| Animação
|
 |} |}
|
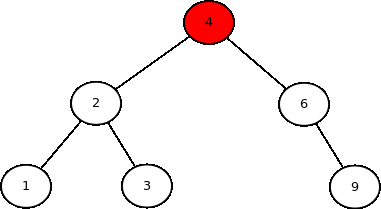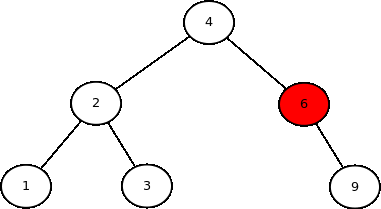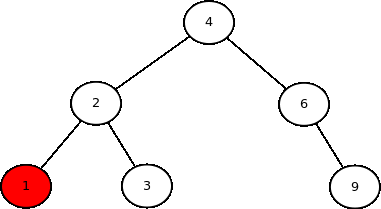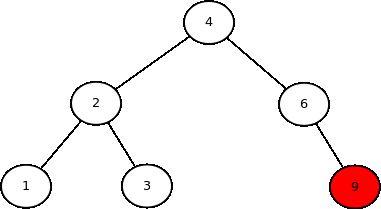
As três primeiras formas de acesso são do tipo busca em profundidade, pois implicam descer até as folhas de um lado antes de visitarem o outro lado da árvore. A última forma de acesso é do tipo busca em largura, pois os nodos são visitados por nível da árvore.
Cada uma das formas de acesso tem sua aplicações em algoritmos. Por exemplo, in order serve para ordenar os dados, pre order pode ser usada para copiar uma árvore, e post order pode ser usado para destruir uma árvore. Alguns algoritmos já criados usam algumas dessas formas de acesso (ex: escrevaSe é do tipo in order; o destrutor da árvore e altura são do tipo post order). Hoje será visto como implementar métodos genéricos que enumeram os dados de uma árvore segundo essas sequências de acesso.
void listeInOrder(lista<T> & result);
void listePreOrder(lista<T> & result);
void listePostOrder(lista<T> & result);
void listeEmLargura(lista<T> & result);
| um algoritmo para listePreOrder em versão não-recursiva
|
|
A versão não-recursiva de listePreOrder precisa de uma pilha para navegar pelos nodos da árvore.
algoritmo PRE_ORDER:
empilha raiz
enquanto pilha não vazia faça
desempilha um nodo
faz algo com nodo
se nodo tem ramo direito então empilha ramo direito
se nodo tem ramo esquerdo então empilha ramo esquerdo
fim enquanto
fim algoritmo
template <typename T> void arvore<T>::listePreOrder(lista<T> & result) {
// OBS: com a lista funcionando como pilha,
// push <==> insere(algo), pop <==> remove(0)
lista<arvore<T>*> q; // pilha de nodos a visitar
q.insere(this); // inicia com a raiz
while (not q.vazia()) { // repete até que pilha fique vazia
// desempilha um nodo
// anexa em result dado do nodo desempilhado
// se nodo tem ramo direito, empilha-o
// se nodo tem ramo esquerdo, empilha-o
}
}
|
As versões não-recursivas desses algoritmos podem ser facilmente encontradas em forums de programadores, e também na Wikipedia:
Iteração da árvore
A iteraçao da árvore na Prglib original possibilita obter de forma ordenada os dados contidos na árvore. Assim, a iteração segue uma enumeração dos dados no estilo in-order. Para implementá-la deve-se usar um algoritmo não-recursivo, visto que cada chamada do iterador, por meio do método proximo, retorna um único dado.
Um algoritmo para enumeração in-order faz uso de uma pilha como estrutura de dados auxiliar. Sendo assim, a classe arvore precisa possuir uma pilha como um novo atributo. Para economizar memória, já que todo nodo da árvore possuirá esse novo atributo, a pilha deve ser criada dinamicamente quando se inicia uma iteração, e destruída ao final da iteração. Para isso a pilha deve ser declarada como o ponteiro p_stack na classe arvore:
| Declaração da arvore em libs/arvore.h contendo o atributo para a pilha
|
#ifndef ARVORE_H
#define ARVORE_H
namespace prglib {
template <typename T> class arvore {
public:
arvore();
//arvore(const arvore<T> & outra);
arvore(const T & dado);
virtual ~arvore();
void adiciona(const T& algo);
T& obtem(const T & algo);
void listeInOrder(lista<T> & result);
void listePreOrder(lista<T> & result);
void listePostOrder(lista<T> & result);
void listeEmLargura(lista<T> & result);
unsigned int tamanho() const;
unsigned int altura() ;
int fatorB() ;
arvore<T> * balanceia();
arvore<T> * balanceia(bool otimo);
// iterador in-order
void inicia();
bool fim();
T& proximo();
// iterador in-order reverso
void iniciaPeloFim();
bool inicio();
T& anterior();
// remove um dado equivalente a "algo", retornando uma cópia
T remove(const T & algo);
// obtém maior ou menor dados contidos na árvore
T & obtemMenor() const;
T & obtemMaior() const;
void obtemMenoresQue(lista<T> & result, const T & algo);
void obtemMaioresQue(lista<T> & result, const T & algo);
// obtém todos valores entre "start" e "end" (inclusive)
void obtemIntervalo(lista<T> & result, const T & start, const T & end);
protected:
T data;
arvore<T> * esq, * dir;
// um ponteiro para pilha a ser usada pelo iterador.
// OBS: pode-se usar uma lista como se fosse pilha !
lista<arvore<T>*> * p_stack;
arvore<T> * rotacionaL();
arvore<T> * rotacionaR();
};
} // fim do namespace
#include <libs/arvore-impl.h>
#endif /* ARVORE_H */
|
O algoritmo para enumeração pre-order é mostrado a seguir. Deve-se notar que esse algoritmo enumera todos os dados da árvore. Portanto, ele é uma versão não-recursiva de listePreOrder:
algoritmo pre-order(lista):
cria uma pilha de nodos
empilha a raiz
enquanto pilha não vazia faça
desempilha um nodo
anexa à lista dado do nodo
se nodo possui ramo direito então
empilha o nodo direito
se nodo possui ramo esquerdo então
empilha o nodo esquerdo
fim se
fim enquanto
destroi pilha
fim pre-order
O algoritmo para enumeração in-order é mostrado a seguir. Deve-se notar que esse algoritmo enumera todos os dados da árvore. Portanto, ele é uma versão não-recursiva de listeInOrder:
algoritmo in-order(lista):
cria uma pilha de nodos
empilha a raiz e todos os nodos nos ramos mais à esquerda da raiz,
até o nodo com menor valor
enquanto pilha não vazia faça
desempilha um nodo
anexa à lista dado do nodo
se nodo possui ramo direito então
empilha o nodo direito e todos os nodos nos ramos mais à esquerda dele,
até o nodo com menor valor
fim se
fim enquanto
destroi pilha
fim in-order
A iteração da árvore pode aproveitar esse algoritmo com pequenas modificações.
Atividade
- Implemente a iteração in-order de sua árvore (métodos inicia, proximo, fim)
- Implemente a iteração in-order reversa de sua árvore (métodos iniciaPeloFim, anterior, inicio)
Balanceamento da árvore
Nos experimentos feitos até agora, as árvores de pesquisa binária apresentaram um bom desempenho tanto para serem criadas quanto para pesquisarem valores. Foi estudado que isso se deve a uma importante propriedade da árvore binária, que limita à altura da árvore a quantidade de operações de comparação em uma pesquisa qualquer. Como a altura é função do logaritmo da quantidade de nodos, ela tende a crescer muito lentamente com o aumento da quantidade de nodos da árvore (ex: uma árvore com pouco mais 2.3 milhões de nodos teria altura de pelo menos 21). Porém isso depende de os nodos estarem igualmente distribuídos dos dois lados da árvore. Em outras palavras, a árvore deve estar balanceada.
A partir de hoje iremos estudar como balancear uma árvore binária, e para isso usaremos o algoritmo clássico AVL. Mas outras abordagens existem, tais como árvores vermelho-preto. Uma interessante comparação entre árvores AVL e Vermelho-Preto pode ser lida na Wikipedia:
Red–black trees offer worst-case guarantees for insertion time, deletion time, and search time.
Not only does this make them valuable in time-sensitive applications such as real-time applications,
but it makes them valuable building blocks in other data structures which provide worst-case
guarantees; for example, many data structures used in computational geometry can be based on
red–black trees, and the Completely Fair Scheduler used in current Linux kernels uses red–black
trees.
The AVL tree is another structure supporting O(log n) search, insertion, and removal. It is more
rigidly balanced than red–black trees, leading to slower insertion and removal but faster retrieval.
This makes it attractive for data structures that may be built once and loaded without
reconstruction, such as language dictionaries (or program dictionaries, such as the opcodes of an
assembler or interpreter).
Fator de balanceamento
O fator de balanceamento é a diferença entre as alturas das árvores esquerda e direita, e pode ser calculado assim:

Se para todos os nodos da árvore  , então a árvore está balanceada e nada precisa ser feito. Porém se para algum nodo
, então a árvore está balanceada e nada precisa ser feito. Porém se para algum nodo  , então existe um desequilíbrio (má distribuição de nodos), o qual pode ser corrigido.
, então existe um desequilíbrio (má distribuição de nodos), o qual pode ser corrigido.
O balanceamento pode ser feito realizando rotações da árvore.
Rotações e balanceamento
O balanceamento da árvore implica equilibrar as alturas de cada árvore esquerda e direita dentro de uma árvore. Essa operação pode ser feita tendo como base o que se chama de rotações da árvore. Duas rotações básicas são possíveis: rotação à direita e à esquerda. Ambas rotações preservam a propriedade de relação de precedência dos dados contidos na árvore: à esquerda da raiz estão os dados menores que o valor da raiz, e à direita estão os maiores. Na figura a seguir, os círculos representam nodos e os triângulos representam subárvores.
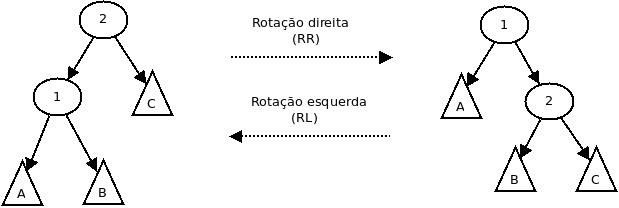
Combinando-se essas duas rotações básicas, podem-se realizar quatro tipo de transformações necessárias para o balanceamento de uma árvore AVL:
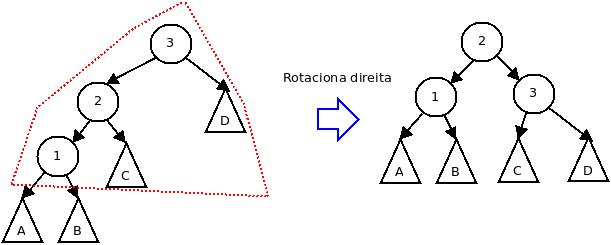
Caso 1: rotação direita
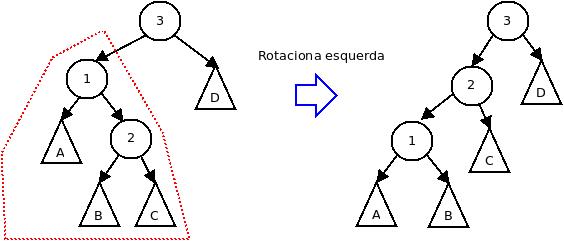
Caso 2: rotação esquerda da árvore esquerda
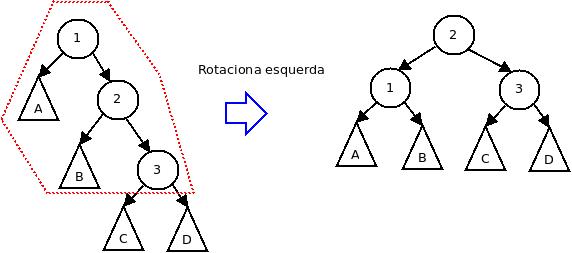
Caso 3: rotação esquerda
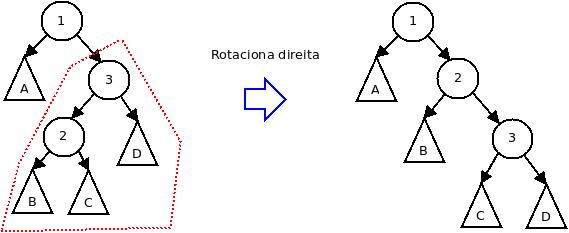
Caso 4: rotação direita da árvore direita
O balanceamento é feito combinando-se as rotações elementares (direita e esquerda) para aplicá-las a cada caso, o que aqui se chama de redução. A cada redução reduz-se o módulo do fator de balanceamento em uma unidade. Portanto se esse fator tiver um valor elevado, várias reduções sucessivas serão necessárias até que ele fique dentro do limite aceitável (i.e.  ). As reduções podem ser feitas à direita ou esquerda:
). As reduções podem ser feitas à direita ou esquerda:
 : redução à direita:
: redução à direita:
- Se caso 4: executa-se rotacionaR na árvore direita
- executa-se rotacionaL
 : redução à esquerda:
: redução à esquerda:
- Se caso 2: executa-se rotacionaL na árvore esquerda
- executa-se rotacionaR
O algoritmo de balanceamento pode ser modelado da seguinte forma:
algoritmo balanceia(arvore):
entrada: arvore (modificada ao final do algoritmo)
valor de retorno: raiz da árvore após balanceamento
variáveis: Fb (inteiro)
se arvore esquerda nao nula entao
arvore esquerda <- balanceia(arvore esquerda)
se arvore direita nao nula entao
arvore direita <- balanceia(arvore direita)
Fb <- calcula fator de balanceamento da arvore
enquanto Fb < -1 faça
reduz à direita e calcula novo Fb
fimEnquanto
enquanto Fb > 1 faça
reduz à esquerda e calcula novo Fb
fimEnquanto
retorna arvore
Tanto as rotações quanto o balanceamento devem ser implementados como métodos da classe arvore. As rotações pode ser declaradas como métodos protegidos ou privativos, pois devem ser usados somente pelo algoritmo de balanceamento:
template <class T> class arvore {
protected:
// os atributos de uma arvore
public:
// os métodos públicos da Arvore
// A operação que calcula o fator de balanceamento
int fatorB() const;
// A operação que balanceia a árvore
// note que ela retorna um ponteiro para a nova raiz ...
arvore<T> * balanceia();
arvore<T> * balanceia(bool otimo);
// os métodos protegidos da Arvore ... por enquanto são públicos
// Quando estiverem prontos, devem ficar protegidos ou privativos
// rotação esquerda: retorna a nova raiz da árvore
arvore<T> * rotacionaL();
// rotação direita: retorna a nova raiz da árvore
arvore<T> * rotacionaR();
};
Assim ... implemente o balanceamento da sua árvore ! Dicas:
- Implemente o fator de balanceamento
- Implemente cada uma das rotações, testando-as em árvores pequenas com diferentes topologias.
- Tendo as rotações corretas, implemente o algoritmo de balanceamento. Teste-o com pequenas árvores cujas topologias sejam conhecidas. Verifique a altura e fator de balanceamento dessas árvores antes e após o balanceamento.
| Método escrevaSe reescrito para ajudar a visualizar a topologia da árvore
|
|
Acrescente isto ao arquivo arvore.h, antes da declaração da classe arvore:
#include <ostream>
using std::ostream;
Acrescente este método à declaração dos métodos públicos da classe arvore em arvore.h
void escrevaSe(ostream & out) const;
Acrescente isto a arvore-impl.h
#include <string>
using std::string;
template <typename T> void arvore<T>::escrevaSe(ostream& out) const {
static int nivel = -1;
string prefixo;
nivel++;
prefixo.append(nivel, ' ');
if (dir) dir->escrevaSe(out);
out << prefixo << data << std::endl;
if (esq) esq->escrevaSe(out);
nivel--;
}
|
| Programa de teste das rotações: testa rotacionaL e rotacionaR
|
#include <iostream>
#include <string>
#include <prglib.h>
using namespace std;
using prglib::arvore;
int main() {
arvore<int> * arv;
// uma árvore toda pro lado direito
arv = new arvore<int>(2);
arv->adiciona(3);
arv->adiciona(4);
arv->adiciona(5);
arv->adiciona(6);
arv->escrevaSe(cout);
cout << endl;
arv = arv->rotacionaL();
arv->escrevaSe(cout);
cout << endl;
arv = arv->rotacionaR();
arv->escrevaSe(cout);
cout << endl;
delete arv;
}
|
Atividade
- Implemente o balanceamento AVL de sua árvore, e aplique-o à árvore criada a partir das palavras do arquivo de portugues. A altura inicial da árvore é 42, e a altura após o balanceamento pode chegar a 21 (experimente realizar alguns balanceamentos sucessivos, até que a altura não mais reduza).
Remoção de um dado da árvore
Em uma aplicação da árvore pode ser necessário remover dados. Uma forma de fazer isso é listar todos os dados da árvore, remover os dados desejados e, em seguida, reconstruir a árvore, porém isso envolve um grande esforço computacional desnecessário. A solução mais simples é remover somente os dados desejados, fazendo talvez um ajuste pontual na estrutura da árvore. A operação remove definida abaixo deve implementar tal algoritmo .
// Este método da classe Arvore remove um nodo que seja igual a "algo"
// Retorna o dado removido.
// Se o dado não for encontrado, dispara uma exceção
T remove(const T & algo);
O método para remoção de um nodo da árvore, conforme declarado em arvore.h
A remoção de um dado de uma árvore de pesquisa binária tem o seguinte princípio:
- Localiza-se o nodo que contém o dado a ser removido.
- Substitui-se o valor desse nodo por uma destas alternativas:
- O maior valor existente à esquerda do nodo a ser removido.
- O menor valor existente à direita do nodo a ser removido.
A figura abaixo ilustra a remoção de um dado de uma árvore, destacando as duas possibilidades para a operação:
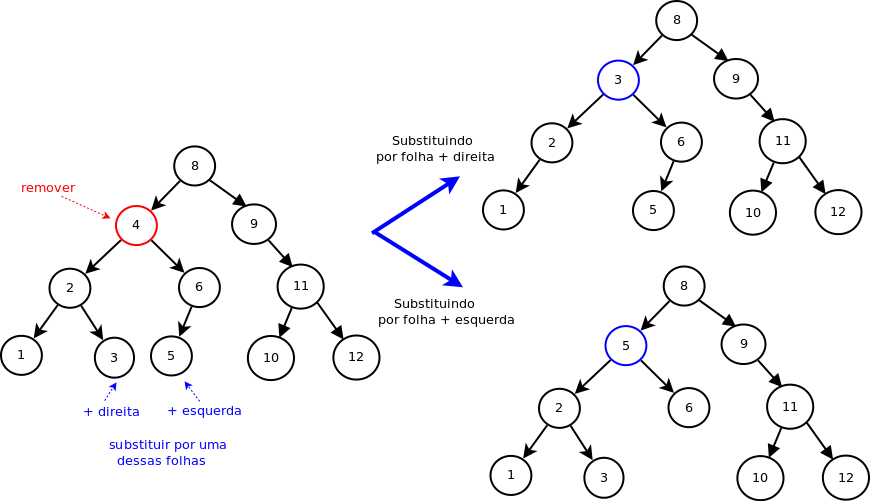
No exemplo acima, o menor valor à direita do nodo a ser removido é fácil de ser encontrado: basta seguir os ramos à esquerda da subárvore direita. O maior valor à esquerda também é fácil de ser encontrado: basta seguir os ramos à direita da subárvore esquerda. Mas o caso geral pode ficar mais complicado. Por exemplo, seja a árvore abaixo:
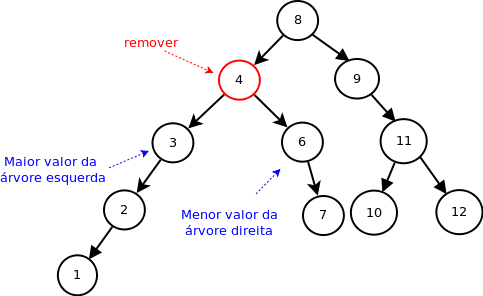
Nesse exemplo, o menor valor à direita do nodo a ser removido não é uma folha, nem pode ser encontrado simplesmente seguindo-se os ramos esquerdos da árvore direita. O mesmo vale para o maior valor à esquerda.
Para funcionar em todos os casos, o algoritmo de remoção de um dado da árvore pode ser resumido por este pseudo-código:
Localize o valor a ser removido
Se for uma folha, remove o nodo e retorna
Se fator de balanceamento da árvore enraizada no nodo a ser removido for maior que zero, então
Procura o maior valor da árvore esquerda
Copia esse valor para o nodo que contém o valor a ser removido
Remove esse maior valor da árvore esquerda
Senão
Procura o menor valor da árvore direita
Copia esse valor para o nodo que contém o valor a ser removido
Remove esse menor valor da árvore direita
fimSe
Além do método remove, dois outros métodos precisam ser implementados para obter o maior ou o menor valor de uma árvore:
// Este método da classe Arvore remove um nodo que seja igual a "algo"
// Retorna o dado que foi removido. Se o dado não for encontrado, dispara uma exceção
// A raiz da árvore pode ser modificada no processo ...
T remove(const T & algo);
// Retorna o menor dado da árvore
T & obtemMenor() const;
// Retorna o mair dado da árvore
T & obtemMaior() const;
| Programa de teste para remoção de valor da árvore
|
#include <iostream>
#include <string>
#include <prglib.h>
using prglib::arvore;
using namespace std;
int main() {
string dados[7] = {"um", "teste", "pequeno", "muito", "da", "simples", "arvore"};
auto arv = new arvore<string>(dados[3]);
for (int k=1; k < 4; k++) {
arv->adiciona(dados[k+3]);
arv->adiciona(dados[3-k]);
}
arv->escrevaSe(cout);
string dado = arv->remove(dados[1]);
cout << "Removeu " << dado << endl;
arv->escrevaSe(cout);
dado = arv->remove(dados[3]);
cout << "Removeu raiz: " << dado << endl;
arv->escrevaSe(cout);
delete arv;
return 0;
}
|
Atividade
- Implemente o método remove, e teste-o com o programa de teste. Experimente remover:
- um valor de uma folha
- um valor que esteja em um nodo intermediário
- o valor que está na raiz











