Mudanças entre as edições de "PJI3 20202"
| Linha 1 635: | Linha 1 635: | ||
</font> | </font> | ||
{{Collapse bottom | Aula 15}} | {{Collapse bottom | Aula 15}} | ||
| + | |||
| + | =17/02/2021: Redes sem-fio IEEE 802.11= | ||
| + | |||
| + | {{Collapse top | Aula 18}} | ||
| + | <font size="3"> | ||
| + | |||
| + | O provedor de acesso fornece um serviço de dados para seus clientes. Os links de acesso dos clientes têm características diferentes daqueles usados na rede local interna do provedor: | ||
| + | * A quantidade de pontos de acesso é muito maior do que na rede local interna | ||
| + | * Taxas de bits devem poder ser limitadas tanto para upstream quanto downstream | ||
| + | * As distâncias entre equipamentos do provedor e os clientes são maiores, podendo chegar a alguns quilômetros | ||
| + | * Existem diferentes tecnologias para implantar os links de acesso (EPON, GPON, xDSL, MetroEthernet, IEEE 802.11 PTMP, LTE, ...), ao contrário da rede local interna, onde tipicamente se usa somente Ethernet para rede cabeada e WiFi para rede sem-fio | ||
| + | * Os custos para implantação e operação desses links são significativos, devido às distâncias e tecnologias envolvidas | ||
| + | |||
| + | |||
| + | [[imagem:pji3-Rede-acesso.jpg|400px]] | ||
| + | <br>''A rede de acesso dos clientes'' | ||
| + | |||
| + | |||
| + | Os primeiros provedores de acesso, nos primórdios da Internet (meados dos anos 90 até início dos anos 2000), usavam [https://pt.wikipedia.org/wiki/Linha_discada acesso discado]. Para a realidade da época era uma escolha racional: a rede telefônica fixa atendia a maioria dos lares, e era possível transferir dados através de circuitos telefônicos. Apesar de esses links serem lentos para os padrões atuais (taxas na ordem de 30 kbps), terem baixa qualidade (muitos erros de transmissão), e serem caros (custo em função do tempo de uso), era o que havia e atendia a grande demanda das pessoas por acesso a Internet. Esse tipo de acesso somente caiu em desuso com o surgimento do [https://en.wikipedia.org/wiki/Asymmetric_digital_subscriber_line ADSL], no final dos anos 90 e início dos anos 2000, que fornecia taxas de dados bem superiores e menor custo. O acesso com ADSL ainda é usado em larga escala, porém outras tecnologias despontam e a tendência é que o suplantem. | ||
| + | |||
| + | Uma característica comum às tecnologias de acesso citadas, seja acesso discado, ADSL ou similares (como [https://en.wikipedia.org/wiki/Integrated_Services_Digital_Network ISDN], que não se popularizou), é estarem no domínio de operadoras de dados. Particularmente no Brasil, essas empresas nasceram dentro das grandes empresas de telecomunicações existentes, tais como as companhias telefônicas. Assim, o atendimento de clientes era feito usando infraestrutura e serviços dessas empresas, cabendo aos provedores de acesso complementarem os serviços de dados. As tecnologias envolvidas, e a rede de distribuição para atender os clientes, envolviam grandes investimentos. Porém as novas tecnologias de dados que vêm sendo adotadas têm menor custo, e podem ser implantadas em escalas menores e ainda serem viáveis. Isso tem viabilizado o surgimento de uma nova geração de provedores de acesso que não mais dependem da infraestrutura dessas grandes operadoras para implantarem links de dados para seus clientes. | ||
| + | |||
| + | = Tecnologias de acesso = | ||
| + | |||
| + | No escopo de um provedor metropolitano, algumas tecnologias de acesso têm se apresentado recentemente: | ||
| + | * Na categoria [https://www.cianet.com.br/blog/infraestrutura-e-tecnologia/por-que-utilizar-a-arquitetura-de-redes-fttx/ FTTx] destacam-se [https://www.fs.com/comparison-of-epon-and-gpon-aid-457.html GPON e EPON]: | ||
| + | ** [http://www.teleco.com.br/tutoriais/tutorialblgpon/pagina_3.asp GPON]: usa fibra ótica passiva, com taxas típicas de até 2.5 Gbps e facilidades para condicionamento de tráfego. Segue o [https://en.wikipedia.org/wiki/G.984 GPON]: padrão ITU-T G.984]. | ||
| + | ** [http://www.teleco.com.br/tutoriais/tutorialpontec1/pagina_3.asp EPON]: também usa fibra ótica passiva, porém com limitações se comparada a GPON (e menor custo). Apresenta taxas de 1 Gbps ou 10Gbps, e se baseia no padrão IEEE 802.3ah (uma variação de Ethernet feita para última-milha) | ||
| + | * [https://en.wikipedia.org/wiki/Point-to-multipoint_communication PTMP]: usa enlaces sem-fio, e se baseia tipicamente em uma versão modificada do padrão IEEE 802.11 (wifi), para que se adapte a links com maiores distâncias | ||
| + | * [http://www.teleco.com.br/tutoriais/tutorialblgpon/pagina_3.asp VDSL]: esta versão turbinada do ADSL pode ser usada combinada com GPON para atender clientes de um condomínio | ||
| + | * [https://en.wikipedia.org/wiki/Metro_Ethernet MetroEthernet]: disponibiliza enlaces Ethernet adaptados para longas distâncias | ||
| + | * [https://pt.wikipedia.org/wiki/Long_Term_Evolution LTE]: tecnologia de dados para dispositivos móveis nascida para os sistemas celulares, porém passível de ser usada para enlaces de acesso em menor escala (ver por exemplo [https://www.khomp.com/pt/categoria-de-produto/lte/ esta linha de produtos] de um fabricante da Grande Florianópolis) | ||
| + | |||
| + | |||
| + | [[imagem:pji3-Tecnologias-acesso.jpg]] | ||
| + | <br>''Tecnologias de acesso (obtido desta [https://leandrodriguesilva.wordpress.com/temas-sugeridos/tecnologias-de-acesso/ fonte])'' | ||
| + | |||
| + | |||
| + | No caso do provedor em implantação nesta disciplina, é útil avaliar quais tecnologias podem ser usadas. Inicialmente vale revisar o que os [[PJI11103:_Apresenta%C3%A7%C3%A3o#Tabela_de_provedores_existentes|provedores existentes]] utilizam, pois isso é um indicador de quais tecnologias estão mais popularizadas, têm menores custos e estão mais maduras. | ||
| + | |||
| + | = Redes sem-fio IEEE 802.11 = | ||
| + | |||
| + | O padrão IEEE 802.11 define uma tecnologia de redes locais sem-fio (WLAN), mais conhecida como WiFi. Esse tipo de rede tem como algumas características o baixo custo dos dispositivos, facilidade de utilização e boas taxas de transmissão em curtas distâncias (algumas dezenas de metros). Apesar de ter sido projetada para redes locais, essa tecnologia também tem sido usada para redes de média distância (alguns km). No entanto, para distâncias mais longas o padrão precisa ser adaptado para que funcione de forma eficiente. Para entender como criar enlaces de acesso sem-fio de alguns quilômetros usando esse tipo de tecnologia, é necessário entender seus princípios de funcionamento. | ||
| + | |||
| + | = Estrutura de uma rede IEEE 802.11 = | ||
| + | |||
| + | Uma rede local sem-fio (WLAN) IEEE 802.11 é implantada por um equipamento especial chamado de ''ponto de acesso'' (AP - Access Point). Esse equipamento estabelece uma WLAN, de forma que computadores, smartphones, PDAs, laptops, tablets (e outros dispositivos possíveis) possam se comunicar pelo canal sem-fio. Esses dispositivos são denominados ''estações sem-fio'' (WSTA - Wireless Station), e se comunicam usando o AP como intermediário. Isso significa que todas as transmissões na WLAN são intermediadas pelo AP: ou estão indo para o AP, ou vindo dele. Além disso, uma WSTA somente pode se comunicar na WLAN se primeiro se associar ao AP - isto é, se registrar no AP, sujeitando-se a um procedimento de autenticação. | ||
| + | |||
| + | Do ponto de vista da organização da WLAN, a menor estrutura possível é o BSS (Basic Service Set), mostrado na figura abaixo. Um BSS é formado por um AP e as WSTA a ele associadas. O BSS possui um nome, identificado pela sigla SSID (Service Set Identifier), que deve ser definido pelo gerente de rede. O BSS opera em um único canal, porém as transmissões podem ocorrer com diferentes taxas de bits (cada quadro pode ser transmitido com uma taxa, dependendo da qualidade do canal sem-fio conforme medida pela WSTA que faz a transmissão). Por fim, apenas uma transmissão pode ocorrer a cada vez, o que implica o uso de um protocolo de acesso ao meio (MAC) pelas WSTA e AP. | ||
| + | |||
| + | |||
| + | [[imagem:Wlan1.png|300px]] | ||
| + | |||
| + | |||
| + | O AP opera em nível de enlace, de forma parecida com um switch ethernet (porém sua tarefa é um pouco mais complexa ...). Isso quer dizer que o AP não usa o protocolo IP para decidir como encaminhar os quadros das WSTA, e assim não faz roteamento. Uma consequência desse modo de operação do AP é que a junção de dois ou mais AP por meio de um switch ethernet, com seus respectivos BSS, faz com que WSTAs em diferentes BSS possa se comunicar como se fizessem parte da mesma rede local. A união de dois ou mais BSS, mostrada na figura a seguir, se chama ESS (Extended Service Set). Em um ESS, todos os BSS possuem o mesmo SSID. No entanto, ao se criar um ESS deve-se cuidar para evitar que BSS vizinhos usem o mesmo canal. | ||
| + | |||
| + | [[imagem:Wlan2.png|800px]] | ||
| + | |||
| + | |||
| + | As redes IEEE 802.11b e IEEE 802.11g usam a frequência 2.4 GHz para seus canais, que são espaçados a cada 5 MHz. As redes IEEE 802.11n usam frequências de 2.4 ou 5 GHz. O pádrão mais recente, IEEE 802.11ac, usa exclusivamente 5 GHz. No caso de IEEE 802.11n, ainda a mais comum de ser usada, quando na banda de 2.4 GHz os canais são numerados de 1 a 11. Quando usa modo de modulação com largura de 20 MHz, apenas três dentre onze canais (no máximo) não apresentam sobreposição. Isso ocorre porque cada canal tem largura de 5 MHz. A tabela abaixo mostra os canais usados em IEEE 802.11n, indicando a lista de canais interferentes de cada canal. | ||
| + | |||
| + | [[imagem:Wlan-canais.png]] | ||
| + | |||
| + | Quando se usa modulação com largura de 40 MHz, apenas um canal pode ser usado (o canal 6), pois toda a banda disponível é usada. | ||
| + | |||
| + | No caso da banda de 5 GHz há muito mais canais, e as combinações de canais não-sobrepostos se torna mais complexa: | ||
| + | * [https://en.wikipedia.org/wiki/List_of_WLAN_channels#5_GHz_(802.11a/h/j/n/ac/ax) Canais 5 GHz] | ||
| + | |||
| + | [[imagem:PJI3-Wifi-5ghz.jpg|400px]] | ||
| + | |||
| + | == Sistemas de Distribuição == | ||
| + | |||
| + | Uma típica WLAN com estrutura distribuída pode ser criada explorando-se o conceito de ''Sistema de Distribuição'' (DS - ''Distribution System''). | ||
| + | |||
| + | Em uma rede IEEE 802.11, vários BSS podem se combinar para formarem um ESS (Extended Station Set). A interligação entre os AP deve ser feita em nível de enlace, seja por uma rede cabeada ou por links sem-fio. Essa interligação é denominada Sistema de Distribuição, estando exemplificada na figura abaixo: | ||
| + | |||
| + | |||
| + | [[imagem:80211-ds.png|400px]] | ||
| + | |||
| + | |||
| + | O sistema de distribuição funciona como uma ponte entre as WSTA, como mostrado na figura abaixo. Assim, se dois AP forem interligados, as WSTA que pertencem a seus BSS poderão se comunicar como se estivessem na mesma rede local. | ||
| + | |||
| + | |||
| + | [[imagem:80211-ds2.png|400px]] | ||
| + | |||
| + | |||
| + | Sistemas de distribuição podem ser implantados usando o próprio canal sem-fio, sendo assim denominados WDS (''Wireless Distribution System''). | ||
| + | |||
| + | [[imagem:Pji3-80211-wds.png]] | ||
| + | |||
| + | |||
| + | A cobertura de uma área envolve um planejamento que leve em conta as taxas mínimas desejáveis e as características dos equipamentos (potências de transmissão e ganhos de antenas) e do ambiente (existência de obstáculos, reflexões, e fontes de ruído). Além disso, deve-se minimzar a interferência entre BSS vizinhos, o que pode ser feito escolhendo-se canais que não se sobreponham. A figura abaixo mostra conceitualmente como se podem escolher os canais dos AP para atingir esse objetivo (no caso, para banda de 2.4 GHz e canais de 20 MHz). | ||
| + | |||
| + | [[imagem:80211-freq-planning.png]] | ||
| + | |||
| + | |||
| + | Desta forma, podem-se criar BSS para cobrir uma área e aproveitar melhor a capacidade do meio de transmissão. | ||
| + | |||
| + | [[imagem:80211-cobertura.png]] | ||
| + | |||
| + | Deve-se levar em conta que a qualidade do sinal tem relação com a modulação usada (e da taxa de dados), assim o limiar entre um BSS e outro depende de como as estações medem a qualidade de sinal e quais as taxas mínimas aceitáveis. A figura abaixo ilustra possíveis alcances para diferentes taxas de dados. | ||
| + | |||
| + | [[imagem:80211-ranges-rates.png|400px]]<br> | ||
| + | ''Taxas em função da distância do AP (exemplo, pois depende das condições do ambiente e dos equipamentos)'' | ||
| + | |||
| + | == Considerações sobre implantação de redes locais sem-fio == | ||
| + | |||
| + | Vimos que, para ampliar a cobertura de uma rede sem-fio IEEE 802.11, usam-se vários AP interligados em um ''Sistema de Distribuição'' (DS). Uma das maiores dificuldades ao se implantar uma rede sem-fio é determinar: | ||
| + | * quantos AP são necessários | ||
| + | * onde devem ser instalados | ||
| + | * qual o canal e potência de transmissão a serem usados em cada AP. | ||
| + | |||
| + | Existem algumas técnicas para estimar a cobertura de cada AP, dados sua potência de transmissão e as características do ambiente em que se encontra (paredes, portas, outros obstáculos). Um bom resumo pode ser encontrado no TCC [http://tele.sj.ifsc.edu.br/~msobral/RCO2/docs/cesar-2009-2.pdf "Estudo e projeto para o provimento seguro de uma infra-estrutura de rede sem fio 802.11"] de Cesar Henrique Prescher, defendido em 2009. Mas mesmo que se apliquem as recomendações ali descritas, ao final será necessário fazer uma verificação em campo da rede implantada. Para isso deve-se medir a qualidade de sinal sistematicamente na área de cobertura, para identificar regiões de sombra (sem cobertura ou com cobertura deficiente) e de sobreposição de sinais de APs. Tal tarefa implica o uso de ferramentas apropriadas e da aplicação de medições metódicas. | ||
| + | |||
| + | * [https://www.kismetwireless.net/ Kismet: uma ferramenta para análise de redes sem-fio com foco em segurança] | ||
| + | * [http://www.passmark.com/products/wirelessmonitor.htm Wireless Monitor (muita informação adicional)] | ||
| + | * [http://www.passmark.com/products/metageek-wi-spy.htm WiSpy: um dispositivo para medição de sinal] | ||
| + | * [http://www.metageek.net/products/inssider/ inSSIDer: outro Wifi Scanner] | ||
| + | |||
| + | = O MAC CSMA/CA = | ||
| + | |||
| + | O protocolo MAC usado em redes IEEE 802.11 se chama CSMA/CA (''Carrier Sense Multiple Access/Collision Avoidance''). Ele foi desenhado para prover um acesso justo e equitativo entre as WSTA, de forma que em média todas tenhas as mesmas oportunidades de acesso ao meio (entenda isso por "oportunidades de transmitirem seus quadros"). Além disso, em seu projeto foram incluídos cuidados para quue colisões sejam difíceis de ocorrer, mas isso não impede que elas aconteçam. Os procedimentos e cuidados do MAC para evitar e tratar colisões apresentam um certo custo (''overhead''), que impedem que as WSTA aproveitem plenamente a capacidade do canal sem-fio. Consequentemente, a vazão pela rede sem-fio que pode de fato ser obtida é menor que a taxa de bits nominal (por exemplo, com IEEE 802.11g e taxa de 54 Mbps, efetivamente pode se obter no máximo em torno de 29 MBps). | ||
| + | |||
| + | O protocolo CSMA/CA implementa um acesso ao meio visando reduzir a chance de colisões. Numa rede sem-fio como essa, não é possível detectar colisões, portanto uma vez iniciada uma transmissão não pode ser interrompida. A detecção de colisões, e de outros erros que impeçam um quadro de ser recebido pelo destinatário, se faz indiretamente com quadros de reconhecimento (''ACK''). Cada quadro transmitido deve ser reconhecido pelo destinatário, como mostrado abaixo, para que a transmissão seja considerada com sucesso. | ||
| + | |||
| + | [[Imagem:Wlan-ack.png|300px]]<br> | ||
| + | ''Envio de um quadro de dados, com subsequente reconhecimento (ACK)'' | ||
| + | |||
| + | |||
| + | O não recebimento de um ACK desencadeia uma retransmissão, de forma parecida com o procedimento de retransmissão do CSMA/CD ao detectar colisão. Antes de efetuar uma retransmissão, o MAC espera um tempo aleatório denominado ''backoff'' (recuo). Esse tempo é sorteado dentre um conjunto de possíveis valores que compõem a Janela de Contenção (Cw - ''Contention Window''), representados no intervalo [0, Cw]. O valor de Cw varia de <math>Cw_{min}</math> (15 para IEEE 802.11a/g/n e 31 para 802.11b) a <math>Cw_{max}</math> (1023), e praticamente dobra a cada retransmissão de um mesmo quadro. A figura abaixo ilustra as janelas de contenção para retransmissões sucessivas. | ||
| + | |||
| + | [[Imagem:Wlan-backoff.png|400px]]<br> | ||
| + | ''Backoff para retransmissões sucessivas'' | ||
| + | |||
| + | |||
| + | Resumidamente, o protocolo MAC usa basicamente dois mecanismos principais para fazer o acesso ao meio: | ||
| + | * Antes de uma transmissão, verifica-se se o canal está livre. Caso não esteja, deve-se primeiro aguardar que fique livre. | ||
| + | * Cada quadro transmitido deve ser confirmado pelo receptor. Isso quer dizer que o receptor deve enviar um quadro de confirmação para o transmissor (ACK). Se esse quadro ACK não for recebido, o transmissor assume que houve um erro. Nesse caso, o transmissor faz uma retransmissão. | ||
| + | * Antes de uma retransmissão o transmissor se impõem um tempo de espera aleatório chamado de ''backoff''. A duração máxima do ''backoff'' depende de quantas retransmissões do mesmo quadro já foram feitas. | ||
| + | |||
| + | |||
| + | A figura abaixo ilustra um cenário em que cinco WSTA disputam o acesso ao meio. Repare os ''backoff'' feitos pelas WSTA antes de iniciarem suas transmissões. Esse ''backoff'' sempre precede uma transmissão quando a WSTA for verificar o canal sem-fio e o encontra ocupado (pense em por que o MAC deve fazer isso ...). | ||
| + | |||
| + | [[imagem:Wlan-csmaca.png|600px]] | ||
| + | |||
| + | |||
| + | Por fim, o MAC CSMA/CA usado nas redes IEEE 802.11 define uma formato de quadros, mostrado na figura abaixo. Note que ele é diferente do quadro ethernet, e portanto o AP precisa traduzir os cabeçalhos de quadros que viajam da rede cabeada para a WLAN, e vice-versa. Note também que os endereços MAC do CSMA/CA são os mesmos que em redes ethernet. | ||
| + | |||
| + | |||
| + | [[imagem:Wlan-frame.png|500px]] | ||
| + | |||
| + | </font> | ||
| + | {{Collapse bottom | Aula 18}} | ||
Edição das 10h29min de 17 de fevereiro de 2021
Projeto Integrador III
Professora: Juliana Camilo (juliana.camilo@ifsc.edu.br)
Encontros: 4a feira/19:00, 6a feira/19:00
PPC Curso Técnico Subsequente de Telecomunicações
11/11/2020: Apresentação da disciplina.
| Aula 1 |
|---|
|
Apresentação da disciplinaIntrodução ao problema de estudoA disciplina de Projeto Integrador 3 tem como assunto principal as tecnologias de enlace e rede que podem ser usadas para implantar redes locais e redes de acesso. Além disso, uma introdução à redes WAN faz parte do programa da disciplina.
AtividadeNesta primeira aula o objetivo é descrever as características do serviço a ser oferecido pelo provedor, e pensar na infraestrutura necessária para que seja implantado. Isso inclui investigar o que os provedores que já existem tem oferecido para seus clientes, e que tecnologias eles utilizam. Ao final da aula, deveremos ter:
|
13/11/2020: Endereçamento IPv4. Configuração Estática e Dinâmica
| Aula 2 |
|---|
|
Configuração de endereçosO endereço IP de um host pode ser configurado de forma estática ou dinâmica. No primeiro caso, o usuário predefine o endereço IP no próprio equipamento. No segundo, o equipamento usa um protocolo especial de configuração para obter sua configuração de rede.
Configuração estáticaA configuração estática envolve um usuário gravar a configuração de rede de forma persistente na memória do host. Cada tipo de equipamento apresenta um procedimento diferente para armazenar a configuração de rede estática. Por exemplo, em computadores com sistema operacional Linux da família Debian (tais como Debian, Ubuntu, Mint e muitos outros), a configuração de rede fica armazenada no arquivo /etc/network/interfaces: iface eth0 inet static
address 10.1.23.19
netmask 255.255.255.0
gateway 10.1.23.254
router# configure terminal
router(config)# interface e0
router(config-if)# ip address 10.1.23.19 255.255.255.0
router(config-if)# exit
router(config)# ip route 0.0.0.0 0.0.0.0 10.1.23.254
router(config)# exit
router# write memory
router# write terminal
Building configuration...
Current configuration : 472 bytes
!
version 12.3
!
hostname Router
!
interface Ethernet0
ip address 10.1.23.19 255.255.255.0
!
ip route 0.0.0.0 0.0.0.0 10.1.23.254
Configuração dinâmicaUm host pode obter suas informações de rede dinamicamente por meio do protocolo DHCP (Dynamic Host Configuration Protocol). Desta forma, não há necessidade de o usuário saber as informações de rede necessárias para configurar corretamente seu equipamento. Isso torna possível também centralizar e automatizar a distribuição de endereços de rede para hosts. Se alguma das informações precisar ser modificada (ex: o roteador default), basta alterá-las no serviço DHCP para que toda a rede seja eventualmente reconfigurada. A maioria dos equipamentos de usuários vem de fábrica com configuração de rede dinâmica. Isso vale para computadores pessoais, em que os sistemas operacionais detectam as interfaces de rede e as configuram com DHCP, smartphones, tablets, câmeras IP, ATA e telefones IP, impressoras, e possivelmente outros equipamentos. Em computadores pessoais com sistemas operacionais Linux da família Debian, uma interface pode ser configurada dinamicamente se for declarada em /etc/network/interfaces desta forma: iface eth0 inet dhcp
Protocolo DHCPDHCP (Dynamic Host Configuration Protocol) é um protocolo para obtenção automática de configuração de rede, usado por computadores que acessam fisicamente uma rede. Esses computadores são tipicamente máquinas de usuários, que podem usar a rede esporadicamente (ex: usuários ocm seus laptops, com acesso via rede cabeada ou sem-fio), ou mesmo computadores fixos da rede. O principal objetivo do DHCP é fornecer um endereço IP, a máscara de rede, o endereço IP do roteador default e um ou mais endereços de servidores DNS. Assim, um novo computador que acesse a rede pode obter essa configuração sem a intervenção do usuário. Para esse serviço pode haver um ou mais servidores DHCP. Um computador que precise obter sua configuração de rede envia mensagens DHCPDISCOVER em broadcast para o port UDP 67. Um servidor DHCP, ao receber tais mensagens, responde com uma mensagem DHCPOFFER também em broadcast, contendo uma configuração de rede ofertada. O computador então envia novamente em broadcast uma mensagem DHCPREQUEST, requisitando o endereço IP ofertado pelo servidor. Finalmente, o servidor responde com uma mensagem DHCPACK, completando a configuração do computador cliente. Como a configuração tem um tempo de validade (chamado de lease time), o cliente deve periodicamente renová-la junto ao servidor DHCP, para poder continuar usando-a. O diagrama abaixo mostra simplificadamente esse comportamento:
O servidor DHCP identifica cada cliente pelo seu endereço MAC. Assim, o DHCP está fortemente relacionado a redes locais IEEE 802.3 (Ethernet) e IEEE 802.11 (WiFi). Servidor DHCPEm uma rede local em que hosts devem obter sua configuração de rede dinamicamente, deve haver ao menos um servidor DHCP. Esse serviço costuma estar disponibilizado em equipamentos de rede, tais como pontos de acesso sem-fio e roteadores. Por exemplo, o roteador sem-fio TP-Link WDR 4300 oferece esse serviço, que pode ser configurado e ativado por meio de sua interface de gerenciamento.
# tempos de concessão, em segundos
default-lease-time 600;
max-lease-time 7200;
# Algumas opções de uso comum
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.1.255;
option routers 192.168.1.1;
option domain-name-servers 191.36.8.2, 191.36.8.3;
option domain-name "sj.ifsc.edu.br";
# subrede 192.168.1.0/24 com duas faixas de endereços a serem concedidos:
# 192.168.1.100 a 192.168.1.150
# 192.168.1.190 a 192.168.1.240
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.100 192.168.2.150;
range 192.168.1.190 192.168.2.240;
}
AtividadeObjetivo
Roteiro 01: configuração de endereços
Tomando como base a rede do laboratório mostrada na figura, faça esses procedimentos no papel, e se possível em uma máquina virtual:
|







18/11/2020: Roteamento Estático e Dinâmico
| Aula 3 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Subredes IPUma subrede IP é representada por um prefixo de rede e uma máscara. O prefixo são os N bits mais significativos comuns a todos os endereços IP contidos em uma subrede (lembre que um endereço IP tem 32 bits). A máscara informa quantos bits tem o prefixo. A combinação de prefixo de rede e máscara funciona da seguinte forma: Imagine que exista uma subrede contendo os endereços de 192.168.2.0 até 192.168.2.255. Se representarmos esses endereços em binário, podemos ver que os 24 bits mais significativos são os mesmos para todos os endereços:
Encaminhamento IPTodo host é capaz de realizar uma função da camada de rede chamada de encaminhamento IP (IP forwarding). O encaminhamento é feito quando um host recebe um datagrama IP, e precisa decidir o que fazer com ele. O destino do datagrama depende do endereço de destino contido em seu cabeçalho IP.
A tabela de rotas a seguir foi obtida em um computador com sistema operacional Linux. aluno@M1:~$ route -n
Tabela de Roteamento IP do Kernel
Destino Roteador MáscaraGen. Opções Métrica Ref Uso Iface
0.0.0.0 191.36.9.254 0.0.0.0 UG 0 0 0 enp0s25
169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 enp0s25
191.36.9.0 0.0.0.0 255.255.255.0 U 0 0 0 enp0s25
192.168.2.64 191.36.9.1 255.255.255.192 U 0 0 0 enp0s25
Supondo que esse host tenha que encaminhar um datagrama com endereço de destino 8.8.8.8, a busca por uma rota adequada seria esta:
Roteamento estáticoCada host ligado a Internet possui uma tabela de rotas. É pelo conteúdo dessa tabela que ele sabe como transmitir os pacotes para cada destino. Em seu computador, você pode visualizar essa tabela da seguinte forma: # Isto funciona em qualquer *nix que se preze ...
netstat -rn
aluno@M1:~> ifconfig eth1 192.168.10.1 netmask 255.255.255.0
aluno@M1::~> netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
192.168.10.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo
Obs: ao menos próximo roteador ou interface de rede precisam ser especificados.
# adiciona a rota default, que passa pelo roteador 192.168.10.100
route add default gw 192.168.10.100
# este comando tem o mesmo efeito que o anterior ...
route add -net 0.0.0.0/0 gw 192.168.10.100
Roteamento dinâmicoRoteamento dinâmico é definido como a capacidade de roteamento automático por uma rede. No roteamento estático, como visto, as possibilidades de rota são definidas por meio de uma tabela de roteamento fixa definida manualmente. No entanto, no roteamento dinâmico as tabelas de roteamento são construídas automaticamente pelo sistema, e mantidas constantemente atualizadas devido a comunicação entre os roteadores participantes da rede. Sendo assim, uma rede que utilize algum protocolo de roteamento dinâmico é sensível a qualquer mudança de topologia da rede, sendo capaz de adaptar-se rapidamente a um novo padrão de rotas. Em outras palavras, um protocolo de roteamento dinâmico pode ser definido como uma maneira que um roteador fala com seus vizinhos a fim de compartilhar informações sobre rotas disponíveis na rede. A partir da capacidade de auto organização, o roteamento dinâmico deve ser capaz de procurar a melhor rota alternativa para um fluxo de dados, quando determinados roteadores se tornam inacessíveis ou estejam congestionados. O roteamento dinâmico dentro de uma rede pertencente a uma organização é chamado de roteamento interno', e o roteamento entre redes de diferentes oragnizações é denominado roteamento externo. O roteamento externo acontece no núcleo da Internet, e envolve um número muito grande de roteadores e hosts. Um dos protocolos clássicos de roteamento interno é o protocolo RIP. Por apresentar tempo convergência relativamente longo, o RIP se aplica a pequenas redes. Outro protocolo de roteamento interno se chama OSPF, o qual apresenta rápida convergência e é usado em redes maiores. Protocolo RIPO protocolo RIP (Routing Information Protocol) é um protocolo baseado na técnica vetor de distância, pois compartilha tabelas de distâncias entre roteadores vizinhos, para que cada roteador possa atualizar sua tabela de roteamento. O protocolo RIP foi um dos primeiros protocolos de roteamento baseado em vetor de distância aplicado a uma grande variedade de sistemas. O RIP possui as seguintes características principais de funcionamento:
A lógica de funcionamento do RIP é baseada em roteadores ativos, configurados como roteadores que realizam comunicação das rotas aos demais, e roteadores passivos que não disseminam mensagens porém atualizam suas rotas quando recebem informações atualizadas. Um roteador ativo mantém uma tabela de roteamento que possui os identificadores e IPs dos roteadores vizinhos, a rota de acesso, e um número inteiro que representa a distância do roteador até determinada rede. As tabelas são anunciadas para todos os roteadores da rede. O envio das tabelas de roteamento pelos roteadores acontece por broadcast em intervalos de tempo geralmente definidos para 30 segundos. Quando um nó recebe uma informação atualizada de determinado roteador vizinho, substitui sua tabela pela tabela atualizada. Para indicar a distância até uma determinada rede, o protocolo RIP utiliza uma métrica baseada em contagem de saltos, ou seja, quantos roteadores existem entre o roteador de origem e a rede de destino.
Exemplo RIP (De A para F)Neste exemplo um determinado nó A deseja se comunicar com o nó E.
Agora B e C enviam suas tabelas atualizadas para A, E e D respectivamente. Logo A, E, D atualizam suas tabelas e enviam por broadcast para todos os roteadores.
E envia sua tabela atualizada para F, que atualiza sua tabela.
F atualiza sua tabela e envia para todos.
Quando A recebe a tabela atualizada de F, atualiza sua própria tabela. A seguir temos a tabela do A depois da atualização.
AtividadesRoteiro 02: Subredes e roteamento estáticoEstes experimentos devem ser realizados no Netkit2, que deve ser executado na máquina real. Para esquentar: uma rede mais simples:
Praticamente a mesma rede, mas com um roteador a mais:
Roteamento estático entre redes das equipes
Roteamento dinâmico (com o RIP)
Baseado no diagrama da Figura, usaremos serviços para rodar os protocolos de roteamento RIP, de tal modo que as tabelas estáticas de roteamento não mais serão necessárias e o sistema se auto recuperará da queda de um único enlace (nesse caso). Em cada roteador o software Quagga é responsável por executar o protocolo de roteamento.
|







27/11/2020: Endereçamento IPv6, roteamento estático e dinâmico
| Aula 6 |
|---|
|
Endereços IPv4 têm 32 bits e são capazes de endereçarem até pouco mais de 4 bilhões de hosts, e isso parecia mais do que suficiente quando o protocolo IP foi criado, nos primórdios da Internet. Mas desde os anos 1990, quando se massificou essa rede, constatou-se que os endereços IPv4 se esgotariam num horizonte próximo. Para evitar esse problema, e possibilitar que a Internet continuasse se expandindo (e também por outros motivos), foi criado o protocolo IPv6, cujos endereços têm 128 bits. Essa questão está bem descrita na introdução do livro Laboratório de IPv6: Considerando que a concepção da Internet data da década de 70 e que, de lá para cá, houve uma explosão inesperada do seu uso, o IPv4 mostrou-se inadequado para acompanhar esta evolução.Uma das deficiências mais apontadas do IPv4 foi o espaço de endereçamento baseado num valor inteiro de 32 bits, que é tipicamente representado por quatro octetos em decimal, sendo possível disponibilizar apenas 4.294.967.296 endereços IPV4 diferentes. Para contornar essa deficiência, inúmeras soluções paliativas foram propostas e adotadas, como por exemplo o NAT (Network Address Solution) e o CIDR (Classless InterDomain Routing). Contudo, à medida que novas tecnologias de redes surgiram e o IP continuava sendo um dos protocolos chaves para sua operação, outras deficiências começaram a ser detectadas, especialmente aquelas referentes à segurança e ao suporte a parâmetros de QoS (Quality of Service) e mobilidade. Como consequência, no inicio da década de 90 é publicada a proposta da nova geração do IP (IPng – IP next generation) ou IPv6. Este novo protocolo traz a solução para muitas das deficiências de seu predecessor, o IPv4, incluindo espaço de endereçamento de 128 bits gerando a possibilidade de 340.282.366.920.938.463.463.374.607.431.768.211.456 endereços disponíveis, suporte a roteamento e segmentação de pacotes na estação origem, suporte a mobilidade e mecanismos de segurança.
Endereço IPV6Um endereço IPV6 possui 128 bits disponíveis para endereçar hosts, possibilitando 340 undecilhões de endereços possíveis. Para se ter uma ideia do que isto representa, se convertêssemos cada IPv6 possível em um cm2, poderíamos envolver toda a superfície do planeta Terra com 7 camadas de endereços..
Adoção no BrasilO Brasil está entre os 10 países com maior adoção de IPv6, segundo o Google:
Adoção no BrasilO Brasil está entre os 10 países com maior adoção de IPv6, segundo o Google:
Tipos de Endereços IPV6
Endereços Unicast
Link Local pode ser usado apenas no enlace específico onde a interface está conectada, o endereço link local é atribuído automaticamente utilizando o prefixo FE80::/64. Os 64 bits reservados para a identificação da interface são configurados utilizando o formato IEEE EUI-64. Vale ressaltar que os roteadores não devem encaminhar para outros enlaces, pacotes que possuam como origem ou destino um endereço link-local.
Atualmente, está reservada para atribuição de endereços a faixa 2000::/3 (001), ou seja, 3 primeiros bits utilizados para registros da faixa 2000. Equivalente aos endereços públicos IPv4, o endereço global unicast é globalmente roteável e acessível na Internet IPv6. Ele é constituído por três partes: o prefixo de roteamento global, utilizado para identificar o tamanho do bloco atribuído a uma rede; a identificação da sub-rede, utilizada para identificar um enlace em uma rede; e a identificação da interface, que deve identificar de forma única uma interface dentro de um enlace.Sua estrutura foi projetada para utilizar os 64 bits mais a esquerda para identificação da rede e os 64 bits mais a direita para identificação da interface. Endereço Multicast
O IPV6 não possui endereço broadcast, e sim multicast. Endereços multicast são utilizados para identificar grupos de interfaces, sendo que cada interface pode pertencer a mais de um grupo. Os pacotes enviados para esses endereço são entregues a todos as interfaces que compõe o grupo. Seu funcionamento é similar ao do broadcast, dado que um único pacote é enviado a vários hosts, diferenciando-se apenas pelo fato de que no broadcast o pacote é enviado a todos os hosts da rede, sem exceção, enquanto que no multicast apenas um grupo de hosts receberá esse pacote. Endereços Unicast
Link Local pode ser usado apenas no enlace específico onde a interface está conectada, o endereço link local é atribuído automaticamente utilizando o prefixo FE80::/64. Os 64 bits reservados para a identificação da interface são configurados utilizando o formato IEEE EUI-64. Vale ressaltar que os roteadores não devem encaminhar para outros enlaces, pacotes que possuam como origem ou destino um endereço link-local.
Atualmente, está reservada para atribuição de endereços a faixa 2000::/3 (001), ou seja, 3 primeiros bits utilizados para registros da faixa 2000. Equivalente aos endereços públicos IPv4, o endereço global unicast é globalmente roteável e acessível na Internet IPv6. Ele é constituído por três partes: o prefixo de roteamento global, utilizado para identificar o tamanho do bloco atribuído a uma rede; a identificação da sub-rede, utilizada para identificar um enlace em uma rede; e a identificação da interface, que deve identificar de forma única uma interface dentro de um enlace.Sua estrutura foi projetada para utilizar os 64 bits mais a esquerda para identificação da rede e os 64 bits mais a direita para identificação da interface. Endereço Multicast
O IPV6 não possui endereço broadcast, e sim multicast. Endereços multicast são utilizados para identificar grupos de interfaces, sendo que cada interface pode pertencer a mais de um grupo. Os pacotes enviados para esses endereço são entregues a todos as interfaces que compõe o grupo. Seu funcionamento é similar ao do broadcast, dado que um único pacote é enviado a vários hosts, diferenciando-se apenas pelo fato de que no broadcast o pacote é enviado a todos os hosts da rede, sem exceção, enquanto que no multicast apenas um grupo de hosts receberá esse pacote. Cabeçalho IPV6
O cabeçalho IPv6 possui menos informações, quando comparado ao cabeçalho IPv4. Várias informações foram removidas do cabeçalho IPV6, como por exemplo o checksum, considerado uma informação desnecessária uma vez que o controle de erro é atribuído às camadas inferiores. Os campos presentes no cabeçalho IPV6 são definidos a seguir:
Auto-configuração de endereços
SLAACCom SLAAC, um host IPv6 tem a capacidade de auto-configurar seu endereço em uma subrede. Com isso, facilita-se a configuração de rede de um equipamento, pois torna-se desnecessário obter e definir manualmente seu endereço IPv6, além de outras informações tais como máscara de rede, gateway e servidores DNS. No entanto, isso depende de o gateway (ou algum outro equipamento) fornecer essas informações de configuração para os hosts em sua(s) subrede(s). Isso não é novidade, pois em redes IPv4 o serviço DHCP tem exatamente esse papel. Porém, com o surgimento de IPv6, a auto-configuração se tornou uma função do próprio protocolo de rede. Em redes IPv4, DHCP é um serviço que depende de softwares específicos tanto nos hosts (clientes) quanto no servidor. A auto-configuração IPv6 é muito mais simples, e não demanda nenhum software adicional nos hosts. A autoconfiguração do IPV6, chamada stateless, é o procedimento com que os hosts de uma subrede podem definir seus próprios endereços, baseados em informações locais (ex: endereço MAC de sua interfaces de rede Ethernet, Wifi, ou Bluetooth), e em informações recebidas de roteadores, denominadas mensagens Router Advertisement. Sendo assim, o roteador é o responsável por fornecer informações sobre a SUBrede para que seja possível que hosts que nela residem se autoconfigurem. A autoconfiguração do IPV6 é chamada de stateless porque o roteador não mantém nenhum registro sobre a configuração de cada host. Isso é consequência da capacidade dos hosts se autoconfigurarem apenas sabendo a subrede a que pertencem. No entanto, para que seja possível a autoconfiguração em redes baseadas em IPV6, duas etapas de configuração devem ser aplicadas, sendo elas:
Protocolo NDP (Neighbor Discovery Protocol)A auto-configuração IPv6 depende do protocolo NDP, implementado usando mensagens ICMPv6. De acordo com este tutorial do site IPv6.br, no caso da autoconfiguração de hosts, o protocolo fornece suporte para a realização de três funcionalidades:
DHCPv6
default-lease-time 600;
max-lease-time 7200;
subnet6 2001:db8::/64 {
range6 2001:db8::1234 2001:db8::abcd;
option dhcp6.name-servers 2001:db8::abc;
}
AtividadesObjetivos:
Para realizar estas atividades serão necessários alguns comandos:
Roteiro 03: Endereçamento IPv6, roteamento estático e dinâmicoParte 1: Endereços IPv6
Parte 2: Experimento com uma rede IPv6Estes experimentos devem ser realizados no Netkit2, que deve ser executado na máquina real.
Praticamente a mesma rede, mas com um roteador a mais:
Parte 3: SLAAC
Parte 4: DHCPv6
Parte 5: Roteamento dinâmico com IPV6 (com o RIPNG)
Baseado no diagrama da Figura, usaremos serviços para rodar os protocolos de roteamento RIP a partir do Quagga, de tal modo que as tabelas estáticas de roteamento não mais serão necessárias e o sistema se auto recuperará da queda de um único enlace (nesse caso).
O arquivo redeipv6.conf possui a configuração da rede a ser executada com o Netkit2. Observe que nessa configuração já está inserida a definição dos default gateway de cada pc.
|













09/12/2020: Introdução a LAN
| Aula 9 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Referências bibliográficas:
Distinção entre WAN, MAN e LANExiste uma classificação de redes de computadores segundo sua abrangência. Segundo ela, as redes podem ser divididas em:
Redes Locais (LAN)Obs: obtido de Data and Computer Communications, livro de William Stallings, 8a edição:
Algumas tecnologias
TopologiasUma topologia de rede diz respeito a como os equipamentos estão interligados. No caso da rede local, a topologia tem forte influência sobre seu funcionamento e sobre a tecnologia adotada. Dependendo de como se desenha a rede, diferentes mecanismos de comunicação são necessários (em particular o que se chama de acesso ao meio). A eficiência da rede (aproveitamento da capacidade de canal, vazão) e sua escalabilidade (quantidade de computadores e equipamentos que podem se comunicar com qualidade aceitável) também possuem relação com a topologia. A tabela abaixo exemplifica topologias conhecidas de redes locais.
Exemplos de uso de redes locaisExemplos de redes locais são fáceis de apresentar. Praticamente toda rede que interconecta computadores de usuários é uma rede local - mesmo no caso de redes sem-fio, um caso especial a ser estudado mais a frente. A rede do laboratório de Redes de Computadores, onde temos nossas aulas, é uma rede local. Os demais computadores do câmpus formam outra rede local. Quando em casa se instala um roteador ADSL e se conectam a ele um ou mais computadores, cria-se também uma rede local. Portanto, redes locais são bastante comuns e largamente utilizadas. Ainda assim, cabem alguns outros exemplos de possíveis redes locais, mostrados abaixo:
Arquitetura IEEE 802
Protocolo de acesso ao meio (MAC)O protocolo de acesso ao meio (MAC) é parte da camada de enlace na arquitetura IEEE 802, e tem papel fundamental na comunicação entre estações. O MAC é responsável por:
Padrão IEEE 802.3 (Ethernet)
Desenho usado por Bob Metcalfe, um dos criadores da Ethernet, para apresentação em uma conferência em 1976.
|

















16/12/2020: Interligação de LANs
| Aula 11 |
|---|
|
Interligação de LANs (norma IEEE802.1D)
Um switch aprende dinamicamente os endereços MAC acessíveis em cada porta usando a técnica bridge learning. Para saber quais os endereços MAC conectados a cada porta, um switch registra em uma tabela o endereço MAC de origem de um quadro recebido por uma porta. Essa tabela de endereços MAC associa cada endereço aprendido à porta por onde o respectivo quadro foi recebido. Por exemplo, imagine 2 computadores, A e B, conectados a um mesmo switch porém em portas distintas como mostrado na Figura a seguir:
Se o computador A deseja se comunicar com B, A envia um pacote para B. Entretanto, o switch não saberá em um primeiro momento a qual porta o PC B esta conectado. Sendo assim, o switch registra em sua tabela que o computador A está conectado na porta 1 ...
Segmentação de LANsA segmentação física é uma solução aparentemente simples e direta. Cada subrede deve ser composta de uma estrutura exclusiva, contendo seus switches e cabeamentos. No entanto, para adotar esse tipo de segmentação, algumas modificações precisarão ser feitas na infraestrutura de rede existente. Observe a estrutura física da rede do campus:
Segmentação com VLANsSe a reestruturação pudesse ser efetuada com mínimas modificações na estrutura física (incluindo cabeamento), a implantação da nova rede seria mais rápida e menos custosa. Para isso ser possível, seria necessário que a infraestrutura de rede existente tivesse a capacidade de agrupar portas de switches, separando-as em segmentos lógicos. Quer dizer, deveria ser possível criar redes locais virtuais, como mostrado na seguinte figura:
No exemplo acima, três redes locais virtuais (VLAN) foram implantadas nos switches. Cada rede local virtual é composta por um certo número de computadores, que podem estar conectados a diferentes switches. Assim, uma rede local pode ter uma estrutura lógica diferente da estrutura física (a forma como seus computadores estão fisicamente interligados). Uma facilidade como essa funcionaria, de certa forma, como um patch panel virtual, que seria implementado diretamente nos switches. Redes locais virtuais são técnicas para implantar duas ou mais redes locais Padrão IEEE 802.1qOs primeiros switches com suporte a VLANs as implementavam de forma legada (i.e. não seguiam um padrão da indústria). Isso impedia que houvesse interoperabilidade entre equipamentos de diferentes fabricantes. Logo a IEEE formou um grupo de trabalho para propor mecanismos padronizados para implantar VLANs, dando origem ao padrão IEEE 802.1q. Os fabricantes de equipamentos de rede o adataram largamente, suplantando outras tecnologias legadas (ex: ISL e VTP da Cisco). Com isso, VLANs IEEE 802.1q podem ser criadas usando switches de fabricantes diferentes. Atualmente, a implantação de VLANs depende de switches com suporte ao padrão IEEE 802.1q. Assim, verifique quais dos switches do laboratório possuem suporte a VLAN:
Uma VLAN é identificada por um número, chamado VID (VLAN Identifier), sendo que a VLAN com VID 1 é considerada a VLAN default (configuração de fábrica). Em um switch com suporte a VLAN IEEE 802.1q, cada porta possui um (ou mais ...) VID, o que define a que VLAN pertence. Assim, para criar uma VLAN, devem-se modificar os VID das portas de switches que dela farão parte. Por exemplo, em uma pequena rede com duas VLANs as portas dos switches podem estar configuradas da seguinte forma:
Além do VID, a configuração da porta de um switch deve especificar o modo de operação da VLAN:
|








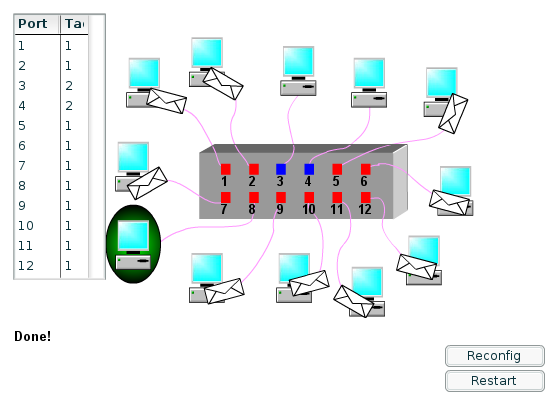
03/02/2021: LANs e caminhos fechados
| Aula 14 |
|---|
|
O problema dos ciclos (caminhos fechados) em uma rede local ethernetA interligação acidental de duas portas de um switch cria um ciclo na rede local (loop). Mas isso pode ser feito também de forma intencional, pois em LANs grandes pode ser desejável ter enlaces redundantes, para evitar que a interrupção de um enlace isole parte da rede. A existência de interligações alternativas portanto é algo que pode ocorrer em uma rede local, seja por acidente ou com a finalidade de conferir algum grau de tolerância a falhas na infraestrutura da rede. Um caso em que uma rede possui um ciclo intencionalmente colocado pode ser visto na LAN abaixo:
A configuração STP em switches deve observar o seguinte:
ExercíciosObjetivos
IntroduçãoA interligação de segmentos de uma LAN pode conter enlaces redundantes para prover tolerância a falhas: caso um enlace falhe, o que isolaria uma parte da rede, outro enlace pode ser usado para manter a conectividade. No entanto a existência de enlaces redundantes cria loops (“circuitos fechados”) na rede, e isto causa sérios problemas:
Parte 1: O efeito de caminhos fechados
Parte 2: O protocolo STP como possível soluçãoCom base na rede da parte 1 deste roteiro, faça o seguinte:
|



05/02/2021: LANS e agregação de enlaces
| Aula 15 |
|---|
|
Nessa rede, o switch central (core) integra os demais switches da rede. Todo o tráfego entre os dois lados da rede passa por esse switch, e pelos enlaces entre ele e os switches periféricos. Se um desses enlaces se romper, os dois lados da LAN ficam isolados. E, se muitos computadores estiverem se comunicando dois lados da rede, o switch core se torna um gargalo, limitando a taxa de transmissão máxima que pode ser obtida. Agregação de enlaceA agregação de enlace (LA - Link Agregation), descrita no padrão IEEE 802.1ax, possibilita que dois ou mais enlaces físicos entre dois switches operem como um único enlace lógico (chamado de LAG - Link Aggregation Group). O enlace agregado tem uma capacidade que equivale à soma das capacidades dos enlace físicos. Assim, um enlace agregado composto por dois enlaces físicos de 1 Gbps tem capacidade de 2 Gbps. Além disso, se um dos enlace físicos se romper, o enlace agregado continua a funcionar, porém com capacidade reduzida. A figura a seguir ilustra um enlace agregado formado por três enlaces físicos entre dois switches.
LACP: Link Aggregation Control ProtocolO protocolo LACP negocia enlaces agregados entre switches, contanto que estas condições estejam satisfeitas:
Estas figuras (obtidas nesta página) ilustram o estabelecimento de um enlace agregado com LACP, uma vez que as condições acima estejam satisfeitas:
AtividadesObjetivos
Parte 1: Enlace agregado estaticamenteEm um enlace agregado estaticamente, as portas envolvidas são predefinidas e somente podem ser alteradas manualmente. Com isso, se um enlace físico falhar, parte dos quadros transmitidos será perdida. Os experimentos seguintes buscam verificar o comportamento de um enlace agregado estaticamente.
|





17/02/2021: Redes sem-fio IEEE 802.11
| Aula 18 |
|---|
|
O provedor de acesso fornece um serviço de dados para seus clientes. Os links de acesso dos clientes têm características diferentes daqueles usados na rede local interna do provedor:
Uma característica comum às tecnologias de acesso citadas, seja acesso discado, ADSL ou similares (como ISDN, que não se popularizou), é estarem no domínio de operadoras de dados. Particularmente no Brasil, essas empresas nasceram dentro das grandes empresas de telecomunicações existentes, tais como as companhias telefônicas. Assim, o atendimento de clientes era feito usando infraestrutura e serviços dessas empresas, cabendo aos provedores de acesso complementarem os serviços de dados. As tecnologias envolvidas, e a rede de distribuição para atender os clientes, envolviam grandes investimentos. Porém as novas tecnologias de dados que vêm sendo adotadas têm menor custo, e podem ser implantadas em escalas menores e ainda serem viáveis. Isso tem viabilizado o surgimento de uma nova geração de provedores de acesso que não mais dependem da infraestrutura dessas grandes operadoras para implantarem links de dados para seus clientes. Tecnologias de acessoNo escopo de um provedor metropolitano, algumas tecnologias de acesso têm se apresentado recentemente:
Redes sem-fio IEEE 802.11O padrão IEEE 802.11 define uma tecnologia de redes locais sem-fio (WLAN), mais conhecida como WiFi. Esse tipo de rede tem como algumas características o baixo custo dos dispositivos, facilidade de utilização e boas taxas de transmissão em curtas distâncias (algumas dezenas de metros). Apesar de ter sido projetada para redes locais, essa tecnologia também tem sido usada para redes de média distância (alguns km). No entanto, para distâncias mais longas o padrão precisa ser adaptado para que funcione de forma eficiente. Para entender como criar enlaces de acesso sem-fio de alguns quilômetros usando esse tipo de tecnologia, é necessário entender seus princípios de funcionamento. Estrutura de uma rede IEEE 802.11Uma rede local sem-fio (WLAN) IEEE 802.11 é implantada por um equipamento especial chamado de ponto de acesso (AP - Access Point). Esse equipamento estabelece uma WLAN, de forma que computadores, smartphones, PDAs, laptops, tablets (e outros dispositivos possíveis) possam se comunicar pelo canal sem-fio. Esses dispositivos são denominados estações sem-fio (WSTA - Wireless Station), e se comunicam usando o AP como intermediário. Isso significa que todas as transmissões na WLAN são intermediadas pelo AP: ou estão indo para o AP, ou vindo dele. Além disso, uma WSTA somente pode se comunicar na WLAN se primeiro se associar ao AP - isto é, se registrar no AP, sujeitando-se a um procedimento de autenticação. Do ponto de vista da organização da WLAN, a menor estrutura possível é o BSS (Basic Service Set), mostrado na figura abaixo. Um BSS é formado por um AP e as WSTA a ele associadas. O BSS possui um nome, identificado pela sigla SSID (Service Set Identifier), que deve ser definido pelo gerente de rede. O BSS opera em um único canal, porém as transmissões podem ocorrer com diferentes taxas de bits (cada quadro pode ser transmitido com uma taxa, dependendo da qualidade do canal sem-fio conforme medida pela WSTA que faz a transmissão). Por fim, apenas uma transmissão pode ocorrer a cada vez, o que implica o uso de um protocolo de acesso ao meio (MAC) pelas WSTA e AP.
Quando se usa modulação com largura de 40 MHz, apenas um canal pode ser usado (o canal 6), pois toda a banda disponível é usada. No caso da banda de 5 GHz há muito mais canais, e as combinações de canais não-sobrepostos se torna mais complexa:
Sistemas de DistribuiçãoUma típica WLAN com estrutura distribuída pode ser criada explorando-se o conceito de Sistema de Distribuição (DS - Distribution System). Em uma rede IEEE 802.11, vários BSS podem se combinar para formarem um ESS (Extended Station Set). A interligação entre os AP deve ser feita em nível de enlace, seja por uma rede cabeada ou por links sem-fio. Essa interligação é denominada Sistema de Distribuição, estando exemplificada na figura abaixo:
Deve-se levar em conta que a qualidade do sinal tem relação com a modulação usada (e da taxa de dados), assim o limiar entre um BSS e outro depende de como as estações medem a qualidade de sinal e quais as taxas mínimas aceitáveis. A figura abaixo ilustra possíveis alcances para diferentes taxas de dados.
Considerações sobre implantação de redes locais sem-fioVimos que, para ampliar a cobertura de uma rede sem-fio IEEE 802.11, usam-se vários AP interligados em um Sistema de Distribuição (DS). Uma das maiores dificuldades ao se implantar uma rede sem-fio é determinar:
Existem algumas técnicas para estimar a cobertura de cada AP, dados sua potência de transmissão e as características do ambiente em que se encontra (paredes, portas, outros obstáculos). Um bom resumo pode ser encontrado no TCC "Estudo e projeto para o provimento seguro de uma infra-estrutura de rede sem fio 802.11" de Cesar Henrique Prescher, defendido em 2009. Mas mesmo que se apliquem as recomendações ali descritas, ao final será necessário fazer uma verificação em campo da rede implantada. Para isso deve-se medir a qualidade de sinal sistematicamente na área de cobertura, para identificar regiões de sombra (sem cobertura ou com cobertura deficiente) e de sobreposição de sinais de APs. Tal tarefa implica o uso de ferramentas apropriadas e da aplicação de medições metódicas.
O MAC CSMA/CAO protocolo MAC usado em redes IEEE 802.11 se chama CSMA/CA (Carrier Sense Multiple Access/Collision Avoidance). Ele foi desenhado para prover um acesso justo e equitativo entre as WSTA, de forma que em média todas tenhas as mesmas oportunidades de acesso ao meio (entenda isso por "oportunidades de transmitirem seus quadros"). Além disso, em seu projeto foram incluídos cuidados para quue colisões sejam difíceis de ocorrer, mas isso não impede que elas aconteçam. Os procedimentos e cuidados do MAC para evitar e tratar colisões apresentam um certo custo (overhead), que impedem que as WSTA aproveitem plenamente a capacidade do canal sem-fio. Consequentemente, a vazão pela rede sem-fio que pode de fato ser obtida é menor que a taxa de bits nominal (por exemplo, com IEEE 802.11g e taxa de 54 Mbps, efetivamente pode se obter no máximo em torno de 29 MBps). O protocolo CSMA/CA implementa um acesso ao meio visando reduzir a chance de colisões. Numa rede sem-fio como essa, não é possível detectar colisões, portanto uma vez iniciada uma transmissão não pode ser interrompida. A detecção de colisões, e de outros erros que impeçam um quadro de ser recebido pelo destinatário, se faz indiretamente com quadros de reconhecimento (ACK). Cada quadro transmitido deve ser reconhecido pelo destinatário, como mostrado abaixo, para que a transmissão seja considerada com sucesso.
|


















{kind=link}
{kind=link}