicia?
- Para se ter a paginação sob demanda deve-se resolver dois problemas através dos seguintes algoritmos: substituição de páginas e alocação de quadros. Explique brevemente do que tratam estes algoritmos.
- Como avaliamos quão bom é um algoritmo de substituição de páginas? Descreva brevemente o procedimento citando "sequência de referência".
- Elabore um exemplo do funcionamento do algoritmo de substituição de páginas FIFO considerando 3 blocos ("frames" de memória física) para a sequência de referência: 0 0 1 1 7 2 7 6 5 4 2 3 1 3 5 6
- Explique o que é a anomalia de Belady.
- Elabore um exemplo do funcionamento do algoritmo ÓTIMO de substituição de páginas considerando 3 blocos ("frames" de memória física) para a sequência de referência: 0 0 1 1 7 2 7 6 5 4 2 3 1 3 5 6
- O algoritmo ÓTIMO de substituição de páginas pode ser implementado na prática? Explique.
- Elabore um exemplo do funcionamento do algoritmo substituição de páginas LRU considerando 3 blocos ("frames" de memória física) para a sequência de referência: 0 0 1 1 7 2 7 6 5 4 2 3 1 3 5 6 Qual a similaridade deste algoritmo com o algoritmo ótimo?
- Existem algoritmos de substituição de página por aproximação ao LRU. Cite e explique brevemente 3 destas variações.
- Descreva brevemente o princípio de funcionamento dos algoritmos de substituição de páginas LFU e MFU
- Descreva como funciona o algoritmo de alocação de quadros proporcional.
- Qual a diferença entre alocação Global versus alocação Local de Quadros.
/*
* MapFile.h
*
* Created on: Oct 29, 2014
* Author: arliones
*/
#ifndef MAPFILE_H_
#define MAPFILE_H_
#include <string>
#include <map>
#include <fstream>
#include <stdlib.h>
#include <iostream>
using namespace std;
class MapFile {
MapFile() {}
public:
MapFile(string filename)
{
ifstream file(filename.c_str());
string line;
char line_c[256];
unsigned int page, frame, delimiter;
while(!file.eof()) {
file.getline(line_c,256); line = string(line_c);
delimiter = line.find('-');
page = atoi(line.substr(0,delimiter+1).c_str());
frame = atoi(line.substr(delimiter+1).c_str());
_pt.insert(make_pair(page,frame));
}
}
virtual ~MapFile() {}
// Returns the number of the frame or -1 if not found
unsigned int get_frame(unsigned int page)
{
//TODO
}
void print_page_table()
{
cout << "Page Table:" << endl;
map<unsigned int, unsigned int>::iterator mit = _pt.begin();
for(; mit != _pt.end(); ++mit)
cout << mit->first << " - " << mit->second << endl;
}
private:
map<unsigned int, unsigned int> _pt;
};
#endif /* MAPFILE_H_ */
AULA 34 - Dia 14/06/2019
- Interface de Sistema de Arquivos (cap.12)
AULA 35 - Dia 19/06/2019
Objetivos
- Implementação de Sistemas de Arquivos (cap.12)
AULA 36 - Dia 26/06/2019
Objetivos
- Subsistema IO: cap.13
AULA 37 - Dia 28/06/2019
Objetivos
- Finalização de Subsistema IO: cap.13
- Preparação para avaliação
Principais pontos para Estudo para Avaliação II
- Cap.8
- Seções de 8.1 (menos 8.1.4 e 8.1.5) a 8.4 - Seção 8.6 - Segmentação
- Cap.9
- Seções 9.1, 9.2.1(introdução também), 9.3 , 9.4.1 (introdução também),9.4.2 e 9.5.1 (introdução também)
- cap.10
- Seções 10.1 E 10.3
- cap.11
- Seções 11.1 e 11.2
- Caso de estudo da implementação no Unix (figura Slide do Arliones)
- Cap.12
- Seção 12.1.1
- Cap.13
- Seção 13.1 (+Fig.13.6) E 13.5
Explanação sobre montagem de sistemas de arquivos e relação com devide drivers =
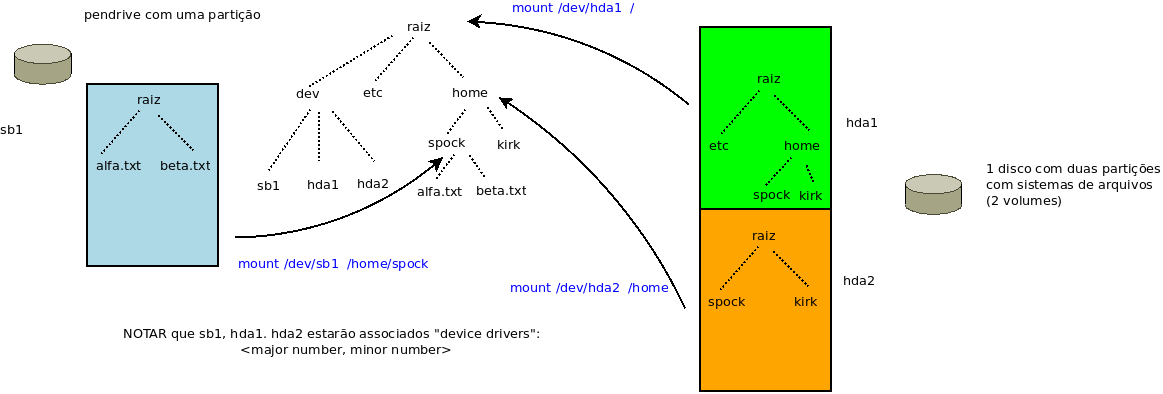
Abrir um terminal e conferir:
df -h
AULA 38 - Dia 3/07/2019
- Segunda avaliação
AULA 39 - Dia 5/07/2019
- Apresentação Individual dos Projetos
AULA 40 - Dia 10/07/2019
- Recuperação Final
- Pontos para Recuperação
Pontos para Recuperação
- Cap.2 (introdução)
- 2.1
- 2.3, 2.4
- 2.7.1 (e introdução do 2.7)
- Cap.3 (introdução)
- 3.1, 3.2,3.3,3.4
- Cap.4 (introdução)
- 4.1, 4.3.1 (também introdução)
- Cap.5 (introdução)
- 5.1,5.2,5.3 (menos o 5.3.2)
- Cap.6 (introdução)
- 6.1,6.2,6.3,6.5 e 6.6
- Cap.7 (introdução)
- 7.1
- Cap.8
- Seções de 8.1 (menos 8.1.4 e 8.1.5) a 8.4 - Seção 8.6 - Segmentação
- Cap.9
- Seções 9.1, 9.2.1(introdução também), 9.3 , 9.4.1 (introdução também),9.4.2 e 9.5.1 (introdução também)
- cap.10
- Seções 10.1 E 10.3
- cap.11
- Seções 11.1 e 11.2
- Caso de estudo da implementação no Unix (figura Slide do Arliones)
- Cap.12
- Seção 12.1.1
- Cap.13
- Seção 13.1 (+Fig.13.6) E 13.5
APOIO AO PROJETO
ETAPA 3.1 - Transmissão de Byte
//Autor: Eraldo Silveira e Silva
#include <Arduino_FreeRTOS.h>
#include <FreeRTOSVariant.h>
#include <task.h>
#include <semphr.h>
#include <timers.h>
const byte interruptPin = 2;
const byte outputSignalPIN = 13;
void TaskSender(void *pvParameters);
//MAQUINA DE TRANSMISSÂO
#define BIT_PERIODO pdMS_TO_TICKS(20)
#define STOP_BIT_PERIODO 5*BIT_PERIODO
class maquina_TX{
private:
volatile static enum t_estado {AGUARDA_STOP, TX, FIM_TX, FIM} estado;
static byte dado;
static byte cont;
static TimerHandle_t xTimerSerial;
public:
maquina_TX(){
digitalWrite(outputSignalPIN,HIGH);
xTimerSerial = xTimerCreate("Signal",STOP_BIT_PERIODO,pdTRUE,0,timerSerialHandler);
};
bool getStatus (){if(estado==FIM) return true; else return false;}
static void timerSerialHandler (TimerHandle_t meuTimer){
switch (estado) {
case AGUARDA_STOP:
estado = TX;
//xTimerStop(meuTimer,0);
cont = 0;
//Serial.println("STOP FEITO");
xTimerChangePeriod(meuTimer, BIT_PERIODO, 0);
//xTimerReset(meuTimer,0);
//xTimerStart(meuTimer,0);
break;
case TX:
if (dado & B00000001) {
digitalWrite(outputSignalPIN,HIGH);
//Serial.println("HIGH");
}else {
digitalWrite(outputSignalPIN,LOW);
//Serial.println("LOW");
}
cont++;
if (cont != 8) {
dado = dado >> 1;
} else {
estado = FIM_TX;
}
break;
case FIM_TX:
Serial.println("FIM TX");
xTimerStop(meuTimer,0);
estado=FIM;
break;
}
};
void enviar_byte(byte dado) {
estado = AGUARDA_STOP;
this->dado = dado;
digitalWrite(outputSignalPIN,HIGH); Serial.println("Iniciando STOP");
xTimerChangePeriod(xTimerSerial, STOP_BIT_PERIODO, 0);
xTimerStart(xTimerSerial,0);
};
} MTX;
volatile enum maquina_TX::t_estado maquina_TX::estado;
byte maquina_TX::dado;
byte maquina_TX::cont;
TimerHandle_t maquina_TX::xTimerSerial;
void setup() {
Serial.begin(9600);
pinMode(interruptPin,INPUT_PULLUP);
pinMode(outputSignalPIN,OUTPUT);
xTaskCreate(TaskSender, (const portCHAR*)"TaskSender", 128, NULL, 1, NULL);
}
//TAREFA EMISSORA -
//Esta tarefa poderia ler quadros de uma fila de recepção e transmití-los...
void TaskSender(void *pvParameters) {
(void) pvParameters;
Serial.println("TaskCounter: INICIANDO");
uint32_t receiveData;
for (;;) {
Serial.println("TaskSender: enviando byte");
MTX.enviar_byte(0xFA);
Serial.println("TaskSender: aguardando");
while(MTX.getStatus()==false); // ATENÇÂO: Esta espera OCUPADA deve ser revista. Usar um mecanismo tipo um semáforo para avisar o fim da serialização. Substituir getStatus (e o qhile) por WaitFIM()...
Serial.println("TaskSender: MTX liberado");
}
}
void loop() {
}
ETAPA 3.2 - Arquitetura do Nodo
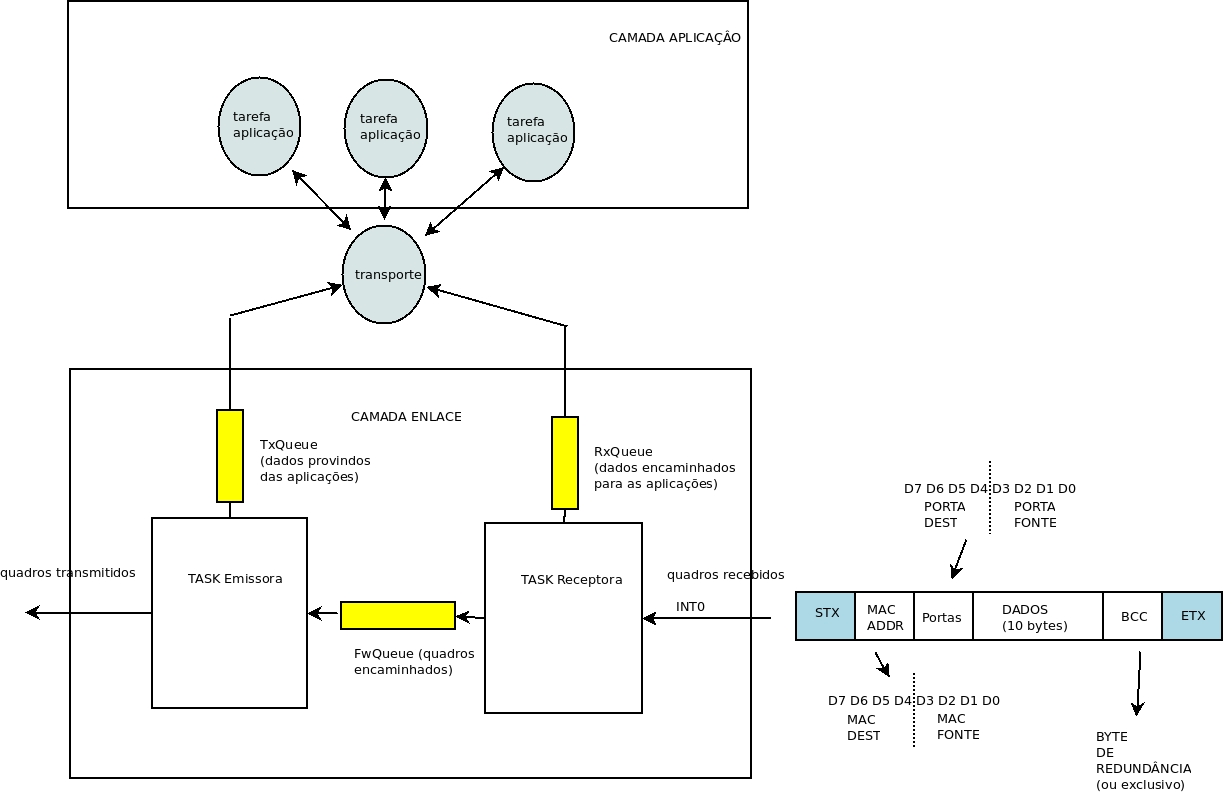
Vamos assumir que o quadro será transmitido em modo texto (segundo a tabela ASCII). Deve-se portanto fazer algumas mudanças para evitar
que alguns bytes do quadro sejam interpretados erroneamente
- MAC das Equipes
- EQ 1 - B1001
- EQ 2 - B1010
- EQ 3 - B1011
- EQ 4 - B1100
- EQ 5 - B1101
- EQ 6 - B1110
- EQ 7 - B1111
- ID das Portas
Sempre começar em 1
Resta ainda um problema que seria o BCC que pode resultar em qualquer valor. Para evitar confundir com STX ou ETX fazer um OU com B10000000 no resultado final.
A ideia é colocar sempre um bit a 1 na posição mais significativa.
- SUGESTÃO DE ESTRUTURA DA TaskSender
A Task Emissora deve aguardar por informação em um Set de Filas do RTOS composto por TxQueue e FwQueue.
TaskEmissora()
{
for (;;) {
Espera no Set de Queues
Se Dados na Tx Queue
Montar Quadro com dado da TxQueue
Enviar Quadro
Se Dados na FwQueue
Enviar quadro do topo da FwQueue
Fim-Se
}
}
Como os quadros são de tamanho fixo, a transmissão de quadro deve ser trivial: para enviando cada byte...
Conteúdo
Unidade 01: Introdução
Unidade 01: Introdução
Visão geral de funções, responsabilidades e estruturas de um SO
- Revolution OS: documentário sobre Linux e software livre
- Apresentação sobre histórico visão geral e estruturas básicas de um SO
- Capítulo 1 do livro do Silberschatz
Arquitetura de sistemas operacionais e modelos de programação
- Apresentação sobre histórico visão geral e estruturas básicas de um SO
- Capítulo 2 do livro do Silberschatz
Unidade 02: Processos
Unidade 02: Processos
Gerência de tarefas; contextos, processos e threads
- Apresentação sobre Gerenciamento de Processos
- Capítulo 3 do livro do Silberschatz
Escalonamento de tarefas
- Apresentação sobre Escalonamento de Processos
- Animação de escalonamento de processos - Virginia Tech
- Capítulo 5 do livro do Silberschatz.
- Estudo de caso: escalonador do Linux.
Comunicação entre Processos
- Apresentação sobre Comunicação entre Processos
- Capítulo 3 do livro do Silberschatz.
Coordenação de processos
- Apresentação sobre Coordenação de Processos
- Capítulos 6 e 7 do livro do Silberschatz.
- Curiosidade: A inversão de prioridades na Mars Pathfinder
Unidade 03: Memória
Unidade 03: Memória
Introdução ao Gerenciamento de Memória
- Apresentação sobre Gerenciamento de Memória
- Capítulo 8 do livro do Silberschatz.
Memória Principal
- Apresentação sobre Gerenciamento de Memória
- Capítulo 8 do livro do Silberschatz.
Memória Virtual
- Apresentação sobre Gerenciamento de Memória
- Capítulo 9 do livro do Silberschatz.
Exercícios
Unidade 04: Armazenamento
Unidade 04: Armazenamento
Interface do Sistema de Arquivos
- Apresentação sobre Gerenciamento de Arquivos
- Capítulo 10 do livro do Silberschatz.
Permissões de sistema de arquivos no Linux
Neste estudo de caso são realizados alguns exercícios práticos que permitem verificar como o sistema de arquivos é organizado no Linux.
Acesse o estudo de caso através deste roteiro do Prof. Maziero da UTFPR.
Implementação do Sistema de Arquivos
- Apresentação sobre Gerenciamento de Arquivos
- Capítulo 11 do livro do Silberschatz.
Exercícios
1. Qual tipo de organização de diretórios que o ubuntu utiliza, grafo cíclico, grafo acíclico, flat ou árvore, comprove seu raciocínio por meio de testes.
2. No ubuntu o que acontece quando deletamos um hard link, e em seguida acessamos o link como um arquivo comum e alteramos seu conteúdo?
* É possível tomar tal ação? Se sim Qual o efeito? explique.
* Faça o mesmo teste, porém desta vez utilize um soft link.
Estrutura de Armazenamento em Massa
- Apresentação sobre Gerenciamento de Arquivos
- Capítulo 12 do livro do Silberschatz.
Gerenciamento de Entrada e Saída
- Apresentação sobre Gerenciamento de Entrada e Saída
- Capítulo 13 do livro do Silberschatz.
Exercícios
Laboratórios
Ainda Threads - Escalonamento Round Robin e FCFS para Threads"
Escalonamento Round-Robin preemptivo
OBS: ver https://www.quora.com/What-exactly-does-typedef-do-in-C
A fazer:
- primitiva de término de processo (destrutor do objeto);
- primitiva de yield
- isolar o escalonador em uma função;
- isolar o dispatcher em uma função;
/**
User-level threads example.
Orion Sky Lawlor, olawlor@acm.org, 2005/2/18 (Public Domain)
*/
#include <stdio.h>
#include <stdlib.h>
#include <ucontext.h> /* for makecontext/swapcontext routines */
#include <queue> /* C++ STL queue structure */
#include <vector>
#include<signal.h>
#include<unistd.h>
#include <ucontext.h>
#include <sys/time.h>
#define TIME_SLICE 5
typedef void (*threadFn)(void);
class thread_cb {
int id_thread;
public:
ucontext_t contexto;
thread_cb(threadFn p, int id)
{
getcontext(&contexto);
int stackLen=32*1024;
char *stack=new char[stackLen];
contexto.uc_stack.ss_sp=stack;
contexto.uc_stack.ss_size=stackLen;
contexto.uc_stack.ss_flags=0;
id_thread = id;
makecontext(&contexto,p,0);
};
ucontext_t *get_context() {
return &contexto;
};
};
std::queue<class thread_cb *> ready_pool;
int id_thread = 0;
class thread_cb *curr_thread=NULL;
void add_thread(threadFn func)
{
class thread_cb *p = new thread_cb(func, ++id_thread);
ready_pool.push(p);
}
void dispatcher(ucontext_t *old_task, ucontext_t *new_task)
{
if (old_task!=NULL)
swapcontext(old_task, new_task);
else
setcontext(new_task);
}
void scheduler_rr()
{
class thread_cb *next,*last;
if(curr_thread!=NULL) {
printf("Aqui\n");
ready_pool.push(curr_thread);
last=curr_thread;
next=ready_pool.front();
ready_pool.pop();
curr_thread=next;
dispatcher(last->get_context(), curr_thread->get_context());
} else {
next=ready_pool.front();
ready_pool.pop();
curr_thread = next;
dispatcher(NULL, next->get_context());
}
}
void sig_handler(int signo)
{
printf("SOP da Turma 2019-2: recebido SIGALRM\n");
alarm(TIME_SLICE);
if (ready_pool.empty()) {
printf("Nothing more to run!\n");
exit(0);
}
scheduler_rr();
}
void preparar_handler()
{
if (signal(SIGALRM, sig_handler) == SIG_ERR) {
printf("\nProblemas com SIGUSR1\n");
exit(-1);
}
alarm(TIME_SLICE);
}
void runA(void) {
for (;;) {
printf("running A\n");
sleep(1);
}
}
void runB(void) {
for (;;) {
printf("running B\n");
sleep(1);
}
}
main()
{
add_thread(runA);
add_thread(runB);
preparar_handler();
for(;;);
}
/**
User-level threads example.
Orion Sky Lawlor, olawlor@acm.org, 2005/2/18 (Public Domain)
*/
#include <stdio.h>
#include <stdlib.h>
#include <ucontext.h> /* for makecontext/swapcontext routines */
#include <queue> /* C++ STL queue structure */
#include <vector>
#include<signal.h>
#include<unistd.h>
#include <ucontext.h>
#include <sys/time.h>
#define TIME_SLICE 1
typedef void (*threadFn)(void);
class thread_cb {
int id_thread;
public:
ucontext_t contexto;
thread_cb(threadFn p, int id)
{
getcontext(&contexto);
int stackLen=32*1024;
char *stack=new char[stackLen];
contexto.uc_stack.ss_sp=stack;
contexto.uc_stack.ss_size=stackLen;
contexto.uc_stack.ss_flags=0;
id_thread = id;
makecontext(&contexto,p,0);
};
ucontext_t *get_context() {
return &contexto;
};
};
std::queue<class thread_cb *> ready_pool;
int id_thread = 0;
class thread_cb *curr_thread=NULL;
void scheduler_rr();
void add_thread(threadFn func)
{
class thread_cb *p = new thread_cb(func, ++id_thread);
ready_pool.push(p);
}
void yield_thread()
{
scheduler_rr();
}
void delete_thread()
{
delete curr_thread;
curr_thread=NULL;
scheduler_rr();
}
void dispatcher(ucontext_t *old_task, ucontext_t *new_task)
{
if (old_task!=NULL)
swapcontext(old_task, new_task);
else
setcontext(new_task);
}
void scheduler_rr()
{
class thread_cb *next,*last;
if(curr_thread!=NULL) {
printf("Aqui\n");
ready_pool.push(curr_thread);
last=curr_thread;
next=ready_pool.front();
ready_pool.pop();
curr_thread=next;
dispatcher(last->get_context(), curr_thread->get_context());
} else {
next=ready_pool.front();
ready_pool.pop();
curr_thread = next;
dispatcher(NULL, next->get_context());
}
}
void sig_handler(int signo)
{
printf("SOP da Turma 2019-2: recebido SIGALRM\n");
alarm(TIME_SLICE);
if (ready_pool.empty()) {
printf("Nothing more to run!\n");
exit(0);
}
scheduler_rr();
}
void preparar_handler()
{
if (signal(SIGALRM, sig_handler) == SIG_ERR) {
printf("\nProblemas com SIGUSR1\n");
exit(-1);
}
alarm(TIME_SLICE);
}
struct delta{
long alfa;
char epson[1000];
long beta;
} shar;
int turn;
int flag[2];
#define TRUE 1
#define FALSE 0
void ent_rc(int p, int vt)
{
flag[p]=TRUE;
turn = vt;
if(p) p=0; else p=1;
while (flag[p] && turn == vt);
//printf("Thread %d: esperando para acessar a região crítica\n", p);
}
void sai_rc(int p)
{
flag[p]=FALSE;
}
void runA(void) {
struct delta x = {0, 100};
for (;;) {
x.alfa=0;x.beta=0;
ent_rc(0,1);
shar=x; // regiao crítica
sai_rc(0);
x.alfa=100;x.beta=100;
ent_rc(0,1);
shar=x; // regiao crítica
sai_rc(0);
}
}
void runB(void) {
for (;;) {
ent_rc(1,0);
printf("shar alfa = %ld shar beta = %ld \n",shar.alfa, shar.beta); // regiao crítica
sai_rc(1);
sleep(1);
}
}
void runC(void) {
int i;
for (i=0;i<10;i++) {
printf("Thread C - parte 1\n");
yield_thread();
printf("Thread C - parte 2\n");
yield_thread();
}
delete_thread();
}
main()
{
add_thread(runA);
add_thread(runB);
add_thread(runC);
preparar_handler();
for(;;);
}
Ainda Threads - Um escalonador semi-automático"
Ainda Threads - Um escalonador semi-automático usando sinais
Neste laboratório serão aprimorados os threads em nível de aplicação vistos na aula anterior. Usaremos sinais do Unix/Linux para escalonar os threads via handlers.
Exemplo 1:
No Linux/Unix o kernel ou um processo podem enviar sinais para outros processos. Trata-se de uma notificação de que um evento ocorreu. O processo pode ter tratadores (handlers) para estes sinais de forma a tratá-los de forma assíncrona. Pode-se fazer uma analogia com a interrupção por hardware de um programa em execução. Um tratador da interrupção trata a causa da mesma (evento) e no final do tratador (handler) é restaurado o contexto do programa interrompido. Por exemplo, quando um filho se encerra, o pai recebe do kernel o sinal SIGCHLD.
No exemplo abaixo utilizamos o sinail USR1 de uso geral (disponível para o usuário). Associamos um handler a este sinal (sig_handler). O programa sendo executado, fica em loop no main(). Usando um outro terminal podemos enviar um sinal e verificar o efeito do mesmo.
#include<stdio.h>
#include <stdlib.h>
#include<signal.h>
#include<unistd.h>
void sig_handler(int signo)
{
int x;
printf("Turma de SOP: recebido SIGUSR1\n");
}
int main(void)
{
int x;
if (signal(SIGUSR1, sig_handler) == SIG_ERR) {
printf("\nProblemas com SIGUSR1\n");
exit(-1);
}
// Loop eterno dormindo 1s
while(1) {
sleep(1);
}
return 0;
}
Fazer no terminal:
ps aux
anotar o pid do processo e enviar o sinal:
kill -USR1 pid
Exemplo 2: O programa anterior é aprimorado para começar a executar um thread Ping similar a aula anterior. Ainda não existe escalonamento dos threads. Somente o thread ping é executado. O sinal USR1 pode ser enviado para o processo interrompendo a execução do thread.
#include<stdio.h>
#include <stdlib.h>
#include<signal.h>
#include<unistd.h>
#include <ucontext.h>
#define STACKSIZE 32768 /* tamanho de pilha das threads */
#define PING_ID 1
/* VARIÁVEIS GLOBAIS */
ucontext_t cPing, cPong, cMain;
int curr_thread;
/* Handler para tratar o sinal */
void sig_handler(int signo)
{
printf("Turma de SOP: recebido SIGUSR1\n");
}
/* Funções-comportamento das Tarefas */
void f_ping(void * arg) {
int i=0;
printf("%s iniciada\n", (char *) arg);
for (;;) {
printf("%s %d\n", (char *) arg, i++);
sleep(1);
}
printf("%s FIM\n", (char *) arg);
}
void f_pong(void * arg) {
int i=0;
printf("%s iniciada\n", (char *) arg);
for (;;) {
printf("%s %d\n", (char *) arg, i++);
sleep(1);
}
printf("%s FIM\n", (char *) arg);
}
void preparar_contexto_ping()
{
char *stack;
getcontext(&cPing);
stack = malloc(STACKSIZE);
if(stack) {
cPing.uc_stack.ss_sp = stack ;
cPing.uc_stack.ss_size = STACKSIZE;
cPing.uc_stack.ss_flags = 0;
cPing.uc_link = 0;
}
else {
perror("Erro na criação da pilha: ");
exit(1);
}
makecontext(&cPing, (void*)(*f_ping), 1, "\tPing");
}
void preparar_contexto_pong()
{
char *stack;
getcontext(&cPong);
stack = malloc(STACKSIZE);
if(stack) {
cPong.uc_stack.ss_sp = stack ;
cPong.uc_stack.ss_size = STACKSIZE;
cPong.uc_stack.ss_flags = 0;
cPong.uc_link = 0;
}
else {
perror("Erro na criação da pilha: ");
exit(1);
}
makecontext (&cPong, (void*)(*f_pong), 1, "\tPong");
}
int main(void)
{
int x;
printf ("Main INICIO\n");
preparar_contexto_ping();
preparar_contexto_pong();
if (signal(SIGUSR1, sig_handler) == SIG_ERR) {
printf("\nProblemas com SIGUSR1\n");
exit(-1);
}
curr_thread=PING_ID;
swapcontext(&cMain, &cPing);
// loop eterno que nunca é executado
while(1) {
sleep(1);
}
return 0;
}
Enviar o sinal USR1 para ver o efeito.
Exemplo 3: Neste exemplo preparamos o handler para chavear o contexto de ping para pong e vice-versa. A cada USR1 recebido será realizada a troca de contexto.
#include<stdio.h>
#include <stdlib.h>
#include<signal.h>
#include<unistd.h>
#include <ucontext.h>
#define STACKSIZE 32768 /* tamanho de pilha das threads */
#define PING_ID 1
#define PONG_ID 2
/* VARIÁVEIS GLOBAIS */
ucontext_t cPing, cPong, cMain;
int curr_thread;
/* Handler para tratar o sinal */
void sig_handler(int signo)
{
printf("Turma de SOP: recebido SIGUSR1\n");
if (curr_thread==PING_ID) {
curr_thread=PONG_ID;
swapcontext(&cPing, &cPong);
} else {
curr_thread=PING_ID;
swapcontext(&cPong, &cPing);
}
}
/* Funções-comportamento das Tarefas */
void f_ping(void * arg) {
int i=0;
printf("%s iniciada\n", (char *) arg);
for (;;) {
printf("%s %d\n", (char *) arg, i++);
sleep(1);
}
printf("%s FIM\n", (char *) arg);
}
void f_pong(void * arg) {
int i=0;
printf("%s iniciada\n", (char *) arg);
for (;;) {
printf("%s %d\n", (char *) arg, i++);
sleep(1);
}
printf("%s FIM\n", (char *) arg);
}
void prepara_contexto_ping()
{
char *stack;
getcontext(&cPing);
stack = malloc(STACKSIZE);
if(stack) {
cPing.uc_stack.ss_sp = stack ;
cPing.uc_stack.ss_size = STACKSIZE;
cPing.uc_stack.ss_flags = 0;
cPing.uc_link = 0;
}
else {
perror("Erro na criação da pilha: ");
exit(1);
}
makecontext(&cPing, (void*)(*f_ping), 1, "\tPing");
}
void prepara_contexto_pong()
{
char *stack;
getcontext(&cPong);
stack = malloc(STACKSIZE);
if(stack) {
cPong.uc_stack.ss_sp = stack ;
cPong.uc_stack.ss_size = STACKSIZE;
cPong.uc_stack.ss_flags = 0;
cPong.uc_link = 0;
}
else {
perror("Erro na criação da pilha: ");
exit(1);
}
makecontext (&cPong, (void*)(*f_pong), 1, "\tPong");
}
int main(void)
{
int x;
printf ("Main INICIO\n");
prepara_contexto_ping();
prepara_contexto_pong();
if (signal(SIGUSR1, sig_handler) == SIG_ERR) {
printf("\nProblemas com SIGUSR1\n");
exit(-1);
}
curr_thread=PING_ID;
swapcontext(&cMain, &cPing);
// A long long wait so that we can easily issue a signal to this process
while(1) {
sleep(1);
}
return 0;
}
Exercício: Tente analisar as pilhas dos threads e verificar sob qual pilha o handler se executa.
Exercício 4: Neste ponto associamos um timer ao handler com o apoio do sinal ALRM. Agora os threads são escalonados automaticamente.
- include<stdio.h>
- include <stdlib.h>
- include<signal.h>
- include<unistd.h>
- include <ucontext.h>
- include <sys/time.h>
- define STACKSIZE 32768 /* tamanho de pilha das threads */
// number of seconds for setting the interval used by the timer
- define QUANTUM_SEC 0
// number of microseconds for setting the interval used by the timer (0 - 999999)
- define QUANTUM_MICRO_SEC 100000
- define PING_ID 1
- define PONG_ID 2
- define TIME_SLICE 5
/* VARIÁVEIS GLOBAIS */
ucontext_t cPing, cPong, cMain;
int curr_thread;
/* Handler para tratar o sinal */
void sig_handler(int signo)
{
printf("SOP da Turma 2019-2: recebido SIGALRM\n");
alarm(TIME_SLICE);
if (curr_thread==PING_ID) {
curr_thread=PONG_ID;
swapcontext(&cPing, &cPong);
} else {
curr_thread=PING_ID;
swapcontext(&cPong, &cPing);
}
}
/* Funções-comportamento das Tarefas */
void f_ping(void * arg) {
int i=0;
printf("%s iniciada\n", (char *) arg);
for (;;) {
printf("%s %d\n", (char *) arg, i++);
sleep(1);
}
printf("%s FIM\n", (char *) arg);
}
void f_pong(void * arg) {
int i=0;
printf("%s iniciada\n", (char *) arg);
for (;;) {
printf("%s %d\n", (char *) arg, i++);
sleep(1);
}
printf("%s FIM\n", (char *) arg);
}
void preparar_contexto_ping()
{
char *stack;
getcontext(&cPing);
stack = malloc(STACKSIZE);
if(stack) {
cPing.uc_stack.ss_sp = stack ;
cPing.uc_stack.ss_size = STACKSIZE;
cPing.uc_stack.ss_flags = 0;
cPing.uc_link = 0;
}
else {
perror("Erro na criação da pilha: ");
exit(1);
}
makecontext(&cPing, (void*)(*f_ping), 1, "\tPing");
}
void preparar_contexto_pong()
{
char *stack;
getcontext(&cPong);
stack = malloc(STACKSIZE);
if(stack) {
cPong.uc_stack.ss_sp = stack ;
cPong.uc_stack.ss_size = STACKSIZE;
cPong.uc_stack.ss_flags = 0;
cPong.uc_link = 0;
}
else {
perror("Erro na criação da pilha: ");
exit(1);
}
makecontext (&cPong, (void*)(*f_pong), 1, "\tPong");
}
void preparar_handler()
{
if (signal(SIGALRM, sig_handler) == SIG_ERR) {
printf("\nProblemas com SIGUSR1\n");
exit(-1);
}
alarm(TIME_SLICE);
}
int main(void)
{
int x;
printf ("Main INICIO\n");
preparar_contexto_ping();
preparar_contexto_pong();
preparar_handler();
curr_thread=PING_ID; //ajusta primeiro thread
swapcontext(&cMain, &cPing); //nunca mais volta...
return 0;
}
</syntaxhighlight>
#include<stdio.h>
#include <stdlib.h>
#include<signal.h>
#include<unistd.h>
#include <ucontext.h>
#include <sys/time.h>
#define STACKSIZE 32768 /* tamanho de pilha das threads */
// number of seconds for setting the interval used by the timer
#define QUANTUM_SEC 0
// number of microseconds for setting the interval used by the timer (0 - 999999)
#define QUANTUM_MICRO_SEC 100000
#define PING_ID 1
#define PONG_ID 2
#define TIME_SLICE 5
/* VARIÁVEIS GLOBAIS */
ucontext_t cPing, cPong, cMain;
int curr_thread;
/* Handler para tratar o sinal */
void sig_handler(int signo)
{
printf("SOP da Turma 2019-2: recebido SIGALRM\n");
alarm(TIME_SLICE);
if (curr_thread==PING_ID) {
curr_thread=PONG_ID;
swapcontext(&cPing, &cPong);
} else {
curr_thread=PING_ID;
swapcontext(&cPong, &cPing);
}
}
/* Funções-comportamento das Tarefas */
void f_ping(void * arg) {
int i=0;
printf("%s iniciada\n", (char *) arg);
for (;;) {
printf("%s %d\n", (char *) arg, i++);
sleep(1);
}
printf("%s FIM\n", (char *) arg);
}
void preparar_contexto_ping(ucontext_t *pContext, char *p)
{
char *stack;
getcontext(pContext);
stack = malloc(STACKSIZE);
if(stack) {
(*pContext).uc_stack.ss_sp = stack ;
(*pContext).uc_stack.ss_size = STACKSIZE;
(*pContext).uc_stack.ss_flags = 0;
(*pContext).uc_link = 0;
}
else {
perror("Erro na criação da pilha: ");
exit(1);
}
makecontext(pContext, (void*)(*f_ping), 1, p);
}
void preparar_handler()
{
if (signal(SIGALRM, sig_handler) == SIG_ERR) {
printf("\nProblemas com SIGUSR1\n");
exit(-1);
}
alarm(TIME_SLICE);
}
int main(void)
{
int x;
printf ("Main INICIO\n");
preparar_contexto_ping(&cPing, "ping");
preparar_contexto_ping(&cPong, "pong");
preparar_handler();
curr_thread=PING_ID; //ajusta primeiro thread
swapcontext(&cMain, &cPing); //nunca mais volta...
return 0;
}
Um Exemplo de Uso "API Padrão POSIX"
Um Exemplo de Uso "API Padrão POSIX"
- Referências
Crie uma função soma que receba 2 ponteiros referenciando posições na memória, criadas utilizando nmap(), de maneira que estas posições armazenem números inteiros. A função soma deverá retornar a soma dos números apontados em regiões da memória sem a utilização de nenhuma rotina da biblioteca do C, que não sejam definidas por APIs posix, para criação destas
regiões na memória (malloc, alloc, calloc). Após retornar o resultado da soma os devidos ponteiros deverão ser extintos da memória.
- Experimento 1: Aumente o tamanho da memória alocada até quando for possível.
Qual o tamanho limite da memória que você conseguiu alocar?
- Experimento 2: Mude o escopo para PROT_NONE, após executar e depurar o código explique o que aconteceu.
Em sua opinião NMAP trata-se de uma syscall ou de uma API? Afinal API e syscall são a mesma coisa? Explique.
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *addr, size_t length);
addr = Valor do início do mapeamento.
length = valor do tamanho da região a ser alocada.
prot = especificações de proteção da região alocada (consultar http://man7.org/linux/man-pages/man2/mmap.2.html).
flags = especificação do escopo e do tipo da região criada (exemplo publica ou privada, se é anônima ou não).
void* meu_malloc(size_t tamanho) {
void* addr = mmap(0, // addr
tamanho, // len
PROT_READ | PROT_WRITE, // prot
MAP_ANON | MAP_PRIVATE, // flags
-1, // filedes
0); // off
*(size_t*)addr = tamanho;
return addr;
}
int meu_free(void* addr) {
return munmap(addr - sizeof(size_t), (size_t) addr);
}
int soma(int *N1, int *N2){
return (*N1+*N2);
}
int main(int argc, char* argv[]) {
int* numero1 = meu_malloc(sizeof(int));
int* numero2 = meu_malloc(sizeof(int));
*numero1 = 10;
*numero2 = 20;
int resultado = soma(numero1, numero2);
printf("\n\n O resultado da soma é %d \n\n",resultado);
meu_free(numero1);
meu_free(numero2);
return 0;
}
Processos no Linux
Processos no Linux - Modificado por Eraldo
- Exercícios propostos pelo Prof.Arliones e Modificados por Eraldo
- Syscall FORK
- Em um terminal, execute "man fork"
- A função da API POSIX fork() aciona uma chamada de sistema (system call - syscall) que cria um novo processo duplicando o processo que realiza a chamada. O novo processo, chamado de filho, é uma cópia exata do processo criador, chamado de pai, exceto por alguns detalhes listados na manpage. O principal destes detalhes para nós agora é o fato de terem PIDs diferentes.
- O código dos dois processos (pai e filho) são idênticos;
- Os dados dos dois processos (pai e filho) são idênticos NO MOMENTO DA CRIAÇÃO;
- Execução do processo filho inicia na próxima instrução do programa (no retorno da chamada FORK);
- Não é possível saber qual dos processos (pai ou filho) retormará a execução primeiro - isto fica a cargo do excalonador do SO;
- Valores de retorno da chamada FORK:
- (-1): erro na criação do processo (ex.: memória insuficiente);
- (0): em caso de sucesso, este é o valor de retorno recebido pelo processo filho;
- (>0): em caso de sucesso, este é o valor de retorno recebido pelo processo pai;
- Syscall JOIN
- A syscall JOIN é implementada no POSIX pela função wait(). Execute "man wait".
- Além da função wait(), há também waitpid() e waitid();
- Todas estas syscalls são utilizadas para aguardar por mudanças no estado de um processo filho e obter informações sobre o processo filho cujo estado tenha mudado. São consideradas mudanças de estado: o filho terminou; o filho foi finalizado por um sinal (ex.: kill); o filho foi retomado por um sinal (ex.: alarme);
- A chamada wait também libera os recursos do processo filho que termina;
- wait(): esta função suspende a execução do processo chamador até que UM DOS SEUS FILHOS finalize;
- waitpid(): suspende a execução do processo chamador até que UM FILHO ESPECÍFICO finalize;
- Syscall EXEC
- A syscall EXEC é implementada no POSIX pela família de funções exec(). Execute "man exec".
- As principais funções da família são execl(), execlp() e execvp();
- Todas estas funções são, na realidade, front-ends (abstrações) para a syscall execve. Esta syscall substitui a imagem do processo corrente (aquele que chama a syscall) pela a imagem de um novo processo;
- Os parâmetros passados a estas funções são, basicamente, o nome de um arquivo com a imagem do programa a ser executado (um binário de um programa), e uma lista de parâmetros a serem passados a este novo programa;
- Exemplos POSIX utilizando fork/wait/exec
- Exemplo 1: fork/wait básico
// ex1: fork/wait básico
#include <sys/types.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
int pid, status;
pid = fork();
if(pid == -1) // fork falhou
{
perror("fork falhou!");
exit(-1);
}
else if(pid == 0) // Este é o processo filho
{
printf("processo filho\t pid: %d\t pid pai: %d\n", getpid(), getppid());
exit(0);
}
else // Este é o processo pai
{
wait(&status);
printf("processo pai\t pid: %d\t pid pai: %d\n", getpid(), getppid());
exit(0);
}
}
arliones@socrates:~/tmp$ gcc ex1.c -o ex1
arliones@socrates:~/tmp$ ./ex1
processo filho pid: 27858 pid pai: 27857
processo pai pid: 27857 pid pai: 5337
arliones@socrates:~/tmp$
- Exemplo 2: processos pai e filho compartilham código, mas não dados.
// ex2: fork/wait "compartilhando" dados
// ex2: fork/wait "compartilhando" dados
#include <sys/types.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
int pid, status, k=0;
printf("processo %d\t antes do fork\n", getpid());
pid = fork();
printf("processo %d\t depois do fork\n", getpid());
if(pid == -1) // fork falhou
{
perror("fork falhou!");
exit(-1);
}
else if(pid == 0) // Este é o processo filho
{
k += 1000;
printf("processo filho\t pid: %d\t K: %d \t endereço K: %p\n", getpid(), k, &k);
exit(0);
}
else // Este é o processo pai
{
wait(&status); // espera o filho terminar
k += 10;
printf("processo pai\t pid: %d\t K: %d \t endereço K: %p\n", getpid(), k, &k);
exit(0);
}
k += 1000;
printf("FIM processo %d\t K: %d\n", getpid(), k);
exit(0);
}
processo 17056 antes do fork
processo 17056 depois do fork
processo 17057 depois do fork
processo filho pid: 17057 K: 1000 endereço K: 0x7ffd8923e318
processo pai pid: 17056 K: 10 endereço K: 0x7ffd8923e318
- Modificação no código: comentar linhas 23 e 30
- Analise os resultados e busque entender a diferença.
- Perguntas e desafios.:
- Analisando os valores impressos de k pode-se dizer que os dados são compartilhados entre os dois processos?
- O endereço de k impresso é o mesmo nos dois processos. ISto não contradiz a afirmação anterior?
- Substitua o k por uma área criada dinâmicamente com o malloc (área de HEAP). Verifique se esta área é ou não compartilhada pelos processos.
- Exercício fork/wait
Excrever um programa C que cria uma árvore de 3 processos, onde o processo A faz um fork() criando um processo B, o processo B, por sua vez, faz um fork() criando um processo C. Cada processo deve exibir uma mensagem "Eu sou o processo XXX, filho de YYY", onde XXX e YYY são PIDs de processos. Utilizar wait() para garantir que o processo C imprima sua resposta antes do B, e que o processo B imprima sua resposta antes do A. Utilizar sleep() (man 3 sleep) para haver um intervalo de 1 segundo entre cada mensagem impressa.
- Use o comando pstree para verificar a árvore de processos criada.
Solução
/*
ex3: Excrever um programa C que cria uma arvore de 3 processos, onde o processo
A faz um fork() criando um processo B, o processo B, por sua vez, faz um fork()
criando um processo C. Cada processo deve exibir uma mensagem "Eu sou o
processo XXX, filho de YYY", onde XXX e YYY sao PIDs de processos. Utilizar
wait() para garantir que o processo C imprima sua resposta antes do B, e que o
processo B imprima sua resposta antes do A. Utilizar sleep() (man 3 sleep) para
haver um intervalo de 1 segundo entre cada mensagem impressa.
- /
- include <sys/types.h>
- include <stdlib.h>
- include <stdio.h>
int main()
{
int pid, status;
pid = fork();
if(pid == -1) // fork falhou
{
perror("fork falhou!");
exit(-1);
}
else if(pid == 0) // Este é o processo filho
{
pid = fork();
if(pid == -1)
{
perror("fork falhou!");
exit(-1);
}
else if(pid == 0) // Este é o filho do filho
{
sleep(1);
printf("Eu sou o processo C (PID %d), filho de %d\n", getpid(), getppid());
exit (0);
}
else
{
wait(&status);
sleep(1);
printf("Eu sou o processo B (PID %d), filho de %d\n", getpid(), getppid());
exit(0);
}
}
else // Este é o processo pai
{
wait(&status);
sleep(1);
printf("Eu sou o processo A (PID %d), filho de %d\n", getpid(), getppid());
exit(0);
}
}
</syntaxhighlight>
- DESAFIO
- fork/wait
Reimplementar o exercício anterior de criação de uma árvore de 3 processos, generalizando a criação de N processos onde N é repassado na linha de comando do programa. SUGESTÃO: usar um comando for, mas lembrar que se existe um fork dentro do for, então cada filho gerado dará continuidade a execução do for. É necessário que o processo faça um exit ou retorne neste momento.
- DESAFIO
- Exercício status/wait
O status passado como parâmetro à função wait(&status) é, na verdade, o mecanismo de retorno de resultado do wait/waitpid. Ao retornar, esta variável contém informações sobre o resultado da execução do processo filho. Por exemplo, se um processo terminou normalmente (i.e., chamou exit), o comando WIFEXITED(status) retorna true. Este comando retorna false se o processo foi abortado (e.g., segmentation fault) ou morto (e.g., kill). Investigue no manual do wait no Linux (man wait) o funcionamento do comando WEXITSTATUS(status).
Imagine um problema de busca de dados armazenados na forma de uma matriz de inteiros 4x30. Você está interessado em saber quantas ocorrências de um determinado número existe em cada linha da matriz. Note que que são tarefas que podem ser paralelizadas e usufruir de um sistema capaz de executá-las em paralelo. Faça uma implementação paralelizando 4 processos filhos a partir de um pai, onde cada processo é responsável por uma busca. A quantidade de ocorrências do número buscado é retornada e capturada através de WEXITSTATUS.
- Syscall EXEC
- Exemplo exec()
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
execl("/bin/ls","ls","-l", NULL);
return 0;
}
- Exercício 1: Modificar o código para mostrar que o exec() não retorna (colocar um printf após o exec).
- Exercício 2: Criar um exemplo (dois programas ) para demonstrar que o exec não cria novo processo.
- Crie um primeiro programa (prog1) que imprime o seu pid e depois faz um exec do segundo programa.
- Crie o segundo programa que simplesmente imprime o pid.
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("EU ANTES DO EXEC: Meu pid é %d\n", getpid());
execl("./prog2","prog2", NULL);
return 0;
}
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("EU DEPOIS DO EXEC:Meu pid é %d\n", getpid());
return 0;
}
- Exercício 3: Criar um exemplo usando fork/exec mostrando que um processo pai cria um filho e espera por sua execução. O filho executa o comando "ps aux". Ambos devem mostrar seus pids.
Threads de aplicação
Threads de aplicação
O Linux, através da API POSIX, oferece um conjunto de funções que permite às aplicações manipular contextos, facilitando a vida do programador que quer implementar tarefas "simultâneas" dentro de um único processo, ou seja, threads. As seguintes funções e tipos estão disponíveis:
- getcontext(&a): salva o contexto na variável a;
- setcontext(&a): restaura um contexto salvo anteriormente na variável a;
- swapcontext(&a,&b): salva o contexto atual na variável a e restaura o contexto salvo anteriormente na variável b;
- makecontext(&a, ...): ajusta parâmetros internos do contexto salvo em a;
- ucontext_t: as variáveis a e b são do tipo ucontext_t. Este tipo armazena um contexto.
Busque mais informações sobre estas funções utilizando o programa manpage do Linux (ex.: man getcontext).
Estude o código no arquivo pingpong.c abaixo e explique seu funcionamento.
#include <stdio.h>
#include <stdlib.h>
#include <ucontext.h>
#define STACKSIZE 32768 /* tamanho de pilha das threads */
/* VARIÁVEIS GLOBAIS */
ucontext_t cPing, cPong, cMain;
/* Funções-comportamento das Tarefas */
void f_ping(void * arg) {
int i;
printf("%s iniciada\n", (char *) arg);
for (i=0; i<4; i++) {
printf("%s %d\n", (char *) arg, i);
swapcontext(&cPing, &cPong);
}
printf("%s FIM\n", (char *) arg);
swapcontext(&cPing, &cMain);
}
void f_pong(void * arg) {
int i;
printf("%s iniciada\n", (char *) arg);
for (i=0; i<4; i++) {
printf("%s %d\n", (char *) arg, i);
swapcontext(&cPong, &cPing);
}
printf("%s FIM\n", (char *) arg);
swapcontext(&cPong, &cMain);
}
/* MAIN */
int main(int argc, char *argv[]) {
char *stack;
printf ("Main INICIO\n");
getcontext(&cPing);
stack = malloc(STACKSIZE);
if(stack) {
cPing.uc_stack.ss_sp = stack ;
cPing.uc_stack.ss_size = STACKSIZE;
cPing.uc_stack.ss_flags = 0;
cPing.uc_link = 0;
}
else {
perror("Erro na criação da pilha: ");
exit(1);
}
makecontext(&cPing, (void*)(*f_ping), 1, "\tPing");
getcontext(&cPong);
stack = malloc(STACKSIZE);
if(stack) {
cPong.uc_stack.ss_sp = stack ;
cPong.uc_stack.ss_size = STACKSIZE;
cPong.uc_stack.ss_flags = 0;
cPong.uc_link = 0;
}
else {
perror("Erro na criação da pilha: ");
exit(1);
}
makecontext (&cPong, (void*)(*f_pong), 1, "\tPong");
swapcontext(&cMain, &cPing);
swapcontext(&cMain, &cPong);
printf("Main FIM\n");
exit(0);
}
- Exercício 1: Primeiramente compile e execute o código. Agora estude o código e entenda completamente o seu funcionamento. Explique em DETALHES o código, comentando todas as linhas. Na seção de diagrama do seu relatório, desenhe um diagrama de funcionamento do código para mostrar exatamente como acontece a troca de contexto entre as threads.
- Exercício 2: Acrescente um procedimento f_new que receba 4 strings como parâmetros e imprima todas na tela. Antes do final da execução do main faça uma mudança de contexto para chamar o procedimento criado.
Exercício 3: O que acontece se um dos threads é colocado para dormir? Todos os demais threads param a sua execução.
Exercício 4: Note que um thread somente deixa a execução para outro thread de forma explícita. Será que é possível realizar um escalonamento de threads de forma similar ao que o kernel faz com os processos? Ver http://www.cplusplus.com/forum/unices/6452/
Trocas de mensagens com pipes
Trocas de mensagens com pipes
- Troca de mensagens
Um mecanismo disponibilizado por sistemas UNIX para troca de mensagens entre processos é o PIPE. Pipes são mecanismos de comunicação indireta onde mensagens são trocadas através de mailboxes. Cada mailbox possui um identificador único, permitindo que processos identifiquem o canal de comunicação entre eles. O fluxo de mensagens em um Pipe é:
- unidirecional: sobre um mesmo pipe, apenas um processo envia mensagens e um processo recebe mensagens;
- FIFO: as mensagens são entregues na ordem de envio;
- não-estruturado: não há estrutura pré-definida para o formato da mensagem.
No UNIX, pipes são inicializados através da SystemCall pipe, que possui a seguinte sintaxe:
- int pipe(int pipefd[2]): pipe inicializa um novo pipe no sistema e retorna, no array pipefd, os descritores identificando cada uma das pontas do pipe. A primeira posição do array, i.e. pipefd[0], recebe o descritor que pode ser aberto apenas para leitura, enquanto a segunda posição do array, i.e. pipefd[1], recebe o descritor que pode ser aberto apenas para escrita. A função retorna zero no caso de sucesso, ou -1 se ocorrer erro.
As primitivas send/receive para uso de um pipe no UNIX são implementadas por SystemCalls read/write, conforme segue:
- ssize_t read(int fd, void *buf, size_t count): “puxa” dados do pipe identificado pelo descritor fd. Os dados recebidos são os apontados pelo ponteiro buf, sendo count a quantidade máxima de bytes a serem recebidos. A função retorna o número de bytes recebidos.
- ssize_t write(int fd, const void *buf, size_t count): “empurra” dados no pipe identificado pelo descritor fd. Os dados transmitidos são os apontados pelo ponteiro buf, sendo count a quantidade de bytes a serem transmitidos. A função retorna o número de bytes transmitidos.
- Exemplo 1: Transmitindo e recebendo pelo próprio processo
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/stat.h>
#define SHM_SIZE 1024
int main()
{
int fd[2];
char *ptr = "Alo eu mesmo";
char *ptr_alvo;
int tamanho_dados, ret;
tamanho_dados = strlen(ptr)+1;
if (pipe(fd)==-1){
printf ("erro criação pipe\n");
exit(-1);
}
printf("Transmitido %d bytes\n", tamanho_dados);
write (fd[1], ptr, tamanho_dados);
ptr_alvo = malloc(tamanho_dados);
ret=read(fd[0],ptr_alvo,tamanho_dados);
printf("ret = %d dados => %s\n", ret, ptr_alvo);
return 0;
}
- Exemplo 2: Abaixo há um exemplo de programa criando um pipe e compartilhando os descritores entre dois processos (criados via fork()).
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
char *message = "This is a message!!!" ;
main()
{
char buf[1024] ;
int fd[2];
pipe(fd); /*create pipe*/
if (fork() != 0) { /* I am the parent */
write(fd[1], message, strlen (message) + 1) ;
}
else { /*Child code */
read(fd[0], buf, 1024) ;
printf("Got this from MaMa!!: %s\n", buf) ;
}
}
- Exercício 1: construa um “pipeline”. Crie um programa que conecta 4 processos através de 3 pipes. Utilize fork() para criar vários processos.
//Solução possível
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
char *message = "This is a message to send!!!" ;
main()
{
int size = strlen(message)+1;
char buf[size];
char buf1[size];
char buf2[size];
int status;
int fd[2];
pipe(fd);
if (fork() != 0) { /* I am the parent */
printf("Processo A PID: %d\n", getpid());
write(fd[1], message, size);
wait(&status);
}
else { /*Child code */
int status1;
int fd1[2];
pipe(fd1);
if (fork() != 0) { /* I am the parent */
printf("Processo B PID: %d\n", getpid());
read(fd[0], buf, size);
write(fd1[1], buf, size);
wait(&status1);
}else { /*Child code */
int status2;
int fd2[2];
pipe(fd2);
if (fork() != 0) { /* I am the parent */
printf("Processo C PID: %d\n", getpid());
read(fd1[0], buf1, size);
write(fd2[1], buf1, size);
wait(&status2);
}else { /*Child code */
printf("Processo D PID: %d\n", getpid());
read(fd2[0], buf2, size);
printf("\n Mensagem -> %s <- \n ", buf2);
}
}
}
exit(0);
}
- Exercício 3: Modifique o exercício anterior para que o processo D, através de um novo pipe, mande uma mensagem diretamente para o pai de todos.
- Exercício 3: Consultor de Login de Acesso:. Estude o link https://www.geeksforgeeks.org/named-pipe-fifo-example-c-program/ e projete um programa cliente servidor da seguinte forma: (i) O servidor possui uma tabela de usuários (userid). O user_id é de tamanho fixo de 7 caracteres. O servidor espera por consultas para verificar se um usuário está na tabela. Se estiver responde com o caracter 'S' senão com 'N'. (ii) O cliente espera por user_id no teclado e consulta o servidor sobre sua existência na tabela. O cliente imprime na tabela a existência ou não do usuário.
- Exercício 4: cópia de arquivo. Projete um programa de cópia de arquivos chamado FileCopy usando pipes comuns. Esse programa receberá dois parâmetros: o primeiro é o nome do arquivo a ser copiado e o segundo é o nome do arquivo copiado. Em seguida, o programa criará um pipe comum e gravará nele o conteúdo do arquivo a ser copiado. O processo filho lerá esse arquivo do pipe e o gravará no arquivo de destino. Por exemplo, se chamarmos o programa como descrito a seguir:
$ FileCopy entrada.txt copia.txt
- o arquivo entrada.txt será gravado no pipe. O processo filho lerá o conteúdo desse arquivo e o gravará no arquivo de destino copia.txt. Escreva o programa usando os pipes da API POSIX no Linux.
Exercícios sobre Memória Compartilhada
SH_MEMORY
Memória Compartilhada
- Experimento Shared Memory: Complete o código a seguir para que os processos pai e filho possam compartilhar um segmento de memória. O filho escreve no segmento e o pai imprime na tela o conteúdo da mensagem.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/stat.h>
#define SHM_SIZE 1024
int main(int argc, char *argv[])
{
key_t key;
int shmid;
char *segmento;
int modo,filho;
shmid = shmget(IPC_PRIVATE, SHM_SIZE, S_IRUSR | S_IWUSR);
if (shmid == -1) {
perror("shmget");
exit(1);
}
segmento = shmat(shmid, (void *)0, 0);
if (segmento == (char *)(-1)) {
perror("shmat");
exit(1);
}
if((filho = fork()) == -1)
{
perror("fork");
exit(1);
}
if(filho == 0)
{
char *ptr_msg = "alo pai, tudo bem?";
printf("Filho escrevendo no segmento compartilhado\n\n");
//completar aqui strcpy(segmento, ptr_msg); //aqui deveria testar a cpacidade da área...
exit(0);
}
else
{
wait(filho);
printf("Mensagem para o pai: %s\n", segmento);
}
if (shmdt(segmento) == -1) {
perror("shmdt");
exit(1);
}
return 0;
}
- Exemplo com ftok:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define SHM_SIZE 1024
int main(int argc, char *argv[])
{
key_t key;
int shmid;
char *segmento;
int modo,filho;
key = ftok("./teste.txt", 'A'); /*O arquivo deve existir de verdade*/
if (key == -1)
{
perror("ftok");
exit(1);
}
shmid = shmget(key, SHM_SIZE, (0644 | IPC_CREAT));
if (shmid == -1) {
perror("shmget");
exit(1);
}
segmento = shmat(shmid, (void *)0, 0);
if (segmento == (char *)(-1)) {
perror("shmat");
exit(1);
}
if((filho = fork()) == -1)
{
perror("fork");
exit(1);
}
if(filho == 0)
{
printf("Filho escrevendo no segmento compartilhado\n\n");
strncpy(segmento, "mensagem compartilhada", SHM_SIZE);
exit(0);
}
else
{
wait(filho);
printf("Mensagem para o pai: %s\n", segmento);
}
if (shmdt(segmento) == -1) {
perror("shmdt");
exit(1);
}
return 0;
}
- Exemplo com ftok entre processos sem parentesco:
Criar um arquivo teste.txt e em um terminal executar:
#define SHM_SIZE 1024
int main(int argc, char *argv[])
{
key_t key;
int shmid;
int modo,filho;
struct minha_struct {
char flag;
int numero;
} *ptr;
key = ftok("./teste.txt", 'A'); /*O arquivo deve existir de verdade*/
if (key == -1)
{
perror("ftok");
exit(1);
}
shmid = shmget(key, SHM_SIZE, (0644 | IPC_CREAT));
if (shmid == -1) {
perror("shmget");
exit(1);
}
ptr = (struct minha_struct *) shmat(shmid, (void *)0, 0);
if ((char *)ptr == (char *)(-1)) {
perror("shmat");
exit(1);
}
ptr->flag =0;
ptr->numero = 0;
while (ptr->flag==0) {
printf("%d\n", ptr->numero);
sleep(1);
}
if (shmdt(ptr) == -1) {
perror("shmdt");
exit(1);
}
return 0;
}
Em outro terminal executar:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define SHM_SIZE 1024
int main(int argc, char *argv[])
{
key_t key;
int shmid;
char *segmento;
int modo,filho;
struct minha_struct {
char flag;
int numero;
} *ptr;
key = ftok("./teste.txt", 'A'); /*O arquivo deve existir de verdade*/
if (key == -1)
{
perror("ftok");
exit(1);
}
shmid = shmget(key, SHM_SIZE, (0644));
if (shmid == -1) {
perror("shmget");
exit(1);
}
ptr = (struct minha_struct *) shmat(shmid, (void *)0, 0);
if ((char *)ptr == (char *)(-1)) {
perror("shmat");
exit(1);
}
while (ptr->numero++<10)
sleep(1);
ptr->flag = 1;
return 0;
}
Exercício Desafio: Implementar o problema do buffer circular usando memória compartilhada.
Exercício (Algoritmo de Peterson)
Exercício (Algoritmo de Peterson)
Exercício 1: Sincronize o código a seguir, de maneira que o processo pai imprima apenas os números impares e o processo filho os números pares. Para isso utilize o algoritmo de Peterson visto em aula. Utilize memória compartilhada para comunicação entre os processos.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
main()
{
if (fork() != 0) { /* I am the parent */
int i;
for(i = 0;i < 10;i=i+2){
printf("Processo pai %d \n", i);
}
}
else { /*Child code */
int i;
for(i = 1;i < 10;i=i+2){
printf("Processo filho %d \n", i);
}
}
exit(0);
}
Exercício 2: Considerando o exercício anterior faça a mesma sincronização, no entanto desta vez utilize a modelagem em software do TSL.
- Em sua experiência, depois de testar diversas vezes as execuções de suas soluções baseadas no algoritmo de Peterson e Tsl, qual sua opinião sobre as abordagens?
Explique seu raciocínio.
Exercício (Semáforos)
Exercício (Semáforos)
Exercício 1: Sincronize o código a seguir, de maneira que o processo pai imprima apenas os números impares e o processo filho os números pares. Para isso utilize Semáforos de acordo com a implementação em semaforo.h. Utilize memória compartilhada para comunicação entre os processos.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
main()
{
if (fork() != 0) { /* I am the parent */
int i;
for(i = 0;i < 10;i=i+2){
printf("Processo pai %d \n", i);
sleep(1);
}
}
else { /*Child code */
int i;
for(i = 1;i < 10;i=i+2){
printf("Processo filho %d \n", i);
}
}
exit(0);
}
SEMAFORO.H
#include <sys/sem.h>
int criar_semaforo(int val, int chave)
{
int semid ;
union semun {
int val;
struct semid_ds *buf ;
ushort array[1];
} arg_ctl ;
key_t ft = ftok("/tmp", chave);
semid = semget(ft,1,IPC_CREAT|IPC_EXCL|0666);
if (semid == -1) {
semid = semget(ft,1,0666);
if (semid == -1) {
perror("Erro semget()");
exit(1) ;
}
}
arg_ctl.val = val; //valor de início
if (semctl(semid,0,SETVAL,arg_ctl) == -1) {
perror("Erro inicializacao semaforo");
exit(1);
}
return(semid) ;
}
void P(int semid){
struct sembuf *sops = malloc(10*sizeof(int));
sops->sem_num = 0;
sops->sem_op = -1;
sops->sem_flg = 0;
semop(semid, sops, 1);
free(sops);
}
void V(int semid){
struct sembuf *sops = malloc(10*sizeof(int));
sops->sem_num = 0;
sops->sem_op = 1;
sops->sem_flg = 0;
semop(semid, sops, 1);
free(sops);
}
void sem_delete(int semid)
{
if (semctl(semid,0,IPC_RMID,0) == -1)
perror("Erro na destruicao do semaforo");
}
Programação concorrente
Programação concorrente
- POSIX Threads
A API POSIX disponibiliza uma biblioteca de threads chamada pthread. As threads são implementadas pela estrutura pthread_t, e manipuladas pelas funções (acesse as man-pages das chamadas para maiores detalhes):
- pthread_create: cria uma thread;
- pthread_kill: força a terminação de uma thread;
- pthread_join: sincroniza o final de uma thread (qual a diferença/semelhança com o wait que usamos para processos?);
- pthread_exit: finaliza uma thread.
Para utilizar estas funções é necessário linkar o programa à libpthread (-lpthread).
- POSIX pthread mutex
A biblioteca pthread implementa um tipo pthread_mutex_t, que garante a exclusão mútua entre threads. Estes mutex são manipulados através das funções (acesse as man-pages das chamadas para maiores detalhes):
- pthread_mutex_lock: acessa um mutex.
- pthread_mutex_trylock: tenta acessar um mutex (retorna valor indicando sucesso ou falha no lock).
- pthread_mutex_unlock: libera um mutex.
- POSIX Semaphores
Nos sistemas POSIX, semáforos são implementados pelo tipo sem_t e manipulado através das funções (acesse as man-pages das chamadas para maiores detalhes):
- sem_init: inicializa um semáforo;
- sem_destroy: destroy um semáforo;
- sem_wait: implementa a operação p;
- sem_post: implementa a operação v.
Para utilizar estas funções é necessário linkar o programa à librt ou à libpthread (-lrt ou -lpthread).
- Exercício 1
O programa abaixo cria 5 threads, e cada uma destas threads atualiza uma variável global (memória compartilhada).
#include <iostream>
#include <pthread.h>
#include <signal.h>
#define NUM_THREADS 5
using namespace std;
pthread_mutex_t mut;
int saldo = 1000;
int AtualizaSaldo(int n)
{
int meu_saldo = saldo;
int novo_saldo = meu_saldo + n*100;
cout << "Novo saldo = " << novo_saldo << endl;
saldo = novo_saldo;
}
int main()
{
pthread_t threads[NUM_THREADS];
int i,ret;
// Cria cinco threads que executarão a mesma função
for(i=0; i<5; ++i){
ret = pthread_create(&threads[i], NULL, (void*(*)(void*))AtualizaSaldo,(void*)((long)i+1));
if(ret != 0){
fprintf(stderr, "Erro thread %d. Código %d: %s\n", (i+1), ret, strerror(ret));
exit(EXIT_FAILURE);
}
}
// Aguarda o fim das threads
for(i=0; i<5; ++i)
pthread_join(threads[i], NULL);
cout << "Saldo final é " << saldo << "." << endl;
}
- Compile este programa.
- Execute este programa várias vezes. Ele funciona? Será que ele gera as saídas esperadas?
- Identifique as seções críticas do programa.
- Corrija o programa utilizando mutex.
- Analise a função AtualizaSaldo() com a sua solução. Lembre-se que o uso do mutex implica em apenas uma thread acessar a seção crítica por vez, enquanto outras threads ficam bloqueadas, esperando. Disso vem que, quanto menor o trecho de código entre um lock e um unlock, menos tempo uma thread necessita ficar esperando.
- Modifique o programa para usar um semáforo binário ao invés de um mutex em sua solução.
- Exercício 2
Refaça o exercício 3 usando processos criados com fork e exec. O semáforo deve ser criado em uma região de memória compartilhada.
- Exercício 3
Implemente com pthreads e semáforos/mutex a solução do produtor/comsumidor.
- Exercício 4
O programa abaixo manipula uma matriz de tamanho MxN (veja os defines para o tamanho da matriz). A função SumValues soma todos os valores em uma linha da matriz. A linha a ser somada é identificada pela variável i. Modifique o programa principal (main) nos locais indicados para:
- Criar N threads, uma para somar os valores de cada linha.
- Receber o resultado do somatório de cada linha e gerar o somatório total da matriz.
- Analise o programa: há problemas de sincronização que precisam ser resolvidos? Se sim, resolva-os.
#include <iostream>
#include "thread.h"
/* number of matrix columns and rows */
#define M 5
#define N 10
using namespace std;
int matrix[N][M];
Thread *threads[N];
/* thread function; it sums the values of the matrix in the row */
int SumValues(int i)
{
int n = i; /* number of row */
int total = 0; /* the total of the values in the row */
int j;
for (j = 0; j < M; j++) /* sum values in the "n" row */
total += matrix[n][j];
cout << "The total in row" << n << " is " << total << "." << endl;
/* terminate a thread and return a total in the row */
exit(total);
}
int main(int argc, char *argv[])
{
int i, j;
int total = 0; /* the total of the values in the matrix */
/* initialize the matrix */
for (i = 0; i < N; i++)
for (j = 0; j < M; j++)
matrix[i][j] = i * M + j;
/* create threads */
/* COLOQUE SEU CÓDIGO PARA CRIAR AS THREADS AQUI! */
/* wait for terminate a threads */
/* COLOQUE SEU CÓDIGO PARA PEGAR O SOMATÓRIO DE LINHAS E TOTALIZAR A SOMA DA MATRIZ AQUI! */
cout << "The total values in the matrix is " << total << endl;
return 0;
}
Lista de exercícios "Revisão para Prova"
Lista de exercícios/Revisão para Prova
A lista de exercícios referente a primeira prova (Parte introdutória + Processos) segue neste LINK | Lista de exercícios.
Primeiro trabalho
JOGO DA VIDA DE CONWAY e JANTAR DOS FILÓSOFOS
- Referências
A partir da implementação sequencial do Game of Life apresentada a seguir, estude o código e transforme esta implementação em uma implementação paralela utilizando o protocolo de passagem de mensagens MPI.
Perceba que a impĺementação mencionada utiliza como parâmetros de entrada um aquivo contendo o estado inicial do jogo, e o número de gerações que o usuário deseja rodar. A evolução do estado inicial
é impressa na tela passo a passo. Sendo assim, a partir disso:
- 1: Elabore uma implementação com 2 processos para o jogo da vida utilizando o protocolo MPI, de maneira que um processo execute uma geração i qualquer e o outro execute a geração seguinte i+1
- 2: (0,7) Os processos deverão se comunicar utilizando as funções do protocolo MPI.
- 3: (0,3) Relatório simplificado explicando a sua solução. Utilize diagramas para representar a comunicação entre os processos, explicando como a matriz do jogo é transferida entre os processos.
- 4: Entregue o Relatório e o código fonte do trabalho em um pacote compactado via e-mail (PRAZO 19/10).
- Compilar o código com MPI
mpicc -o nomeApp arquivo.c
</syntaxhighlight>
- Rodar rodar programa utilizando MPI
mpirun -np numeroDeProcessos ./nomeApp entrada.txt gerações
</syntaxhighlight>
* (int) -np: Quantidade de processos que você deseja executar
* entrada.txt: Arquivo de entrada com estado inicial do jogo
* (int) gerações: número de gerações que você deseja rodar
* Arquivo de entrada para Testes
/*
Conway's Game of Life
Compilar código com MPI
mpicc -o nomeApp arquivo.c
Rodar rodar programa utilizando MPI
mpirun -np numeroDeProcessos ./nomeApp entrada.txt gerações
(int) -np: Quantidade de processos que você deseja executar
entrada.txt: Arquivo de entrada com estado inicial do jogo
(int) gerações: número de gerações que você deseja rodar
*/
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include "mpi.h"
//Numero de linhas e colunas
#define nLinhas 32
#define nColunas 82
char *matriz[nLinhas];
char *entrada[nLinhas];
void iniciar() {
int i;
//Alocar espaço em memória para as matrizes
for (i = 0; i < nLinhas; i++ )
matriz[i] = (char *) malloc((nColunas) * sizeof( char ));
}
int adjacente(char **matriz, int i, int j){
int x,y, initX, initY, limitX, limitY;
int vizinhos = 0;
if(i == 0)
initX = 0;
else
initX = -1;
if(i == (nLinhas-1))
limitX = 1;
else
limitX = 2;
if(y == 0)
initY = 0;
else
initY = -1;
if(y == (nColunas-3))
limitY = 1;
else
limitY = 2;
for(x = initX ; x < limitX; x++){
for(y = initY; y < limitY; y++){
if(matriz[i+x][j+y] == '#')
vizinhos++;
}
}
if(matriz[i][j] == '#')
return (vizinhos-1);
else
return vizinhos;
}
void calculoGeracao(char **matriz, int ger) {
int i, j, a;
char novaGeracao[nLinhas][nColunas];
/* Aplicando as regras do jogo da vida */
for (i=0; i < nLinhas; i++){
for (j=0; j < nColunas; j++) {
a = adjacente(matriz, i, j);
if (a == 2) novaGeracao[i][j] = matriz[i][j];
if (a == 3) novaGeracao[i][j] = '#';
if (a < 2) novaGeracao[i][j] = ' ';
if (a > 3) novaGeracao[i][j] = ' ';
if (j == 0)
novaGeracao[i][j] = '"';
}
novaGeracao[i][79] = '"';
novaGeracao[i][80] = '\n';
}
/* Passando o resultado da nova geração para a matriz de entrada */
for (i=0; i < nLinhas; i++){
for (j=0; j < nColunas; j++)
matriz[i][j] = novaGeracao[i][j];
}
}
main(int argc, char *argv[2]){
/* Para uso com MPI
//Variáveis para uso com MPI
int numeroDeProcessos = 0;
int rank = 0;
MPI_Status status;
//Iniciar MPI---
MPI_Init( &argc, &argv );
//Atribui a variável numeroDeProcessos o número de processos passado como parâmetro em -np
MPI_Comm_size( MPI_COMM_WORLD, &numeroDeProcessos );
//Pega o valor do rank (processo)
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
*/
FILE *matrizEntrada;
matrizEntrada = fopen(argv[1], "r");
iniciar();
if (matrizEntrada == NULL)
printf ("Não posso abrir o arquivo \"%s\"\n", argv[1]);
char str[nColunas];
int linha = 0;
//Lendo o estado inicial do jogo a partir do arquivo
while((fgets(str, nColunas, matrizEntrada) != NULL)&&(linha < nLinhas)){
strcat(matriz[linha], str);
linha++;
}
int i,gens;
for(gens = 0; gens < atoi(argv[2]); gens++){ //Gens é o número de gerações especificado no segundo parâmetro
calculoGeracao(matriz, gens);
printf("%c[2J",27); // Esta linha serve para limpar a tela antes de imprimir o resultado de uma geração
//Lendo o estado do jogo e imprime na tela
for(i = 0; i < nLinhas; i++)
printf("%s", matriz[i]);
sleep(1);
}
for(i = 0; i < nLinhas; i++)
free(matriz[i]);
/* Finaliza o MPI */
//MPI_Finalize();
exit(0);
}
- Jantar dos Filósofos
O problema clássico Jantar dos Filósofos consiste em que n fluxos (n filósofos) disputam n recursos (n talheres). No problema, para conseguir "jantar" (ou executar), cada filósofo precisa pegar dois talheres adjascentes a ele. Cada recurso é compartilhado por dois filósofos.
- (0,7) programa abaixo implementa um Jantar dos Filósofos utilizando semáforos para sincronização. Contudo, as chamadas para as operações v e p foram removidas, conforme comentários no código. Re-insira as operações no código e analise a solução. Esta modificação é suficiente para garantir que não haverá deadlock? Se sim, mostre o porque. Se não, proponha uma solução completa.
- (0,3) Relatório simplificado explicando a sua solução.
- Entregue o Relatório e o código fonte do trabalho em um pacote compactado via e-mail (PRAZO 19/10).
#include <iostream>
#include "thread.h"
#include "semaphore.h"
using namespace std;
const int DELAY = 10000000;
const int ITERATIONS = 5;
Semaphore chopstick[5];
int philosopher(int n)
{
cout << "Philosopher " << n << " was born!\n";
int first = (n < 4)? n : 0; // left for phil 0 .. 3, right for phil 4
int second = (n < 4)? n + 1 : 4; // right for phil 0 .. 3, left for phil 4
// Foram removidos do laço abaixo:
// - uma chamada para chopstick[first].p()
// - uma chamada para chopstick[second].p()
// - uma chamada para chopstick[first].v()
// - uma chamada para chopstick[second].v()
for(int i = 0; i < ITERATIONS; i++) {
cout << "Philosopher " << n << " thinking ...\n";
for(int i = 0; i < DELAY * 10; i++);
cout << "Philosopher " << n << " eating ...\n";
for(int i = 0; i < DELAY; i++);
}
return n;
}
int main()
{
cout << "The Dining-Philosophers Problem\n";
Thread * phil[5];
for(int i = 0; i < 5; i++)
phil[i] = new Thread(&philosopher, i);
int status;
for(int i = 0; i < 5; i++) {
phil[i]->join(&status);
if(status == i)
cout << "Philosopher " << i << " went to heaven!\n";
else
cout << "Philosopher " << i << " went to hell!\n";
}
return 0;
}
Softwares básicos, caso Hello Word! (Trabalho 2) Entrega dia 09/11
Softwares básicos, caso Hello Word!
O objetivo do experimento de hoje é pesquisar e entender os processos de atribuição de endereços de programas realizados em tempo de compilação pelos softwares básicos como: compilador, linker, e assembler. Sendo assim, neste experimento vamos utilizar os seguintes softwares para criação e análise de código:
- GCC: compilador para gerar código objeto a partir de um código de programa escrito na linguagem c;
- GNU Linker (LD): Para vincular os códigos (módulos) objetos do programa;
- Linker
- GNU Assembler: Para gerar o código executável a partir do código objeto;
- | assembler
- OBJDUMP: Para mostrar informações do código;
- | Objdump
A seguir segue descrito o programa a ser utilizado no exercício 1:
#include <stdio.h>
int main()
{
printf("Hello, World!");
return 0;
}
Trata-se do programa hello word, este programa apenas exibe uma mensagem na tela. No entanto, vamos analisar como são as etapas confecção do executável a partir deste código simples.
Exercício 1:
- Compile o programa hello word, e o transforme em código objeto utilizando o programa GCC. Para esta tarefa execute o seguinte comando:
gcc -o hello hello.c
</syntaxhighlight>
- Agora abra o código objeto utilizando o programa OBJDUMP.
objdump -D hello
</syntaxhighlight>
- Identifique quais são as seções de código obtidas a partir do hello.c.
- Pesquise e entenda o significado das seções de código: .bss, .txt, .data, .init.
- Faça uma análise e identifique o endereço de memória que o programa hello world vai ser carregado.
- Este código objeto é relocável? Justifique sua resposta.
- Agora gere o código assembly do hello world.
gcc -S hello.c
</syntaxhighlight>
- Agora gere o código executável utilizando o programa AS e o programa LD.
as -o hello.o hello.s
</syntaxhighlight>
- Como a etapa de linkagem para a construção do código executável está sendo executada sem o auxílio do GCC, necessitamos vincular manualmente as bibliotecas necessárias. Para criar apropriadamente o executável vamos precisar das bibliotecas ld-linux-x86-64.so.2, crt1.o, crti.o, crtn.o.
- Para descobrir suas respectivas localizações use o comando LOCATE. Por exemplo:
locate crti.o
</syntaxhighlight>
ou
find /usr/ -name crti*
</syntaxhighlight>
- Agora que já sabemos a localização das bibliotecas necessárias vamos vincular essas a nossa aplicação.
ld --dynamic-linker /caminho/ld-linux-x86-64.so.2 /caminho/crt1.o /caminho/crti.o /caminho/crtn.o hello.o -lc -o hello.exe
</syntaxhighlight>
- Agora abra o código objeto utilizando o programa OBJDUMP.
- Faça uma análise e identifique o endereço de memória em que o programa hello world inicializa suas estruturas na memória.
- Dica!
objdump -D -s -j .init hello.exe
</syntaxhighlight>
- Houve diferença entre os endereços do programa executável em relação ao código objeto? Explique.
- Explique as principais diferenças entre o arquivo objeto .o e o executável final. (dica utilize o objdump para fazer essa análise)
Links Interessantes

