GER-2010-1
Gerência de Redes - semestre 2010-1
Informações gerais
Professor: Marcelo Maia Sobral
Email: msobral@gmail.com
Skype: mm-sobral
Lista de email (forum): ger-ifsc@googlegroups.com
Atendimento paralelo: 2a feira 10h - 11 h, 4a feira 10h - 12 h ou 16h - 17 h, 5a feira 10 - 11h, 6a feira 10 - 12h (no Laboratório de Desenvolvimento de Tele)
Reavaliação (recuperação): no final do semestre
Referências adicionais
- Valle, Odilson Tadeu. Gerência de Redes. IFSC - Unidade São José. 2009.
- Ubuntu Server Guide
- Guia Foca Linux (intermediário ou avançado)
- Demais referências contidas na página principal de GER.
Listas e avaliações simuladas
08/02: Introdução
Apresentação da disciplina e do ambiente de trabalho. Instalação do Ubuntu Linux Server 9.10.
Foi apresentada uma visão geral sobre Gerência de Redes, que trata do projeto, implantação, manutenção e monitoramento de serviços de rede. Na disciplina há uma ênfase em servidores, que são equipamentos (usualmente computadores) que disponibilizam os serviços de rede. Normalmente existem vários servidores em uma rede, os quais operam com algum grau de integração (sejam as contas de usuários e grupos, sistemas de arquivos compartilhados, nomeação de recursos, e outros possíveis serviços). Uma discussão mais aprofundada se encontra na apostila, nos capítulos 1 e 11.
Instalou-se o Ubuntu Server 9.10 na máquina virtual tecnologo-ger2 (VirtualBox). Usou-se um particionamento manual que isola os sistemas de arquivos / (raiz), /usr, /var e /home, além da partição de swap. Enfatizou-se que o uso de apenas um sistema de arquivos, como sugerido pelo instalador do sistema operacional, não é a melhor opção para um servidor. Do contrário, se um sistema de arquivos ficar cheio (por exemplo, devido aos arquivos de usuários), podem-se comprometer os serviços mantidos no servidor, porque é comum que os processos que os implementam precisem criar arquivos temporários para trabalharem. Outros motivos têm relação com a intergidade dos sistemas de arquivos, pois aqueles que sofrem modificações continuamente estão mais sujeitos a ficarem corrompidos em caso de desligamento súbito da máquina, apesar de isto ser mais difícil atualmente com sistemas de arquivos com journaling. Finalmente, em servidores com mais de um volume físico para armazenamento, torna-se necessário ou interessante isolar um sistema de arquivos em um subconjunto desses volumes.
Os tamanhos escolhidos para esses sistemas de arquivos são:
- /: 512 MB
- /usr: 1.5 GB
- /var: 512MB
- swap: 512 MB
- /home: 120 MB aprox. (o que sobrou)
Esse particionamento serviu somente para a instalação inicial, e provavelmente será modificado em breve.
O único serviço de rede instalado foi o Openssh server.
11/02: O processo de boot e instalação de software
O boot
O processo de inicialização do sistema operacional, chamado de boot. Tradicionalmente no Unix System V isto se faz com a definição de níveis de execução (runlevels) e uma tabela que descreve que processos ou serviços devem existir em cada nível. Os níveis de execução são:
- Monousuário (single-user), ou administrativo: usado para manutenção do sistema, admite somente o login do superusuário. Não inicia serviços de rede.
- Multiusuário com rede (parcial): admite logins de usuários, mas não ativa acesso a recursos de rede (como sistemas de arquivo remotos)
- Multiusuário com rede plena
- Não usado
- Multiusuário com rede plena e ambiente gráfico: ativa também o ambiente gráfico X11
- Reinício do sistema (reboot)
As distribuições Linux em geral adotam a inicialização no estilo Unix System V. No entanto, o Ubuntu usa um outro processo chamado de upstart. Esse serviço de inicialização confere maior flexibilidade e mesmo simplicidade à definição de que serviços devem ser executados. O upstart não usa o conceito de níveis de execução, mas devido à sua flexibilidade ele pode emular esse estilo de inicialização. Para o upstart, um serviço deve ser iniciado ou parado dependendo de uma combinação de eventosm, sendo que um evento indica a ocorrência de uma etapa da inicialização.
O upstart é implementado pelo processo init (programa /sbin/init), que é o primeiro processo criado pelo sistema operacional. Quer dizer, logo após terminar a carga e inicialização do kernel, este cria um processo que executa o programa /sbin/init. O upstart lista o subdiretório /etc/init e procura arquivos com extensão .conf. Cada arquivo desses descreve um serviço a ser controlado pelo upstart. Por exemplo, o serviço tty2 é escrito no arquivo tty2.conf:
# tty2 - getty
#
# This service maintains a getty on tty2 from the point the system is
# started until it is shut down again.
start on runlevel [23]
start on runlevel [!23]
respawn
exec /sbin/getty -8 38400 tty2
Abaixo segue o significado de cada linha:
- start on runlevel [23]: o serviço deve ser iniciado quando ocorrerem os eventos "runlevel 2" ou "runlevel 3"
- stop on runlevel [!23]: o serviço deve ser parado quando ocorrer qualquer evento "runlevel X", sendo X diferente de 2 e 3
- respawn: o serviço deve ser reiniciado automaticamente caso termine de forma anormal
- exec /sbin/getty -8 38400 tty2: a ativação do serviço implica executar o /sbin/getty -8 38400 tty2
Em linhas gerais, a descrição do serviço informa quando ele deve ser ativado (start), quando deve ser parado (stop), o tipo de execução (respawn para reinício automático, ou task para uma única execução), e que ação deve ser executada para ativar o serviço (exec para executar um programa, ou script .. end script para executar uma sequência de comandos de shell). Maiores detalhes podem ser lidos na página de manual do init.
Um exemplo de criação de serviço no upstart
Foi proposta a criação de um serviço chamado faxineiro, para remover dos diretórios temporários (/tmp e /var/tmp) todos os arquivos que não tenham sido modificados há mais de um dia. Esse novo serviço deve ser executado no boot, logo após o serviço mountall. A solução encontrada foi a seguinte:
- Criar o arquivo /etc/init/faxineiro.conf
- Adicionar o seguinte conteúdo a esse arquivo:
start on filesystem task console output script find /tmp -type f -mtime +1 -exec rm -f {} \; -print find /var/tmp -type f -mtime +1 -exec rm -f {} \; -print echo Faxineiro executado \!\!\! end script - Reiniciar o sistema para testá-lo (executar reboot)
Instalação de software
A instalação de software pode ser feita de diversas formas, dentre as quais serão destacadas três:
- Com utilitário apt-get: busca o software de um repositório de rede e o instala; dependências (outros softwares necessários) são automaticamente instaladas. Esses softwares buscados da rede estão no formato dpkg (Debian Package). Exemplo de uso do apt-get:
# Instala o navegador de texto lynx apt-get install lynx # Testa o navegador lynx lynx http://www.ifsc.edu.br/ # Remove o lynx apt-get --auto-remove remove lynx
- Diretamente com utilitário dpkg: instala um software que está contido em um arquivo no formato dpkg. Exemplo de uso:
# Obtém os pacotes Debian para o lynx wget http://www.sj.ifsc.edu.br/~msobral/ger/lynx_2.8.7pre6-1_all.deb wget http://www.sj.ifsc.edu.br/~msobral/ger/lynx-cur_2.8.7pre6-1_i386.deb # Instala os pacotes dpkg -i lynx-cur_2.8.7pre6-1_i386.deb lynx_2.8.7pre6-1_all.deb # Testa o lynx lynx # Remove os pacotes instalados dpkg -r lynx lynx-cur
- A partir do código fonte: busca-se manualmente na rede o código fonte do software desejado, que deve então ser compilado e instalado. Esta opção se aplica quando não existe o software no formato dpkg, ou a versão disponível em formato dpkg foi compilada de uma forma que não atende os requisitos para seu uso em seu servidor.
18/02: RAID
RAID (Redundant Array of Independent Disks) se destina a combinar discos de forma a incrementar o desempenho de entrada e saída e, principalmente, segurança dos dados contra defeitos em discos. RAID pode ser provido via software ou hardware (melhor este último). O Linux possui implementação por software em seu kernel, e neste HOWTO há uma descrição resumida.
Há vários níveis RAID, que correspondem a diferentes combinações de discos e partições. São eles:
- LINEAR: concatena discos ou partições, mas não provê acréscimos de desempenho, nem de segurança dos dados (pelo contrário ! se um disco falhar, perdem-se todos os dados ...).
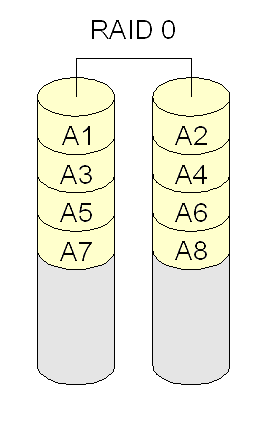
- RAID 0 (ou striping): combina discos ou partições de forma alternada, para distribuir os acessos entre eles (aumentar desempenho). Porém, se um disco falhar perdem-se todos os dados. Requer um mínimo de dois discos.
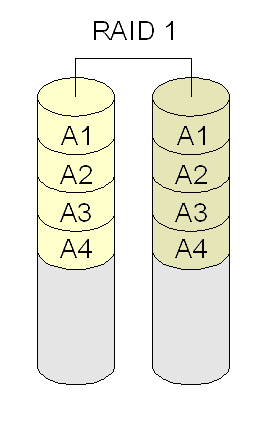
- RAID 1 (ou mirroring): combina discos ou partições para espelhar dados (segurança). Requer o dobro de discos necessários para guardar os dados (ex: se há dois discos com dados, são necessários outros dois para espelhamento). Se todos os discos falharem, é possível continuar a operar usando os discos espelhados. Requer no mínimo dois discos.
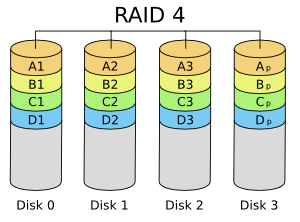
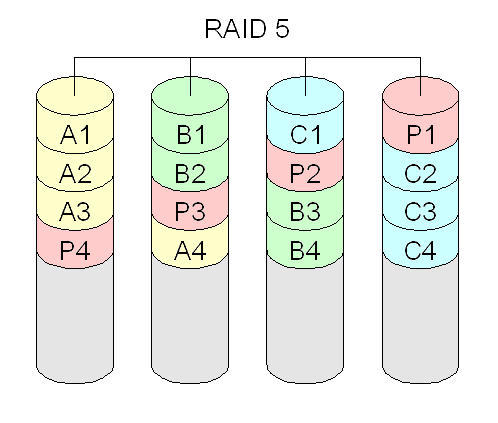
- RAID 4 e 5: combina discos ou partições para ter redundância de dados (segurança), usando um esquema baseado em paridade. Se um disco falhar, é capaz de continuar operando (porém com desempenho reduzido até que esse disco seja reposto). RAID 4 na prática não se usa, pois apresenta um gargalo no disco onde residem os blocos de paridades. Requer no mínimo três discos.
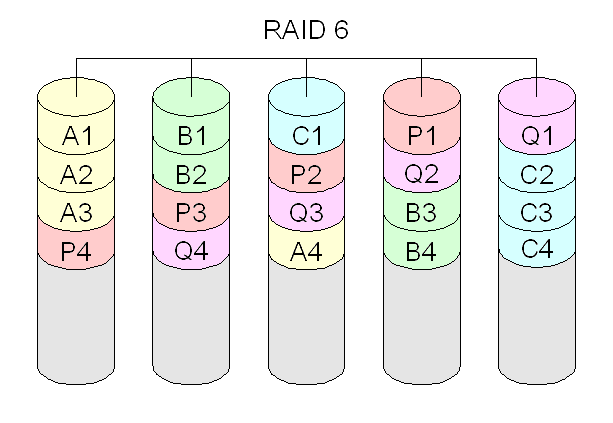
- RAID 6: combina discos ou partições para ter redundância de dados (segurança), usando um esquema baseado em paridade de forma duplicada. Isto garante que os dados se preservam mesmo que dois discos se danifiquem. Requer no mínimo quatro discos (pois há dois discos adicionais para paridades).
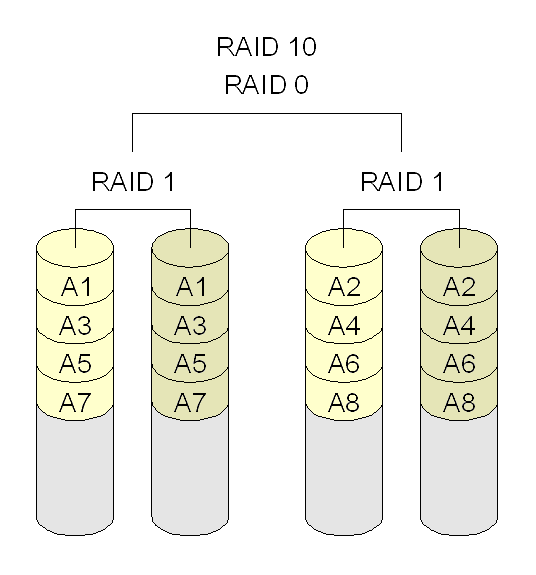
- RAID 10: combina RAID 1 e RAID 0, criando um volume com espelhamento (RAID 1), e depois fazendo o striping (RAID 0). Requer no mínimo quatro discos.
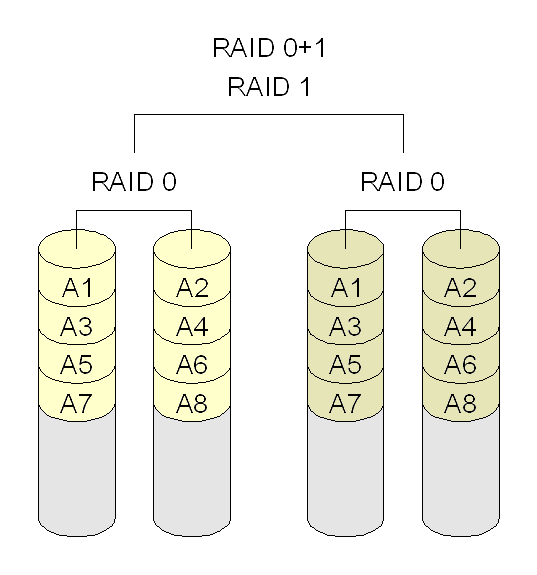
- RAID 01: combina RAID 0 e RAID 1, criando um volume com striping (RAID 0), e depois fazendo o espelhamento (RAID 1). Requer no mínimo quatro discos.







Criação de um volume RAID no Linux:
- Usar o comando mdadm --create --verbose /dev/md0 --level=NIVEL_RAID --raid-devices=NUM_PARTICOES PARTICAO_1 PARTICAO_2 ...
- NIVEL_RAID pode ser linear, 0, 1, 4, 5, 6, 10, mp, faulty (mais comuns são 0, 1 e 5).
- NUM_PARTICOES é a quantidade de partições usadas no volume.
- As partições são identificadas com o caminho (pathname) do dispositivo correspondente no Linux. Ex: a primeira partição do primeiro disco SCSI ou SATA é /dev/sda1, a segunda partição desse disco é /dev/sda2, a primeira partição do segundo disco SCSI ou SATA é /dev/sdb1, e assim por diante.
- /dev/md0 é o caminho do dispositivo que corresponde ao volume RAID a ser criado. O primeiro volume RAID é /dev/md0, o segundo é /dev/md1, e assim por diante.
- Formatar o volume RAID: mkfs.ext4 -j /dev/md0
- Uma vez testado o volume RAID, sua configuração pode ser salva para posterior uso: mdadm --detail --scan >> /etc/mdadm/mdadm.conf
- Isto é importante para que o volume possa ser ativado automaticamente no próximo boot.
Para ativar um volume já criado, basta executar mdadm --assemble caminho_do_volume. Ex: mdadm --assemble /dev/md0, mdadm --assemble /dev/md1.
Atividade:
- Crie duas partições de mesmo tamanho no disco /dev/sdb. Marque-as como sendo do tipo Linux RAID
- Crie um volume RAID nível 1 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
- Pare o volume existente, com mdadm -S /dev/md0
- Crie um volume RAID nível 0 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
- Pare o volume existente, com mdadm -S /dev/md0
- Crie um volume RAID nível 5 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
- Pare o volume existente, com mdadm -S /dev/md0
22/02: LVM
Armazenamento com Gerenciador de Volumes Lógicos (LVM). Ver páginas 57 e 58 da apostila.
Há um HOWTO com informação adicional sobre LVM no Linux, e outro com uma definição mais geral na Wikipedia.
LVM combina volumes físicos (ou PV, de Physical Volume), tais como discos, partições e volumes RAID, em uma abstração chamada grupo de volumes (ou VG, de Volume Group). Um VG funciona como um grande disco virtual, que pode ser dividido em volumes lógicos (LV, de Logical Volume). Cada LV pode ser usado para conter um sistema de arquivos, memória virtual (área de swap), ou qualquer outra finalidade de armazenamento (ex: área de dados de um banco de dados Oracle). A figura abaixo mostra a relação entre esses componentes, com exemplos de utilização dos LV:

Diagrama do LVM (obtido no Linux DevCenter)
Um resumo dos componentes do LVM segue abaixo:
- VG: Volume Group, que representa um disco lógico
- PE: Physical Extent, ou uma subdivisão do PV (são todas de mesmo tamanho), que funciona como unidade de alocação de espaço
- LE: Logical Extent, o equivalente ao PE, porém no contexto do LV
- PV: Physical Volume, ou uma partição física
- LV: Logical Volume, ou uma partição lógica criada dentro do VG
Em sua estrutura interna, o LVM divide cada PV em pequenas partições chamadas de PE (Physical Extent). Um tamanho típico para as PE é de 4 MB. Essas PE são usadas para alocar espaço para os LV, porém não há nenhuma relação entre a ordem física das PE nos PV e a ordem em que elas são alocadas aos LV - é normal inclusive PE de diferentes PV serem alocadas ao mesmo LV. Dentro de cada LV cada PE é chamada de LE (Logical Extent). A figura abaixo relaciona as PE com as LE dos LV:

Diagrama para LVM versão 1 (LVM1) no Linux.
Criação do LVM no Linux
A sequência de criação de um VG e seus LV é a seguinte:
- Criar partições físicas do tipo 8E (Linux LVM), que serão usadas para serem os PV
- Preparar essas partições para serem usadas como PV, usando o comando lvm pvcreate caminho_partição (ex: lvm pvcreate /dev/sdb1)
- Criar o VG, usando o comando lvm vgcreate nome_vg pv1 [pv2 ...] (ex: lvm vgcreate meu_vg /dev/sdb1 /dev/sdb2)
- Criar os LV, com o comando lvm lvcreate nome_vg -L tamanho_LV -n nome_LV (ex: lvm lvcreate meu_vg -L 512M -n teste)
- Formatar os LV (ex: mke4fs -j /dev/meu_vg/teste, para formatar com sistema de arquivos ext4)
Abaixo segue um exemplo de uma sequência de comandos relacionados com LVM, desde o particionamento de um disco até o redimensionamento de um LV existente:
# Prepara as partições (devem ser do tipo 8E (Linux LVM)
fdisk /dev/sdb
# Prepara essas duas partições para serem usadas como volumes físicos
lvm pvcreate /dev/sdb1
lvm pvcreate /dev/sdb2
# Cria o volume group "vg"
lvm vgcreate vg /dev/sdb1 /dev/sdb2
# Cria dentro do volume group "vg" um volume lógico "dados" com 512 MB iniciais
lvm lvcreate vg -L 512M -n dados
# Cria dentro do volume group "vg" um volume lógico "teste" com 256 MB iniciais
lvm lvcreate vg -L 256M -n teste
# Mostra informações sobre todos os volumes lógicos
lvm lvs
# Mostra detalhes sobre o volume lógico "dados", que pertence ao volume group "vg"
lvm lvdisplay /dev/vg/dados
# Formata o volume lógico "dados" com sistema de arquivos do tipo "ext4"
mkfs.ext4 -j /dev/vg/dados
# Formata o volume lógico "teste" com sistema de arquivos do tipo "xfs"
mkfs.xfs /dev/vg/dados
# Aumenta em 512 MB o tamanho do volume lógico "dados"
lvm lvresize -L +512M /dev/vg/dados
# Aumenta o sistema de arquivos contido no volume lógico "dados", para adaptá-lo ao seu novo tamanho
resize2fs /dev/vg/dados
Questões importantes:
- O que é LVM, e qual sua relação com os discos físicos ?
- Para que usar LVM (o que se ganha com seu uso) ?
- Existe algum problema que possa ocorrer com o uso do LVM ? Por exemplo, se um disco apresentar defeito ?
Atividade:
- Com o fdisk crie três novas partições, no início do espaço livre do disco, uma de tamanho de 512 MB, outra de 1GB e a terceira com 1.4 GB. Formate-as com sistema de arquivos ext4.
- Monte estas partições em /dados, /soft e /outra.
- Configure o sistema para que faça a montagem automaticamente, ou seja, em todo reinício da máquina.
- Desfaça os itens 2 e 3, para dar prosseguimento ao exercício.
- Crie um grupo de volume LVM (VG) com nome GerVg, contendo as duas partições criadas no item 1. Esse VG deverá ter tamanho total de 1512 MB.
- Crie 4 volumes lógicos, "dados", "home", "teste", "softwares", respectivamente com 300 , 400, 100 e 500 MB, dentro do VG.
- Formate os volumes lógicos.
- Monte as novas partições em /dados, /usuarios, /nada e /soft.
- Aumente o tamanho de "home" em 500 MB, redimensionando o sistema de arquivos apropriadamente (e sem desmontá-lo).
- Com o fdisk remova completamente as partições criadas, para não deixar o hd “bagunçado”. Remova também todos os diretórios criados.
RAID + LVM
LVM não proporciona proteção dos dados ... pelo contrário. Por combinar volumes físicos para serem usados em volumes lógicos, e pela forma como faz a alocação de espaço (em que os LE dos volumes lógicos podem apresentar um mapeamento arbitrário e fora de sequência aos PE dos volumes físicos), na verdade o LVM amplia a chance de dores de cabeça no evento de um defeito em um disco. Por isto é fundamental que a segurança dos dados seja provida por outra técnica, sendo o mais recomendado RAID.
RAID combina discos ou partições de forma a incrementar o desempenho e/ou segurança dos dados, conforme visto anteriormente. Um volume RAID (ou array RAID), composto de múltiplos discos, se apresenta como se fosse um único disco. Para usá-lo de forma a prover segurança de dados para o LVM, o volume RAID deve ser usado como volume físico do LVM. Além disto, dado o objetivo do uso do RAID, devem-se usar os níveis RAID 1, RAID 5, RAID 6 ou RAID 10 (melhor os dois primeiros). Fazendo isto, os volumes LVM estarão menos vulneráveis a falhas de hardware.
Atividade:
- Usando dois discos físicos com 4 GB cada, combine RAID e LVM para criar um Volume Group que aproveite todo o espaço disponível e esteja protegido contra defeitos em um dos discos.
- Crie dois sistemas de arquivos do tipo EXT4 dentro desse Volume Group:
- Um com 1GB, a ser montado em /dados
- Outro com 2 GB, a ser montado em /usuarios
- Simule um defeito em um dos discos e verifique se esses sistemas de arquivos continuam disponíveis:
- Se o Linux estiver rodando em um computador real, remova a alimentação de um dos discos
- Se estiver rodando com VirtualBox, desligue a máquina virtual, remova um dos discos virtuais, e então a reinicie
25/02: Usuários e grupos
Criação de contas de usuários e de grupos, e seu uso para conferir permissões de acesso a arquivos, diretórios e recursos do sistema operacional. Apostila, páginas 61 a 65.
Um usuário no Linux (e no Unix em geral) é definido pelo seguinte conjunto de informações:
- Nome de usuário (ou login): um apelido que identifica o usuário no sistema
- UID (User Identifier): um número único que identifica o usuário
- GID (Group Identifier): o número do grupo primário do usuário
- Senha (password): senha para verificação de acesso
- Nome completo (full name): nome completo do usuário
- Diretório inicial (homedir): o subddiretório pessoal do usuário, onde ele é colocado ao entrar no sistema
- Shell: o programa a ser executado quando o usuário entrar no sistema
As contas de usuários, que contêm as informações acima, podem ficar armazenadas em diferentes bases de dados (chamadas de bases de dados de usuários). Dentre elas, a mais simples é composta pelo arquivo /etc/passwd:
root:x:0:0:root:/root:/bin/bash
sshd:x:71:65:SSH daemon:/var/lib/sshd:/bin/false
suse-ncc:x:105:107:Novell Customer Center User:/var/lib/YaST2/suse-ncc-fakehome:/bin/bash
wwwrun:x:30:8:WWW daemon apache:/var/lib/wwwrun:/bin/false
dayna:x:1000:100:Dayna M Bortoluzzi:/home/dayna:/bin/bash
man:x:13:62:Manual pages viewer:/var/cache/man:/bin/bash
news:x:9:13:News system:/etc/news:/bin/bash
uucp:x:10:14:Unix-to-Unix CoPy system:/etc/uucp:/bin/bash
sobral:x:1001:100:Marcelo Maia Sobral:/data1/sobral:/bin/bash
Acima um exemplo de arquivo /etc/passwd
Cada linha desse arquivo define uma conta de usuário no seguinte formato:
nome de usuário:senha:UID:GID:Nome completo:Diretório inicial:Shell
O campo senha em /etc/passwd pode assumir os valores:
- x: significa que a senha se encontra em /etc/shadow
- *: significa que a conta está bloqueada
- senha encriptada: a senha de fato, porém encriptada usando algoritmo hash MD5 ou crypt. Porém usualmente a senha fica armazenada no arquivo /etc/shadow.
O arquivo /etc/shadow armazena exclusivamente as informações relativas a senha e validade da conta. Nele cada conta possui as seguintes informações:
- Nome de usuário
- Senha encriptada (sobrepõe a senha que porventura exista em /etc/passwd)
- Data da última modificação da senha
- Dias até que a senha possa ser modificada (validade mínima da senha)
- Dias após que a senha deve ser modificada
- Dias antes da expiração da senha em que o usuário deve ser alertado
- Dias após a expiração da senha em que a conta é desabilitada
- Data em que a conta foi desabilitada
Um exemplo do arquivo /etc/shadow segue abaixo:
root:$2a$05$8IZNUuFTMoA3xv5grggWa.oBUBfvrE4MfgRDTlUI1zWDXGOHi9dzG:13922::::::
suse-ncc:!:13922:0:99999:7:::
uucp:*:13922::::::
wwwrun:*:13922::::::
sobral:$1$meoaWjv3$NUhmMHVdnxjmyyRNlli5M1:14222:0:99999:7:::
Exercício: quando a senha do usuário sobral irá expirar ?
Um grupo é um conjunto de usuários definido da seguinte forma:
- Nome de group (group name): o nome que identifica o grupo no sistema
- GID (Group Identifier): um número único que identifica o grupo
- Lista de usuários: um conjunto de usuários que são membros do grupo
Assim como as contas de usuários, os grupos ficam armazenados em bases de dados de usuários, sendo o arquivo /etc/group a mais simples delas:
root:x:0:
wheel:x:10:dayna
trusted:x:42:
tty:x:5:
utmp:x:22:
uucp:x:14:
video:x:33:sobral
wheel:x:10:dayna
www:x:8:sobral
users:x:100:
radiusd:!:108:
vboxusers:!:1000:
Os membros de um grupo são os usuários que o têm como grupo primário (especificado na conta do usuário em /etc/passwd), ou que aparecem listados em /etc/group.
Gerenciamento de usuários e grupos
Para gerenciar usuários e grupos podem-se editar diretamente os arquivos /etc/passwd, /etc/shadow e /etc/group, porém existem utilitários que facilitam essa tarefa:
- useradd: adiciona um usuário
- Ex: useradd -c "Marcelo M. Sobral" -m sobral : cria o usuário sobral com nome completo "Marcelo M. Sobral"
- Ex: useradd -c "Marcelo M. Sobral" -g users -u 5000 -d /usuarios/sobral -s /bin/tcsh -m sobral : cria o usuário sobral com nome completo "Marcelo M. Sobral", UID 5000, grupo users, diretório inicial /usuarios/sobral e shell /bin/tcsh
- userdel: remove um usuário
- Ex: userdel sobral : remove o usuário sobral, porém preservando seu diretório home
- Ex: userdel -r sobral : remove o usuário sobral, incluindo seu diretório home
- usermod: modifica as informações da conta de um usuário
- Ex: usermod -u 5001 sobral : modifica o UID do usuário sobral
- Ex: usermod -g wheel sobral : modifica o GID do usuário sobral
- Ex: usermod -G users,wheel sobral : modifica os grupos secundários do usuário sobral
- Ex: usermod -d /contas/sobral sobral : modifica o diretório inicial do usuário sobral (mas não copia os arquivos ...)
- groupadd: adiciona um grupo
- Ex: groupadd -g 4444 ger: cria o grupo ger com GID 4444
- groupdel: remove um grupo
- Ex: groupdel ger: remove o grupo ger
- groupmod: modifica um grupo
- Ex: groupmod -g 5555 ger: modifica o GID do grupo ger
- Ex: groupmod -A sobral ger: adiciona o usuário sobral ao grupo ger
- Ex: groupmod -R sobral ger: remove o usuário sobral do grupo ger
Esses utilitários usam os arquivos /etc/login.defs e /etc/default/useradd para obter seus parâmetros default. O arquivo /etc/login.defs contém uma série de diretivas e padrões que serão utilizados na criação das próximas contas de usuários. Seu principal conteúdo é:
MAIL_DIR dir # Diretório de e-mail
PASS_MAX_DAYS 99999 #Número de dias até que a senha expire
PASS_MIN_DAYS 0 #Número mínimo de dias entre duas trocas senha
PASS_MIN_LEN 5 #Número mínimo de caracteres para composição da senha
PASS_WARN_AGE 7 #Número de dias para notificação da expiração da senha
UID_MIN 500 #Número mínimo para UID
UID_MAX 60000 #Número máximo para UID
GID_MIN 500 #Número mínimo para GID
GID_MAX 60000 #Número máximo para GID
CREATE_HOME yes #Criar ou não o diretório home
Como o login.defs o arquivo /etc/default/useradd contém padrões para criação de contas. Seu principal conteúdo é:
GROUP=100 #GID primário para os usuários criados
HOME=/home #Diretório a partir do qual serão criados os “homes”
INACTIVE=-1 #Quantos dias após a expiração da senha a conta é desativada
EXPIRE=AAAA/MM/DD #Dia da expiração da conta
SHEL=/bin/bash #Shell atribuído ao usuário.
SKEL=/etc/skel #Arquivos e diretórios padrão para os novos usuários.
O arquivo /etc/default/useradd contém alguns valores default de uso exclusivo do utilitário useradd:
GROUP=100
HOME=/home
INACTIVE=-1
EXPIRE=
SHELL=/bin/bash
SKEL=/etc/skel
GROUPS=video,dialout
CREATE_MAIL_SPOOL=no
Permissões
Há uma maneira de restringir o acesso aos arquivos e diretórios para que somente determinados usuários possam acessá-los. A cada arquivo e diretório é associado um conjunto de permissões. Essas permissões determinam quais usuários podem ler, e escrever (alterar) um arquivo e, no caso de ser um arquivo executável, quais usuários podem executá-lo. Se um usuário tem permissão de execução para um diretório, significa que ele pode realizar buscas dentro daquele diretório, e não executá-lo como se fosse um programa.
Quando um usuário cria um arquivo ou um diretório, o LINUX determina que ele é o proprietário (owner) daquele arquivo ou diretório. O esquema de permissões do LINUX permite que o proprietário determine quem tem acesso e em que modalidade eles poderão acessar os arquivos e diretórios que ele criou. O super-usuário (root), entretanto, tem acesso a qualquer arquivo ou diretório do sistema de arquivos.
O conjunto de permissões é dividido em três classes: proprietário, grupo e usuários. Um grupo pode conter pessoas do mesmo departamento ou quem está trabalhando junto em um projeto. Os usuários que pertencem ao mesmo grupo recebem o mesmo número do grupo (também chamado de Group Id ou GID). Este número é armazenado no arquivo /etc/passwd junto com outras informações de identificação sobre cada usuário. O arquivo /etc/group contém informações de controle sobre todos os grupos do sistema. Assim, pode -se dar permissões de acesso diferentes para cada uma destas três classes.
Quando se executa ls -l em um diretório qualquer, os arquivos são exibidos de maneira semelhante a seguinte:
> ls -l
total 403196
drwxr-xr-x 4 odilson admin 4096 Abr 2 14:48 BrOffice_2.1_Intalacao_Windows/
-rw-r--r-- 1 luizp admin 113811828 Out 31 21:28 broffice.org.2.0.4.rpm.tar.bz2
-rw-r--r-- 1 root root 117324614 Dez 27 14:47 broffice.org.2.1.0.rpm.tar.bz2
-rw-r--r-- 1 luizp admin 90390186 Out 31 22:04 BrOo_2.0.4_Win32Intel_install_pt-BR.exe
-rw-r--r-- 1 root root 91327615 Jan 5 21:27 BrOo_2.1.0_070105_Win32Intel_install_pt-BR.exe
>
As colunas que aparecem na listagem são:
- Esquema de permissões;
- Número de ligações do arquivo;
- Nome do usuário dono do arquivo;
- Nome do grupo associado ao arquivo;
- Tamanho do arquivo, em bytes;
- Mês da criação do arquivo; Dia da criação do arquivo;
- Hora da criação do arquivo;
- Nome do arquivo;
O esquema de permissões está dividido em 10 colunas, que indicam se o arquivo é um diretório ou não (coluna 1), e o modo de acesso permitido para o proprietário (colunas 2, 3 e 4), para o grupo (colunas 5, 6 e 7) e para os demais usuários (colunas 8, 9 e 10).
Existem três modos distintos de permissão de acesso: leitura (read), escrita (write) e execução (execute). A cada classe de usuários você pode atribuir um conjunto diferente de permissões de acesso. Por exemplo, atribuir permissão de acesso irrestrito (de leitura, escrita e execução) para você mesmo, apenas de leitura para seus colegas, que estão no mesmo grupo que você, e nenhum acesso aos demais usuários. A permissão de execução somente se aplica a arquivos que podem ser executados, obviamente, como programas já compilados ou script shell. Os valores válidos para cada uma das colunas são os seguintes:
- 1 d se o arquivo for um diretório;-se for um arquivo comum;
- 2,5,8 r se existe permissão de leitura;-caso contrário;
- 3,6,9 w se existe permissão de alteração;-caso contrário;
- 4,7,10 x se existe permissão de execução;-caso contrário;
A permissão de acesso a um diretório tem outras considerações. As permissões de um diretório podem afetar a disposição final das permissões de um arquivo. Por exemplo, se o diretório dá permissão de gravação a todos os usuários, os arquivos dentro do diretório podem ser removidos, mesmo que esses arquivos não tenham permissão de leitura, gravação ou execução para o usuário. Quando a permissão de execução é definida para um diretório, ela permite que se pesquise ou liste o conteúdo do diretório.
A modificação das permissões de acesso a arquivos e diretórios pode ser feita usando-se os utilitários:
- chmod: muda as permissões de acesso (também chamado de modo de acesso). Somente pode ser executado pelo dono do arquivo ou pelo superusuário
- Ex: chmod +x /home/usuario/programa : adiciona para todos os usuários a permissão de execução ao arquivo /home/usuario/programa
- Ex: chmod -w /home/usuario/programa : remove para todos os usuários a permissão de escrita do arquivo /home/usuario/programa
- Ex: chmod o-rwx /home/usuario/programa : remove todas as permissões de acesso ao arquivo /home/usuario/programa para todos os usuários que não o proprietário e membros do grupo proprietário
- Ex: chmod 755 /home/usuario/programa : define as permissões rwxr-xr-x para o arquivo /home/usuario/programa
- chown: muda o proprietário de um arquivo. Somente pode ser executado pelo superusuário.
- Ex: chown sobral /home/usuario/programa: faz com que o usuário sobral seja o dono do arquivo
- chgrp: muda o grupo dono de um arquivo. Somente pode ser executado pelo superusuário.
- Ex: chgrp users /home/usuario/programa: faz com que o grupo users seja o grupo dono do arquivo /home/usuario/programa
Há também o utilitário umask, que define as permissões default para os novos arquivos e diretórios que um usuário criar. Esse utilitário define uma máscara (em octal) usada para indicar que permissões devem ser removidas. Exemplos:
- umask 022: tira a permissão de escrita para group e demais usuários
- umask 027: tira a permissão de escrita para group, e todas as permissões para demais usuários
Atividade
- Crie o grupo turma.
- Crie o diretório /home/contas.
- Faça cópia dos arquivos a serem alterados: /etc/login.defs e /etc/default/useradd.
- Faça com que o diretório home dos usuários, a serem criados a partir de agora, seja por padrão dentro de /home/contas.
- Faça com que os usuários sejam criados com o seguinte perfil, por padrão:
- Expiração de senha em 15 dias a partir da criação da conta;
- Usuário possa alterar senha a qualquer momento;
- Data do bloqueio da conta em 7 dias após a expiração da senha.
- Inicie os avisos de expiração da senha 4 dia antes de expirar.
- Iniciar a numeração de usuários (ID) a partir de 1000.
- Crie um usuário com o nome de manoel, pertencente ao grupo turma.
- Dê ao usuário manoel a senha mane123.
- Acrescente ao perfil do usuário seu nome completo e endereço: Manoel da Silva, R. dos Pinheiros, 2476666.
- Verifique o arquivo /etc/passwd.
- Mude, por comandos, o diretório home do manoel de /home/contas/manoel para /home/manoel.
- Mude o login do manoel para manoelsilva.
- Logue como manoelsilva.
- Recomponha os arquivos originais do item 3.
Permissionamento de arquivos e grupos de usuários
- Crie a partir do /home 3 diretórios, um com nome aln (aluno), outro prf (professor) e o último svd (servidor).
- Crie 3 grupos com os mesmos nomes acima.
- Crie 3 contas pertencentes ao grupo aln: aluno1, aluno2, aluno3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/aln/. Por exemplo para o aluno1 teremos /home/aln/aluno1.
- Crie 3 contas pertencentes ao grupo prf: prof1, prof2, prof3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/prf/.
- Crie 3 contas pertencentes ao grupo svd: serv1, serv2, serv3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/svd/.
- Os diretórios dos alunos, e todo o seu conteúdo, devem ser visíveis, mas não apagáveis, aos membros do próprio grupo e de todos os demais usuários da rede.
- Já os diretórios dos professores e servidores, devem ser mutuamente visíveis, mas não apagáveis, entre os membros dos grupos professores e servidores mas não deve ser sequer visível aos membros do grupo alunos.
01/03: Quotas de disco
No início da aula finalizaram-se os exercícios sobre RAID e LVM.
Quotas de disco servem para limitar o uso de espaço pelos usuários. Ver também apostila de Gerência de Redes, páginas 65 a 69.
Em servidores não se pode correr o risco de poucos usuários utilizarem tanto espaço de disco que impeça outros usuários de trabalharem. Quer dizer, deve-se implantar algum mecanismo que limite o espaço a ser usado por cada usuário, para evitar que o espaço livre no volume se esgote. Quotas de disco é um mecanismo simples para impor tal limitação, estando disponível em todos os sistemas operacionais usados em servidores.
Os sistemas operacionais Linux oferecem um mecanismo simples para impor quotas. Para cada sistema de arquivos é possível ativar ou não o uso de quotas, e fazer um controle de quota por usuário ou grupo. Os sistemas de arquivos de uso mais difundido, tais como EXT3FS, EXT4FS, XFS, ReiserFS e JFS, suportam o uso de quotas (o que não é o caso de VFAT, usado majoritariamente em pendrives atualmente, por exemplo). O sistema operacional controla diretamente o uso do espaço, evitando que o limite estabelecido seja ultrapassado. Desta forma, se um arquivo estiver sendo gravado e o limite de espaço for atingido, a operação de escrita é abortada com um erro de quota excedida (como resultado, o arquivo ficaria truncado). Mas como essa forma de impor um limite pode ser muito estrita, o sistema de quotas define na verdade dois limites:
- soft limit: pode ser ultrapassado, no entanto gera um alerta para o usuário. No entanto, se o espaço total usado pelo usuário ficar acima desse limite continuamente por um número predefinido de dias, esse limite se torna estrito (quer dizer, se torna um hard limit).
- hard limit: não pode ser ultrapassado, gerando um erro de escrita.
Abaixo pode-se ver um exemplo do uso de disco pelo usuário msobral, em um sistema de arquivos com quotas ativadas. Nesse caso, msobral está usando em torno de 30 MB dentro do sistema de arquivos contido no dispositivo /dev/sdb2, e que está montado em /usuarios. O uso total atual está na coluna blocos (1 kB cada), soft limit aparece na coluna quota e o hard limit está em limite:
msobral@ger:~$ quota -v msobral
Sistema de arquivos blocos quota limite grace arquivos quota limite grace
/dev/sdb2 30724 100000 150000 2 0 0
msobral@ger:~$ ls -l /usuarios/msobral/teste
total 30720
-rw-r--r-- 1 msobral msobral 62914560 2010-02-28 19:32 teste
Além disto, note-se que há outras colunas reportadas acima, tais como grace e arquivos. A coluna grace informa quantos dias o usuário ainda tem de prazo, caso esteja acima do soft limit, antes que ele se torne um hard limit (normalmente iniciando com 7 dias). Além disso, é possível limitar também a quantidade de arquivos por ele mantidos. A coluna arquivos informa quantos arquivos e diretórios um usuário possui, e as colunas que a sucedem informam seus limites.
A decisão de que limites devem ser impostos aos usuários é de grande importância, pois devem-se conciliar as necessidades desses usuários e a quantidade de espaço em disco disponível para eles. Uma política para uso de espaço seria dividir a capacidade total do volume pela quantidade de usuários. Porém sabe-se que usuários têm diferentes práticas de uso dos recursos de rede, incluindo as áreas de armazenamento de arquivos. Muitos usuários fazem pouco uso do espaço disponível, enquanto outros realmente aproveitam tudo que lhes for alocado. Assim, uma outra política seria definir um limite individual maior, mesmo que a soma dos limites de usuários exceda a capacidade total do volume. Não é incomum que a soma das quotas individuais seja o dobro ou mais do espaço total existente. Cabe ao administrador o bom senso e, principalmente, o conhecimento sobre o padrão de uso de seus usuários, para melhor definir as quotas e assim o aproveitamento dos discos dos servidores.
Por fim, quotas não implicam nenhuma reserva de espaço em disco para os usuários.
Implantação de quotas
Vários passos são necessários para implantar quotas em um sistema de arquivos. Em primeiro lugar, deve-se certificar de que os utilitários necessários para sua configuração estejam instalados:
apt-get install quota
# mostra a man page do utilitário quota
man quota
Cada sistema de arquivos onde se desejam ativar quotas deve ser montado com a opção quota. Assim, a linha do arquivo /etc/fstab correspondente a um sistema de arquivos desses deve ser similar a:
/dev/sdb2 /usuarios ext4 defaults,quota 0 1
Ao montar o sistema de arquivos pela primeira vez, devem-se tanto atualizar manualmente as informações permanentes sobre quotas (mantidas em um arquivo aquota.user, que fica na raiz do sistema de arquivos), quanto ativar manualmente as quotas:
# Monta o sistema de arquivos /usuarios (só funciona assim por que ele está descrito em /etc/fstab)
mount /usuarios
# Atualiza as informações sobre quotas: isto varre todo o sistema de arquivos para contabilizar quanto espaço cada usuário possui, e grava
# o resultado no arquivo aquota.user
quotacheck -f /usuarios
# Ativa as quotas no sistema de arquivos
quotaon -v /usuarios
# Gera uma listagem das quotas dos usuarios
repquota /usuarios
Uma vez estando o sistema de arquivos definido com a opção quota, as quotas serão ativadas automaticamente no boot do sistema. O procedimento acima é necessário somente na implantação das quotas.
Uma vez estando as quotas ativadas, podem-se editar as quotas de usuaŕios com o utilitário edquota.
edquota sobral
Esse utilitário executa um editor de texto comum para editar as quotas, e então grava o resultado no arquivo aquota.user. O editor de texto executado é aquele indicado na variável de ambiente EDITOR (ex: nano, vim, ...). Abaixo pode-se ver o editor vi sendo chamado para editar as quotas:

Uma prática comum para automatizar a edição de quotas (e fazê-la de forma não-interativa) é definir alguns usuários que servem como perfis (ex: aluno, professor, funcionario), e definir as quotas para cada um deles. Assim , cada novo usuário que for criado pode ter suas quotas copiadas a partir de um desses perfis, usando-se edquota -p:
# copia as quotas do usuário professor para msobral
edquota -p professor msobral
Outra forma de definir quotas de forma não-interativa (bom para shell scripts ou outros programas que automatizem o gerenciamento de usuários) é com o utilitário setquota. Com esse programa devem-se informar diretamente na linha de comando os limites tanto de espaço em disco quanto de arquivos:
# Define quotas para o usuário msobral:
# espaço em disco: soft limit = 100 MB, hard limit = 150 MB
# quantidade de arquivos: ilimitado
setquota -u msobral 100000 150000 0 0 /usuarios
Finalmente, os usuários que excederam seus soft limit podem ser alertado por email pelo utilitário warnquota. Esse programa pode ser executado periodicamente pelo agendador de tarefas (ex: diariamente).
Sumário de utilitários sobre quotas
- quota: visualização de quotas
- quotaon: ativação de quotas em sistemas de arquivos (executado normalmente no boot)
- quotacheck: verificação dos dados sobre quotas (contidos no arquivo aquota.user)
- edquota: edição de quotas de usuários e grupos
- setquota: outro utilitário para editar quotas
- repquota: relatório de quotas de todos os usuários
- warnquota: alerta usuários com quotas excedidas
Atividade
- Configure o Linux para permitir o uso de quotas de usuários no “/home”.
- Estabeleça para os usuários do tipo alunos a seguinte quota: blocos (soft = 500 e hard = 1000).
- Estabeleça para os usuários do tipo professores e servidores a seguinte quota: blocos (soft = 600 e hard = 800).
- Logue como estes usuários e crie ou copie vários arquivos dentro de seus homes e verifique as mensagens de estouro de quotas de usuários.
- Crie um usuário chamado operador, e defina que sua quota é ilimitada. Crie arquivos para esse usuário, e verifique se há alguma restrição do sistema de quotas.
- Em um servidor se deseja limitar que alunos no total não excedam 100 MB, e professores e servidores estejam limitados a 200 MB. Quer dizer, todos os alunos juntos não podem execeder esse limite, assim como profesores e funcionários. Pesquise como implementar isto com o sistema de quotas do Linux (dica: veja quotas para grupos).
04/03: Quotas de disco
Continuou-se a aula sobre quotas.
08/03: Agendamento de tarefas
Agendamento de tarefas administrativas com crontab. Apostila de Gerência de Redes, capítulo 19.
O cron é um programa de agendamento de tarefas. Com ele pode-se fazer a programação para execução de qualquer programa numa certa periodicidade ou até mesmo em um exato dia, numa exata hora. Um uso comum do cron é o agendamento de tarefas administrativas de manutenção do seu sistema, como por exemplo, análise de segurança w backup. Estas tarefas são programadas para, todo dia, toda semana ou todo mês, serem automaticamente executadas através da crontab e um script shell comum. A configuração do cron geralmente é chamada de crontab.
Os sistemas Linux possuem o cron na instalação padrão. A configuração tem duas partes: uma global, e uma por usuário. Na global, controlada pelo root, o crontab pode ser configurado para executar qualquer tarefa de qualquer lugar, como qualquer usuário. Já na parte por usuário, cada usuário tem seu próprio crontab, sendo restringido apenas ao que o usuário pode fazer (e não tudo, como é o caso do root).
Uso do crontab
Para configurar um crontab por usuário, utiliza-se o comando crontab, junto com um parâmetro, dependendo do que se deseja fazer. Abaixo uma relação:
- crontab -e: Edita a crontab atual do usuário logado
- crontab -l: Exibe o atual conteúdo da crontab do usuário
- crontab -r: Remove a crontab do usuário
Se você quiser verificar os arquivos crontab dos usuários, você precisará ser root. O comando crontab coloca os arquivos dos usuários no diretório /var/spool/cron/crontabs . Por exemplo, a crontab do usuário aluno estará no arquivo /var/spool/cron/crontabs/aluno.
Existe também uma crontab global, que fica no arquivo /etc/crontab, e só pode ser modificado pelo root. Vamos estudar o formato da linha do crontab, que é quem vai dizer o que executar e quando. Vamos ver um exemplo:
30 12,22 * * * /home/aluno/scripts/backup.sh >/dev/null 2>&1
A linha é dividida em campos separados por tabs ou espaço:
| Campo | Função |
|---|---|
| 1o | Minuto |
| 2o | Hora |
| 3o | Dia do mês |
| 4o | Mês |
| 5o | Dia da semana |
| 6o | Programa a ser executrado |
Todos estes campos, sem contar com o 6o., são especificados por números. Veja a tabela abaixo para os valores destes campos:
| Campo | Função |
|---|---|
| Minuto | 0-59 |
| Hora | 0-23 |
| Dia do mês | 1-31 |
| Mês | 1-12 |
| Dia da semana | 0-6 (0=domingo, 6=sábado) |
Então o que nosso primeiro exemplo estava dizendo? A linha está dizendo: "Execute o comando /root/scripts/backup.sh às 12:30 h e às 22:30h, todos os dias".
Vamos analisar mais alguns exemplos:
1,21,41 * * * * echo "Meu crontab rodou mesmo!"
Aqui está dizendo: "Executar o comando do sexto campo toda hora, todo dia, nos minutos 1, 21 e 41".
30 4 * * 1 rm -rf /tmp/*
Aqui está dizendo: "Apagar todo conteúdo do diretório /tmp toda segunda-feira, as 4:30 da manhã."
45 19 1,15 * * /usr/local/bin/backup
Aqui está dizendo: "Executar o comando 'backup' todo dia 1 e 15 às 19:45.".
E assim pode-se ir montando inúmeros jeitos de agendamento possível. No arquivo do crontab global, o sexto campo pode ser substituído pelo nome do usuário, e um sétimo campo adicionado com o programa para a execução, como mostrado no exemplo a seguir:
*/5 * * * * root /usr/bin/mrtg /etc/mrtg/mrtg.cfg
Aqui está dizendo: "Executar o mrtg como usuário root, de 5 em 5 minutos sempre."
0 19-23/2 * * * /root/script
Aqui está dizendo: “Executar o 'script' entre as 19 e 23 de 2 em duas horas.”
Atividade
- Agende o comando date para escrever/adicionar sua saída ao arquivo /root/date a cada minuto.
- Pressuponha que o script /root/abacaxi.sh exista, agende o mesmo para ser executado:
- De dois em dois dias às 11 h e 55 min.
- Todo dia 5 às 3 h e 50 min.
- No dia 14 de cada mês entre as 8 e 18 h, de hora em hora.
11/03: Backups
Obs: o conteúdo abaixo foi copiado do capítulo 20 da apostila.
Um dos principais quesitos de segurança de redes é a integridade física dos dados e informações armazenadas.
O backup é uma ou várias cópias de segurança dos dados, para a recuperação dos dados em caso de acidentes. Objetiva assegurar a integridade contra possíveis quedas do sistema ou problemas com o disco principal. Inlcui também assegurar a recuperação de arquivos de usuários apagados/corrompidos acidentalmente ou não.
Existem várias formas de se garantir a disponibilidade da informação. A mais importante sem dúvidas é a cópia destes dados em local seguro, ou seja, o backup de dados, pois traz flexibilidade à organização de, a qualquer momento, voltar no tempo com os seus dados. O conceito de um local seguro por muitas vezes é o maior ponto de variação dentro do assunto backup e este merece atenção especial, pois por muitas vezes pensamos que o local seguro possa ser a torre do prédio ao lado, o que nem sempre é verdade.
Existem várias formas de se fazer o backup dos dados. Formas simples e baratas para pequenas empresas e usuários domésticos, que possuem poucas informações. Formas mais complexas e caras nas médias e grandes corporações, onde a quantidade de informações é imensa e também precisa de um backup desses dados. Isso nos leva a questão de política de backup e forma de armazenamento, onde existe então esta variação de custo X segurança. Entre estes pontos é possível se chegar a extremos de confiabilidade o que por muitas vezes é diminuído devido ao custo da solução. A escolha de uma boa política aliada a uma forma de armazenamento suficientemente adequada à situação pode trazer ao administrador um custo compatível com o valor da informação que ele deseja salva-guardar.
Tipos de backup
O tipo de backup a ser utilizado varia de acordo com cada organização, dependendo da quantidade de informação, e da velocidade que estas informações são atualizadas, cabe ao administrador de rede e/ou gestor de política de segurança analisar e definir a melhor forma. Basicamente existem 3 tipos.
Backups totais
Um backup total captura todos os dados, incluindo arquivos de todas as unidades de disco rígido. Cada arquivo é marcado como tendo sido submetido a backup; ou seja, o atributo de arquivamento é desmarcado ou redefinido. Uma fita atualizada de backup total pode ser usada para restaurar um servidor completamente em um determinado momento.
Vantagens :
- Cópia total dos dados: isso significa que você tem uma cópia completa de todos os dados e se for necessária uma recuperação do sistema torna-se mais prático.
- Acesso rápido aos dados de backup: não é necessário pesquisar em várias fitas para localizar o arquivo que deseja restaurar, porque os backups totais incluem todos os dados contidos nos discos rígidos em um determinado momento.
Desvantagens:
- Dados redundantes: backups totais mantêm dados redundantes, porque os dados alterados e não alterados são copiados para fitas sempre que um backup total é executado.
- Tempo: backups totais levam mais tempo para serem executados e podem ser muito demorados.
- Espaço em midia: manter várias versões de backups totais exige uma quantidade grande de midia para essa finalidade (ex: fitas ou discos rígidos)
Backups incrementais
Backup incremental captura todos os dados que foram alterados desde o backup total ou incremental mais recente. Você deve usar uma fita de backup total (não importa há quanto tempo ela tenha sido criada) e todos os conjuntos de backups incrementais subseqüentes para restaurar um servidor. Um backup incremental marca todos os arquivos como tendo sido submetidos a backup; ou seja, o atributo de arquivamento é desmarcado ou redefinido.
Vantagens:
- Uso eficiente do tempo: o processo de backup leva menos tempo porque apenas os dados que foram modificados ou criados desde o último backup total ou incremental são copiados para a fita.
- Uso eficiente da mídia de backup: o backup incremental usa menos fita porque apenas os dados que foram modificados ou criados desde o último backup total ou incremental são copiados para a fita.
Desvantagens:
- Restauração completa complexa: pode ser necessário restaurar os dados de um conjunto incremental de várias fitas para obter uma restauração completa do sistema.
- Restaurações parciais demoradas: pode ser necessário pesquisar em várias fitas para localizar os dados necessários para uma restauração parcial.
Há uma variação desse tipo de backup em que a cada backup se armazenam somente as partes dos arquivos que foram modificadas, ao invés de salvar todos os arquivos alterados. Desta forma se aproveita melhor o espaço disponível na midia de backup, porém ao custo de maior processamento para identificar os dados alterados e também para recuperar versões de arquivos.
Backups diferenciais
Um backup diferencial captura os dados que foram alterados desde o último backup total. Você precisa de uma fita de backup total e da fita diferencial mais recente para executar uma restauração completa do sistema. Ele não marca os arquivos como tendo sido submetidos a backup (ou seja, o atributo de arquivamento não é desmarcado).
Vantagem:
- Restauração rápida: a vantagem dos backups diferenciais é que eles são mais rápidos do que os backups incrementais, porque há menos fitas envolvidas. Uma restauração completa exige no máximo dois conjuntos de fitas — a fita do último backup total e a do último backup diferencial.
Desvantagens:
- Backups demorados e maiores: backups diferenciais exigem mais espaço em fita e mais tempo do que backups incrementais porque quanto mais tempo tiver se passado desde o backup total, mais dados haverá para copiar para a fita diferencial.
- Aumento do tempo de backup: a quantidade de dados dos quais é feito backup aumenta a cada dia depois de um backup total.
Modos de backup
O modo de backup determina como o backup deve ser executado em relação ao tipo de dados a serem incluídos nele. Há duas maneiras de executar os backups de dados.
Backup online
São backups feitos em servidores que precisam estar 24h por dia disponível aos usuários. Geralmente são banco de dados, servidores de e-mail, etc. Um detalhe bastante importante é que o software de backup e a aplicação precisam ter suporte a este tipo de backup.
Vantagem:
- Servidor sempre disponível podendo ser realizado o backup durante o expediente normal de trabalho.
Desvantagem:
- O desempenho do servidor é prejudicado durante a realização do backup.
Backup offline
São backups de dados feito quando ninguém está tentando acessar as informações. Geralmente é agendado para ser realizado à noite.
Vantagem:
- Como o servidor estará apenas fazendo o backup dos dados é mais rápido que o processo de backup on-line.
Desvantagem:
- Ninguém poderá acessar os dados durante a execução do backup.
Softwares de backup
Existem muitos softwares de backup que combinam diferentes características como as apontadas nas subseções anteriores.
- Lista de softwares de backup obtida na Wikipedia
- Uma comparação entre softwares de backup feita pelo pelo projeto Box Backup
Dentre os softwares listados, escolheu-se Amanda por razões históricas e por seu funcionamento razoavelmente simples.
Amanda
O Amanda (Advanced Maryland Automatic Network Disk Archiver) é um sistema de backup cliente/servidor. Um servidor Amanda realiza num único dispositivo de armazenamento (fita ou disco rígido) o backup de qualquer número de computadores que tenham o cliente do Amanda e uma conexão de rede com o servidor. Um problema comum em locais com um grande número de discos é que a quantidade de tempo requerida para o backup dos dados diretamente na fita excede a quantidade de tempo para a tarefa. O Amanda resolve este problema utilizando um disco auxiliar para realizar o backup de diversos sistemas de arquivos ao mesmo tempo. O Amanda cria “conjuntos de arquivos”: um grupo de fitas utilizadas sobre o tempo para criar os backups completos de todos os sistemas de arquivos listados no arquivo de configuração do Amanda. O “conjunto de arquivos” também pode conter backups incrementais (ou diferenciais) noturnos de todos os sistemas de arquivos. Para restaurar um sistema de arquivos é necessário o backup completo mais recente e os incrementais, este controle é feito pelo próprio Amanda.
O arquivo de configurações provê um controle total da realização dos backups e do tráfego de rede que o Amanda gera. O Amanda utilizará qualquer programa de backup para gravar os dados nas fitas, por exemplo tar. O Amanda está disponível como pacote na maioria das distribuições Linux, e também em código fonte, porém ele não é instalado por padrão.
Referências sobre Amanda:
Para instalar o servidor Amanda no Ubuntu devem-se executar os seguintes comandos:
sudo apt-get install amanda-common
sudo apt-get install amanda-server
sudo apt-get install dump
Para instalar o cliente Amanda:
sudo apt-get install amanda-common
sudo apt-get install amanda-client
Após a instalação o diretório de configuração padrão /etc/amanda estará criado, porém sem os arquivos de configuração. Esses podem ser obtidos de um exemplo. Em seguida deve-se adaptar a configuração para a nova instalação, usando-se o manual online quando necessário:
- man amanda
- man amanda.conf
- man amanda-client.conf
Como exemplo pode-se configurar o sistema para um backup fictício, já que não dispomos de unidades de fita para um verdadeiro backup. Para “Backup em HD com Amanda” pode-se ver um tutorial. Há também uma documentação mais detalhada no sitio do Amanda.
Atividade
- Instale configure o Amanda para atender a seguinte lista de configurações:
- Fita do tipo HARD-DISK
- Número de fitas disponíveis igual a 20.
- Rótulos nas fitas Gerencia.
- Ciclo de dumps igual a 5 dias.
- Nome da organização Gerencia.
- Acrescente um cliente, que corresponde a um diretório de localhost a ser salvo no backup.
- Faça alguns backups, e investigue onde e como os backups foram salvos (comando amcheck Gerencia)
- Recupere um dos backups, gravando os arquivos em um diretório a parte
- Acrescente um computador de um colega como cliente
- Repita o procedimento de backup e recuperação
15/03: Shell scripts para automatizar tarefas
Capítulo 21 da apostila.
- Shell scripts: programas interpretados pelo shell (no nosso caso, bash)
- Estrutura de um shell script:
#!/bin/bash # Este programa diz alo echo "Alo $LOGNAME, tenha um bom dia!"
- Variáveis:
- Definição de variáveis
- Mostrando o valor de variáveis
#!/bin/bash dir=/home/aluno desktop=$dir/Desktop echo Seu diretorio home é $dir echo Sua área de trabalho do ambiente gráfico fica no diretório $desktop
- Forma alternativa de mostrar valores de variáveis:Repare nas chaves em volta do nome da variável. Isto é particularmente necessário quando se deseja delimitar o nome da variável, como no exemplo abaixo:
#!/bin/bash dir=/home/aluno desktop=${dir}/Desktop echo Seu diretorio home é ${dir} echo Sua área de trabalho do ambiente gráfico fica no diretório ${desktop}
#!/bin/bash basedir=/home/aluno # a sentença abaixo funciona como esperado echo aluno1 tem diretório home ${basedir}1 # ... mas esta a seguir não ! echo aluno1 tem diretório home $basedir1
- Forma alternativa de mostrar valores de variáveis:
- Argumentos de execução do shell
#!/bin/bash echo Quantidade de argumentos: $# echo Os argumentos são: $* echo Nome do script: $0 echo Primeiro argumento: $1 echo Segundo argumento: $2
- Mostrando parte do conteúdo de uma variável (o equivalente a substrings):
#!/bin/bash letras=abcdefghjijklmnopqrstuvwxyz echo Todas as letras: ${letras} echo Quantidade de caracteres na variável letras: ${#letras} echo a primeira letra: ${letras:0:1} echo 5 primeiras letras: ${letras:0:5} echo a última letra: ${letras:${#letras}-1} echo 5 últimas letras: ${letras:${#letras}-5:${#letras}} echo ... ou ... ${letras:${#letras}-5} echo a primeira metade das letras: ${letras:0:${#letras}/2} echo a segunda metade das letras: ${letras:${#letras}/2}
- Tratando variáveis que podem estar indefinidas ou vazias:
#!/bin/bash x=ok echo Variavel x=${x} # Mostra o valor "vazia", porque y é uma variável indefinida, mas não altera y echo Variavel y=${y:-vazia} echo Variavel y=${y} # Mostra o valor "vazia", porque y é uma variável indefinida, e faz com que y="vazia" echo Variavel y=${y:=vazia} echo Variavel y=${y}
- Variáveis predefinidas: LOGNAME, HOME, PATH, MAIL, EDITOR, PAGER, SHELL, TERM, HOST, ...
- Captura do resultado da execução de comandos
#!/bin/bash resultado=$(ls $HOME | wc -l) echo Existem $resultado arquivos ou diretórios em $HOME
- Expressões aritméticas:
#!/bin/bash x=1 y=3 # Abaixo apenas concatena os valores de x e y echo x + y = ${x} + ${y} # Abaixo faz a soma de x e y echo x + y = $((${x} + ${y}))
- Estruturas condicionais:
- Teste de condição: se condição então ... senão ... fimSe
#!/bin/bash # Este programa também diz alo if [ "$LOGNAME" = "root" ]; then echo "Alo SENHOR, tenha um bom dia ... e às suas ordens !" else echo "Alo $LOGNAME, tenha um bom dia." fi
- Condições a serem usadas no if ... then ... else se baseiam no programa test. Alguns exemplos:
x=0 y=1 # operador -eq: igualdade numerica if [ $x -eq 0 ]; then echo Variavel x zerada fi # operador -o: OU logico if [ $x -eq 1 -o $y -eq 1 ]; then echo Uma das variáveis x ou y tem valor diferente de zero fi # operador -a: E logico if [ $x -eq 1 -a $y -eq 1 ]; then echo Ambas variáveis x ou y tem valor diferente de zero fi # operador -le: <= (less or equal) if [ $x -le 10 ]; then echo Variável x menor ou igual a 10 fi # operador -lt: < (less than) if [ $x -lt 10 ]; then echo Variável x menor que 10 fi # operador -ge: >= (greater or equal) if [ $x -ge 10 ]; then echo Variável x maior ou igual a 10 fi # operador -gt: > (greater than) if [ $x -gt 10 ]; then echo Variável x maior que 10 fi # operador !: NEGACAO if [ ! $x -gt 10 ]; then echo Variável x menor ou igual a 10 fi
- Variações do uso do teste condicional:
if comando then comandos executados se "comando" retornar status "ok" (0) else comandos executados se "comando" retornar status "não ok" (diferente de 0) fi if comando1 then comandos executados se "comando1" retornar status "ok" (0) elif comando2 comandos executados se "comando2" retornar status "ok" (0) else comandos executados se não entrar nos "if" acima fi comando1 && comando2 # construção na linha acima eh equivalente a (porta E): if comando1 then comando2 fi comando1 || comando2 # construção na linha acima eh equivalente a (porta OU): if comando1 then : else comando2 fi
- Condições a serem usadas no if ... then ... else se baseiam no programa test. Alguns exemplos:
- Selecionando entre múltiplos valores:
#!/bin/bash case $x in 0) echo x=zero ;; 1) echo x=um ;; *) echo x desconhecido: $x ;; esac
- Teste de condição: se condição então ... senão ... fimSe
Programas úteis
Os programas utilitários abaixo são comumente usados em shell scripts:
- basename: mostra o prefixo de um pathname (ex: ao executar dirname /home/aluno/Desktop se obtém /home/aluno)
- dirname: mostra o último componente de um pathname (ex: ao executar basename /home/aluno/Desktop se obtém Desktop)
- cut: divide as linhas dos arquivos em colunas, e mostra colunas específicas
- grep: mostra linhas de arquivos que contenham determinada palavra ou padrão de caracteres
- sort: ordena as linhas de um arquivo
- paste: combina linhas de arquivos
- wc: conta linhas, palavras e caracteres
- tail: mostra as últimas linhas de um arquivo
- head: mostra as primeiras linhas de um arquivo
- du: mostra a utilização de disco de um determinado arquivo ou diretório
Atividade
- Faça um script que mostre os 5 usuários que estão ocupando mais espaço em seus diretórios home.
- Modifique o script acima para que a quantidade de usuários a serem mostrados seja parametrizada.
- Faça um script que obtenha o código fonte de um programa, descompacte-o e compile-o, e, finalmente, instale-o. Assuma que o software esteja compactado com tar e gzip, e que para compilá-lo deve-se seguir o procedimento visto na aula de 11/02. Para testá-lo use o programa lynx, cujo código fonte se encontra aqui.
- Faça um script que mostre o nome completo de um usuário, a partir do seu login informado como argumento de linha de comando.
Solução 1:Solução 2 (mais simples, porém só funciona para usuários locais):#!/bin/bash usuario=${1:?Informe um usuario} nome=$(finger $usuario | head -1) nome=$(echo $nome | cut -d" " -f4-) echo Nome completo: ${nome:-INEXISTENTE!!!}
#!/bin/bash usuario=${1:?Informe um usuario} nome=$(grep ${usuario} /etc/passwd | cut -d: -f5) echo Nome completo: ${nome:-INEXISTENTE !!!}
- Faça um script que mostre os grupos a que pertence um usuário. Esse script deve consultar os arquivos /etc/passwd e /etc/group.
Solução 1: funciona, mas pode mostrar grupos errados se o usuário informado for uma substring do nome de outro usuário:Solução 2: trata o caso que geraria erro na solução 1:#!/bin/bash usuario=${1:?Informe um usuario} grupos=$(grep ${usuario} /etc/group | cut -d: -f1) echo Grupos: ${grupos}
#!/bin/bash usuario=${1:?Informe um usuario} grupos=$(grep -E "(:${usuario}|,${usuario}$|,${usuario},)" /etc/group | cut -d: -f1) echo Grupos: ${grupos}
- Faça um script que mostre o seguinte resultado, para um dado usuário:
Quantidade de processos para um_usuario: um_numero Os PIDs de seus processos são: lista de PIDs
- Script apaga contas sem uso: sabe-se que a cada logon do usuário, pelo menos um de seus arquivos é modificado. Sabe-se também que o usuário tem arquivos em /home/nome_do_usuario e em /home/samba/profiles/home_do_usuario. Faça um script teste se um dado usuário não se logou faz mais de 12 meses, e remova sua conta caso afirmativo. Obs: ao remover a conta o script deve salvar uma cópia dos arquivos do usuário, usando o programa tar combinado com gzip.
18/03: Shell scripts para automatizar tarefas
Continuação do conteúdo da aula anterior, que foi somente até variáveis. Estruturas de repetição:
- for:
#!/bin/bash for dir in /home/*; do echo Diretório: ${dir} done for x in 1 2 3 4 5; do echo x = ${x} done for (( x=1; $x < 5; x=$x+1 )); do echo x=$x done
- while:
#!/bin/bash # enquanto x <= 5 while [ ${x} -le 5 ]; do echo $x x=$(($x+1)) done # Mostra os processos do usuario aluno, enquanto ele estiver logado while (who | grep aluno > /dev/null); do date ps aux | grep aluno echo "" sleep 5 done
Atividades
- Faça um script que estabeleça cotas a todos os usuários do sistema, a partir do usuário padrão de nome modelo.
Solução:#!/bin/bash lista=$(cut -d: -f1 /etc/passwd) for usuario in $lista; do if [ ${usuario} != root ]; then edquota -p modelo $usuario fi done
- Em um diretório existem diversos arquivos compactados com zip, como se pode ver abaixo: Faça um script que descompacte cada arquivo desses em um subdiretório que tenha o nome do arquivo em questão, porém excluída sua extensão (ex: para banana.zip, deve-se descompactá-lo dentro de "banana"). Dica: use o esqueleto de script mostrado abaixo:
$ ls arq1.zip banana.zip laranja.zip $
Você pode usar os arquivos .zip contidos nesse arquivo (que está no formato TAR, apesar da extensão .pdf ...) Solução:#!/bin/bash for arq in *.zip; do echo $arq done
#!/bin/bash for arq in *.zip; do base=$(basename $arq .zip) mkdir $base cd $base unzip ../$arq cd .. done
- Script apaga contas sem uso: sabe-se que a cada logon do usuário, pelo menos um de seus arquivos é modificado. Sabe-se também que o usuário tem arquivos em /home/nome_do_usuario e em /home/samba/profiles/nome_do_usuario. Faça um script que apague usuários que não se logaram nos últimos 12 meses. Dica: use o script abaixo como ponto de partida, mas note que ele testa apenas um usuário (informado via argumento de linha de comando): Solução 1: assumindo que todo usuário tenha seu diretório home dentro de /home
#!/bin/bash usuario=${1:?Uso: $0 usuario} ok=$(find /home/$usuario -mtime -365 | wc -l) if [ $ok == 0 ]; then echo Removendo o usuario $usuario # Comando para executar o usuario else echo usuario $usuario nao serah removido ... fi
Solução 2: obtendo os usuários a partir de /etc/passwd (e filtrando os usuários de sistema, que possuem UID < 1000)#!/bin/bash cd /home for usuario in *; do ok=$(find /home/$usuario -mtime -365 | wc -l) ok2=$(find /home/samba/profiles/$usuario -mtime -365 |wc -l) if [ $ok -eq 0 -a $ok2 == 0 ]; then echo removendo conta else echo conta não será removida fi done
#!/bin/bash for usuario in $(cut -d: -f1 /etc/passwd); do uid=$(grep ^${usuario}: /etc/passwd | cut -d: -f3) if [ $uid -ge 1000 ]; then ok=$(find /home/$usuario -mtime -365 | wc -l) ok2=$(find /home/samba/profiles/$usuario -mtime -365 |wc -l) if [ $ok -eq 0 -a $ok2 -eq 0 ]; then echo removendo conta else echo conta não será removida fi fi done
- Script de alerta de quota a exceder: faça um script que verifica as quotas de todos os usuários, e gere uma lista de usuários cujas quotas estão excedidas ou prestes a exceder.
- Script trava contas coletivas: a saída do comando smbstatus |grep alunos é algo parecido com: Faça um script que gere uma lista das contas de alunos que estão sendo utilizadas por mais de uma pessoa em máquinas distintas ao mesmo tempo. Para isto deve-se rodar o dito comando a cada 5 minutos e verificar os usuários em duplicata, afonso no exemplo. O smbstatus tem um “retardo” que pode acusar dois logins simultâneos, mesmo isto não sendo verdade, para eliminar as duplicidades incorretas, deve-se analisar duas coletas seqüenciais e eliminar os casos em que a duplicidade de usuário não ocorre. Em resumo, se em uma coleta houver duplicidade, analisa-se a próxima, se o mesmo usuário estiver duplicado insere-se o mesmo na lista de contas coletivas.
7175 afonso alunos negreiros (192.168.1.161) 12168 afonso alunos idal (192.168.1.222) 12141 jessica alunos haley (192.168.1.169) 8443 vitorsd alunos costelo (192.168.1.144) 11326 felipesl alunos baraovermelho (192.168.1.113) 12641 1521 alunos 200.135.233.1 (200.135.233.1)
22/03: Shell scripts para automatizar tarefas
Continuação dos exercícios da aula de 18/03
25/03: 1a avaliação
1a avaliação individual
29/03: Serviços de rede
Visão geral de serviços e funções de rede típicos: Configuração de interfaces de rede. Noções de roteamento.
Ver capítulo 22 da apostila.
Correção da avaliação feita em 25/03
Parte prática:
- Questão 1: A solução envolve quatro tarefas:
- Particionar os discos, preparando-os para criação do volume RAID 1:
# Os discos devem aparecer como /dev/sdb e /dev/sdc # Para cada um dos discos, cria uma partição primária ocupando todo o disco. Marca como sendo tipo 8e (Linux LVM) fdisk /dev/sdb fdisk /dev/sdc
- Criação do volume RAID1 usando as partições criadas na tarefa 1:
# Cria um volume RAID 1 composto pelas partições dos discos acima, o qual será chamado de /dev/md0 mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1 # Grava a configuração do volume RAID, para que seja automaticamente reativado no boot mdadm --detail --scan >> /etc/mdadm/mdadm.conf
- Criação de um Volume Group LVM, usando como volume físico o volume RAID 1 criado na tarefa 2; criação de um volume lógico para cada sistema de arquivos:
# Prepara o volume RAID 1 para ser usado como volume físico LVM lvm pvcreate /dev/md0 # Cria o Volume Group, usando o volume RAID 1 como volume físico lvm vgcreate prova /dev/md0 # Cria um volume lógico para cada sistema de arquivos lvm lvcreate prova -L 1024M -n dir lvm lvcreate prova -L 800M -n cont lvm lvcreate prova -L 1200M -n tec lvm lvcreate prova -L 400M -n col # Formata os volumes lógicos mkfs.ext4 -j /dev/prova/dir mkfs.ext4 -j /dev/prova/cont mkfs.ext4 -j /dev/prova/tec mkfs.ext4 -j /dev/prova/col
- Criação dos pontos de montagem, e adição dos novos sistemas de arquivos a /etc/fstab:
# Cria os pontos de montagem for d in dir tec col cont; do mkdir -p /dados/$d done # adiciona os pontos de montagem a /etc/fstab for d in dir tec col cont; do echo "/dev/prova/$d /dados/$d ext4 defaults,quota 0 2" >> /etc/fstab done # Monta os sistemas de arquivos mount -a
- Particionar os discos, preparando-os para criação do volume RAID 1:
- Questão 2:
- Criação dos grupos diretoria, contabilidade, tecnologo e colaboradores, e de dois usuários para cada grupo:
for g in diretoria contabilidade tecnologo colaboradores; do groupadd $g done # usuarios da diretoria useradd -g diretoria -c "Diretor 1" -m dir1 useradd -g diretoria -c "Diretor 2" -m dir2 # esses usuarios devem tambem ser membros dos demais grupos ... for g in contabilidade tecnologo colaboradores; do usermod -G $g dir1 usermod -G $g dir2 done # usuarios da contabilidade useradd -g contabilidade -c "Contador 1" -m cont1 useradd -g contabilidade -c "Contador 2" -m cont2 # usuarios tecnologos useradd -g tecnologo -c "Tecnologo 1" -m tec1 useradd -g tecnologo -c "Tecnologo 2" -m tec2 # usuarios colaboradores useradd -g colaboradores -c "Colaborador 1" -m col1 useradd -g colaboradores -c "Colaborador 2" -m col2
- Definição dos grupos donos dos diretórios, e suas permissões:
# define os grupos donos dos diretorios chgrp diretoria /dados/dir chgrp contabilidade /dados/cont chgrp tecnologo /dados/tec chgrp colaboradores /dados/col # define as permissoes de acesso chmod g+rwx /dados/* chmod o-rwx /dados/dir chmod o-rwx /dados/cont chmod o-rwx /dados/tec chmod o+rx-w /dados/col
- Ativação de quotas e definição das quotas dos usuários:
# Primeiro deve-se inicializar o sistema de quotas nos sistemas de arquivos quotacheck -va # Definir as quotas dos usuários setquota -u dir1 150000 200000 0 0 /dados/dir setquota -u dir1 120000 150000 0 0 /dados/cont setquota -u dir1 800000 100000 0 0 /dados/tec setquota -u dir1 40000 50000 0 0 /dados/col edquota -p dir1 dir2 setquota -u cont1 120000 150000 0 0 /dados/cont edquota -p cont1 cont2 setquota -u tec1 800000 100000 0 0 /dados/tec edquota -p tec1 tec2 setquota -u col1 40000 50000 0 0 /dados/col edquota -p col1 col2 # Ativar as quotas quotaon -va
- Criação dos grupos diretoria, contabilidade, tecnologo e colaboradores, e de dois usuários para cada grupo:
- Questão 3:
- Escrever o script de faxina, que será gravado em /root/limpa.sh:
#!/bin/bash dir=${1:?Faltou o diretorio ... Uso: $0 diretorio N M} N=${2:?Faltou N ... Uso: $0 diretorio N M} M=${1:?Faltou M ... Uso: $0 diretorio N M} # Lista de arquivos a compactar. Exclui os arquivos já compactados por este script # (esses arquivos terão acrescidos a si o sufixo -FAXINA, e depois serão compactados) lista_compact=$(find $dir -type f -atime +$N ! -name "*-FAXINA.gz") # Lista de arquivos a remover (somente os compactados por este script) lista_remove=$(find $dir -type f -atime +$M -name "*-FAXINA.gz") # Compacta os arquivos que estã faz N dias sem acesso for arq in $lista_compact; do mv $arq ${arq}-FAXINA gzip ${arq}-FAXINA done # Remove os arquivos compactados que estão faz M dias sem acesso for arq in $lista_remove; do rm -f $arq done
- Editar a crontab, para que o script seja executado nos dias e horários especificados:
$ crontab -e 0 23 1-5 * * /root/scripts/limpa.sh /dados/dir 30 60 15 23 1-5 * * /root/scripts/limpa.sh /dados/cont 30 30 30 23 1-5 * * /root/scripts/limpa.sh /dados/tec 15 30 59 23 1-5 * * /root/scripts/limpa.sh /dados/col 7 15
- Escrever o script de faxina, que será gravado em /root/limpa.sh:
Visão geral de serviços de rede

- DHCP: configuração automática de endereços IP em máquinas clientes
- DNS: serviço de nomes, que associa nomes a endereços IP, entre outras finalidades.
- LDAP: serviço de diretórios (um banco de dados hierárquico), para guardar informações administrativas, tais como usuários, grupos e contatos de email, usadas por outros serviços de rede.
- HTTP: acesso a documentos em geral (uso mais notório para acesso a páginas Web)
- FTP: transferência de arquivos
- SMTP, IMAP4, POP3, LMTP: protocolos para envio de email e acesso a caixas de entrada
- NFS e Samba: sistemas de arquivos de rede
- Web proxy: controle de acesso e cache para acesso a WWW
- NAT: tradução transparente de endereços IP, para mascarar endereços internos de uma rede (função de rede)
- Filtro IP: restrições aplicadas a tráfego IP, visando melhorar o nível de segurança (função de rede)
- SSH: acesso remoto seguro ao shell em um servidor
- VPN: redes privativas virtuais
Interfaces de rede
Qualquer dispositivo (físico ou lógico) capaz de transmitir e receber datagramas IP. Interfaces de rede ethernet são o exemplo mais comum, mas há também interfaces PPP (seriais), interfaces tipo túnel e interfaces loopback. De forma geral, essas interfaces podem ser configuradas com um endereço IP e uma máscara de rede, e serem ativadas ou desabilitadas. Em sistemas operacionais Unix a configuração de interfaces de rede se faz com o programa ifconfig:
Para mostrar todas as interfaces:
dayna@dayna:~> ifconfig -a
dsl0 Link encap:Point-to-Point Protocol
inet addr:189.30.70.200 P-t-P:200.138.242.254 Mask:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1492 Metric:1
RX packets:34260226 errors:0 dropped:0 overruns:0 frame:0
TX packets:37195398 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:3
RX bytes:19484812547 (18582.1 Mb) TX bytes:10848608575 (10346.0 Mb)
eth1 Link encap:Ethernet HWaddr 00:19:D1:7D:C9:A9
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:37283974 errors:0 dropped:0 overruns:0 frame:0
TX packets:42055625 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:20939614658 (19969.5 Mb) TX bytes:18284980569 (17437.9 Mb)
Interrupt:16 Base address:0xc000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:273050 errors:0 dropped:0 overruns:0 frame:0
TX packets:273050 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:21564572 (20.5 Mb) TX bytes:21564572 (20.5 Mb)
dayna@dayna:~>
Para configurar uma interface de rede (que fica automaticamente ativada):
dayna@dayna:~> ifconfig eth1 192.168.1.100 netmask 255.255.255.0
Para desativar uma interface:
dayna@dayna:~> ifconfig eth1 down
Para ativar uma interface:
dayna@dayna:~> ifconfig eth1 up
Ao se configurar uma interface de rede, cria-se uma rota automática para a subrede diretamente acessível via aquela interface. Isto se chama roteamento mínimo.
dayna@dayna:~> ifconfig eth1 192.168.10.0 netmask 255.255.0.0
dayna@dayna:~> netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
192.168.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth1
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo
dayna@dayna:~>
Pode-se associar mais de um endreço a uma mesma interface de rede. Isto se chama IP alias:
dayna@dayna:~> ifconfig eth1:0 192.168.1.110 netmask 255.255.255.0
dayna@dayna:~> ifconfig eth1:1 192.168.2.100 netmask 255.255.255.0
dayna@dayna:~> ifconfig -a
eth1 Link encap:Ethernet HWaddr 00:19:D1:7D:C9:A9
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:37295731 errors:0 dropped:0 overruns:0 frame:0
TX packets:42068558 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:20942258027 (19972.0 Mb) TX bytes:18294794452 (17447.2 Mb)
Interrupt:16 Base address:0xc000
eth1:0 Link encap:Ethernet HWaddr 00:19:D1:7D:C9:A9
inet addr:192.168.1.110 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:16 Base address:0xc000
eth1:1 Link encap:Ethernet HWaddr 00:19:D1:7D:C9:A9
inet addr:192.168.2.100 Bcast:192.168.2.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:16 Base address:0xc000
dayna@dayna:~>
Configuração no boot
Todo sistema operacional possui alguma forma de configurar suas interfaces de rede, para que sejam automaticamente ativadas no boot com seus endereços IP. Por exemplo, em sistemas Linux Ubuntu (descrito em maiores detalhes em seu manual online), a configuração de rede se concentra no arquivo /etc/network/interfaces:
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
address 127.0.0.1
netmask 255.0.0.0
# a interface ethernet eth1
iface eth1 inet static
address 192.168.1.100
netmask 255.255.255.0
gateway 192.168.1.254
Esses arquivo é lido pelos scripts ifup e ifdown. Esses scripts servem para ativar ou parar interfaces específicas, fazendo todas as operações necessárias para isto:
# Ativa a interface eth1
ifup eth1
# Desativa a interface eth1
ifdown eth1
Para ativar, desativar ou recarregar as configurações de todas as interfaces de rede:
# desativa todas as interfaces de rede
sudo /etc/init.d/networking stop
# ativa todas as interfaces de rede
sudo /etc/init.d/networking start
# recarrega as configurações de todas as interfaces de rede
sudo /etc/init.d/networking restart
Rotas estáticas
Rotas estáticas podem ser adicionadas a uma tabela de roteamento. Nos sistemas operacionais Unix, usa-se o programa route:
# adiciona uma rota para a rede 10.0.0.0/24 via o gateway 192.168.1.254
route add -net 10.0.0.0 netmask 255.255.255.0 gw 192.168.1.254
# adiciona uma rota para a rede 172.18.0.0/16 via a interface PPP pp0
route add -net 172.18.0.0 netmask 255.255.0.0 dev ppp0
# adiciona a rota default via o gateway 192.168.1.254
route add default gw 192.168.1.254
# adiciona uma rota para o host 192.168.1.101 via o gateway 192.168.1.253
route add -host 192.168.1.101 gw 192.168.1.253
A tabela de rotas pode ser consultada com o programa netstat:
dayna@dayna:~> netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
10.0.0.0 192.168.1.254 255.255.255.0 U 0 0 0 eth1
192.168.1.101 192.168.1.253 255.255.255.0 UH 0 0 0 eth1
172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 ppp0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo
0.0.0.0 192.168.1.254 0.0.0.0 U 0 0 0 eth1
Rotas podem ser removidas também com route:
# remove a rota para 10.0.0.0/24
route delete -net 10.0.0.0 netmask 255.255.255.0
# remove a rota para o host 192.168.1.101
route delete -host 192.168.1.101
Atividade
- Verifique a configuração de sua interface de rede eth1, na máquina virtual Tecnologo-ger2. Se necessário corrija-a assim: ip 192.168.2.X, sendo X o número do computador + 100 (exemplo: para o micro 2 X=102), roteador default = 192.168.2.1.
- Teste a comunicação do seu computador, fazendo ping 192.168.2.1. Tente pingar outras máquinas da rede.
- Tente também pingar o IP 200.135.37.65.
- Veja a tabela de rotas, usando netstat -rn.
- Verifique a rota seguida pelos datagramas enviados, usando traceroute -n 200.135.37.65.
- Configure sua máquina virtual para que a informação de rede, configurada manualmente acima, fique permanente. Quer dizer, no próximo boot essa configuração deve ser ativada automaticamente.
- Adicione um IP alias a sua interface eth1. Esse novo IP deve estar na subrede 10.0.0.0.0/24
- Tente pingar os computadores de seus colegas, usando ambos endereços: da rede 192.168.2.0/24 e da rede 10.0.0.0/24.
- Enquanto acontecem os pings, visualize o tráfego pela interface eth1, usando o programa tcpdump:
# Mostra o tráfego ICMP que passa pela interface eth1 tcpdump -i eth1 -ln icmp - Pense em uma utilidade para IP alias ...