GER-2010-1
Gerência de Redes - semestre 2010-1
Informações gerais
Professor: Marcelo Maia Sobral
Email: msobral@gmail.com
Skype: mm-sobral
Lista de email (forum): ger-ifsc@googlegroups.com
Atendimento paralelo: 2a feira 10h - 12 h, 4a feira 10h - 12 h ou 16h - 17 h (no Laboratório de Desenvolvimento de Tele)
Reavaliação (recuperação): no final do semestre
Referências adicionais
- Valle, Odilson Tadeu. Gerência de Redes. IFSC - Unidade São José. 2009.
- Ubuntu Server Guide
- Guia Foca Linux (intermediário ou avançado)
- Demais referências contidas na página principal de GER.
08/02: Introdução
Apresentação da disciplina e do ambiente de trabalho. Instalação do Ubuntu Linux Server 9.10.
Foi apresentada uma visão geral sobre Gerência de Redes, que trata do projeto, implantação, manutenção e monitoramento de serviços de rede. Na disciplina há uma ênfase em servidores, que são equipamentos (usualmente computadores) que disponibilizam os serviços de rede. Normalmente existem vários servidores em uma rede, os quais operam com algum grau de integração (sejam as contas de usuários e grupos, sistemas de arquivos compartilhados, nomeação de recursos, e outros possíveis serviços). Uma discussão mais aprofundada se encontra na apostila, nos capítulos 1 e 11.
Instalou-se o Ubuntu Server 9.10 na máquina virtual tecnologo-ger2 (VirtualBox). Usou-se um particionamento manual que isola os sistemas de arquivos / (raiz), /usr, /var e /home, além da partição de swap. Enfatizou-se que o uso de apenas um sistema de arquivos, como sugerido pelo instalador do sistema operacional, não é a melhor opção para um servidor. Do contrário, se um sistema de arquivos ficar cheio (por exemplo, devido aos arquivos de usuários), podem-se comprometer os serviços mantidos no servidor, porque é comum que os processos que os implementam precisem criar arquivos temporários para trabalharem. Outros motivos têm relação com a intergidade dos sistemas de arquivos, pois aqueles que sofrem modificações continuamente estão mais sujeitos a ficarem corrompidos em caso de desligamento súbito da máquina, apesar de isto ser mais difícil atualmente com sistemas de arquivos com journaling. Finalmente, em servidores com mais de um volume físico para armazenamento, torna-se necessário ou interessante isolar um sistema de arquivos em um subconjunto desses volumes.
Os tamanhos escolhidos para esses sistemas de arquivos são:
- /: 512 MB
- /usr: 1.5 GB
- /var: 512MB
- swap: 512 MB
- /home: 120 MB aprox. (o que sobrou)
Esse particionamento serviu somente para a instalação inicial, e provavelmente será modificado em breve.
O único serviço de rede instalado foi o Openssh server.
11/02: O processo de boot e instalação de software
O boot
O processo de inicialização do sistema operacional, chamado de boot. Tradicionalmente no Unix System V isto se faz com a definição de níveis de execução (runlevels) e uma tabela que descreve que processos ou serviços devem existir em cada nível. Os níveis de execução são:
- Monousuário (single-user), ou administrativo: usado para manutenção do sistema, admite somente o login do superusuário. Não inicia serviços de rede.
- Multiusuário com rede (parcial): admite logins de usuários, mas não ativa acesso a recursos de rede (como sistemas de arquivo remotos)
- Multiusuário com rede plena
- Não usado
- Multiusuário com rede plena e ambiente gráfico: ativa também o ambiente gráfico X11
- Reinício do sistema (reboot)
As distribuições Linux em geral adotam a inicialização no estilo Unix System V. No entanto, o Ubuntu usa um outro processo chamado de upstart. Esse serviço de inicialização confere maior flexibilidade e mesmo simplicidade à definição de que serviços devem ser executados. O upstart não usa o conceito de níveis de execução, mas devido à sua flexibilidade ele pode emular esse estilo de inicialização. Para o upstart, um serviço deve ser iniciado ou parado dependendo de uma combinação de eventosm, sendo que um evento indica a ocorrência de uma etapa da inicialização.
O upstart é implementado pelo processo init (programa /sbin/init), que é o primeiro processo criado pelo sistema operacional. Quer dizer, logo após terminar a carga e inicialização do kernel, este cria um processo que executa o programa /sbin/init. O upstart lista o subdiretório /etc/init e procura arquivos com extensão .conf. Cada arquivo desses descreve um serviço a ser controlado pelo upstart. Por exemplo, o serviço tty2 é escrito no arquivo tty2.conf:
# tty2 - getty
#
# This service maintains a getty on tty2 from the point the system is
# started until it is shut down again.
start on runlevel [23]
start on runlevel [!23]
respawn
exec /sbin/getty -8 38400 tty2
Abaixo segue o significado de cada linha:
- start on runlevel [23]: o serviço deve ser iniciado quando ocorrerem os eventos "runlevel 2" ou "runlevel 3"
- stop on runlevel [!23]: o serviço deve ser parado quando ocorrer qualquer evento "runlevel X", sendo X diferente de 2 e 3
- respawn: o serviço deve ser reiniciado automaticamente caso termine de forma anormal
- exec /sbin/getty -8 38400 tty2: a ativação do serviço implica executar o /sbin/getty -8 38400 tty2
Em linhas gerais, a descrição do serviço informa quando ele deve ser ativado (start), quando deve ser parado (stop), o tipo de execução (respawn para reinício automático, ou task para uma única execução), e que ação deve ser executada para ativar o serviço (exec para executar um programa, ou script .. end script para executar uma sequência de comandos de shell). Maiores detalhes podem ser lidos na página de manual do init.
Um exemplo de criação de serviço no upstart
Foi proposta a criação de um serviço chamado faxineiro, para remover dos diretórios temporários (/tmp e /var/tmp) todos os arquivos que não tenham sido modificados há mais de um dia. Esse novo serviço deve ser executado no boot, logo após o serviço mountall. A solução encontrada foi a seguinte:
- Criar o arquivo /etc/init/faxineiro.conf
- Adicionar o seguinte conteúdo a esse arquivo:
start on filesystem task console output script find /tmp -type f -mtime +1 -exec rm -f {} \; -print find /var/tmp -type f -mtime +1 -exec rm -f {} \; -print echo Faxineiro executado \!\!\! end script - Reiniciar o sistema para testá-lo (executar reboot)
Instalação de software
A instalação de software pode ser feita de diversas formas, dentre as quais serão destacadas três:
- Com utilitário apt-get: busca o software de um repositório de rede e o instala; dependências (outros softwares necessários) são automaticamente instaladas. Esses softwares buscados da rede estão no formato dpkg (Debian Package). Exemplo de uso do apt-get:
# Instala o navegador de texto lynx apt-get install lynx # Testa o navegador lynx lynx http://www.ifsc.edu.br/ # Remove o lynx apt-get --auto-remove remove lynx
- Diretamente com utilitário dpkg: instala um software que está contido em um arquivo no formato dpkg. Exemplo de uso:
# Obtém os pacotes Debian para o lynx wget http://www.sj.ifsc.edu.br/~msobral/ger/lynx_2.8.7pre6-1_all.deb wget http://www.sj.ifsc.edu.br/~msobral/ger/lynx-cur_2.8.7pre6-1_i386.deb # Instala os pacotes dpkg -i lynx-cur_2.8.7pre6-1_i386.deb lynx_2.8.7pre6-1_all.deb # Testa o lynx lynx # Remove os pacotes instalados dpkg -r lynx lynx-cur
- A partir do código fonte: busca-se manualmente na rede o código fonte do software desejado, que deve então ser compilado e instalado. Esta opção se aplica quando não existe o software no formato dpkg, ou a versão disponível em formato dpkg foi compilada de uma forma que não atende os requisitos para seu uso em seu servidor.
18/02: RAID
RAID (Redundant Array of Independent Disks) se destina a combinar discos de forma a incrementar o desempenho de entrada e saída e, principalmente, segurança dos dados contra defeitos em discos. RAID pode ser provido via software ou hardware (melhor este último). O Linux possui implementação por software em seu kernel, e neste HOWTO há uma descrição resumida.
Há vários níveis RAID, que correspondem a diferentes combinações de discos e partições. São eles:
- LINEAR: concatena discos ou partições, mas não provê acréscimos de desempenho, nem de segurança dos dados (pelo contrário ! se um disco falhar, perdem-se todos os dados ...).
- RAID 0 (ou striping): combina discos ou partições de forma alternada, para distribuir os acessos entre eles (aumentar desempenho). Porém, se um disco falhar perdem-se todos os dados. Requer um mínimo de dois discos.
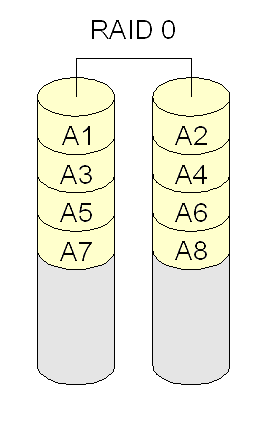
- RAID 1 (ou mirroring): combina discos ou partições para espelhar dados (segurança). Requer o dobro de discos necessários para guardar os dados (ex: se há dois discos com dados, são necessários outros dois para espelhamento). Se todos os discos falharem, é possível continuar a operar usando os discos espelhados. Requer no mínimo dois discos.
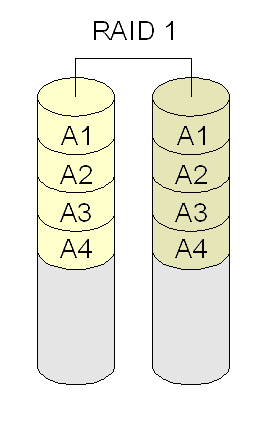
- RAID 4 e 5: combina discos ou partições para ter redundância de dados (segurança), usando um esquema baseado em paridade. Se um disco falhar, é capaz de continuar operando (porém com desempenho reduzido até que esse disco seja reposto). RAID 4 na prática não se usa, pois apresenta um gargalo no disco onde residem os blocos de paridades. Requer no mínimo três discos.
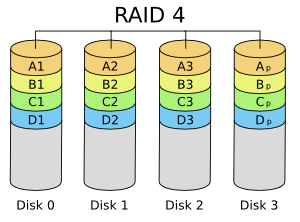
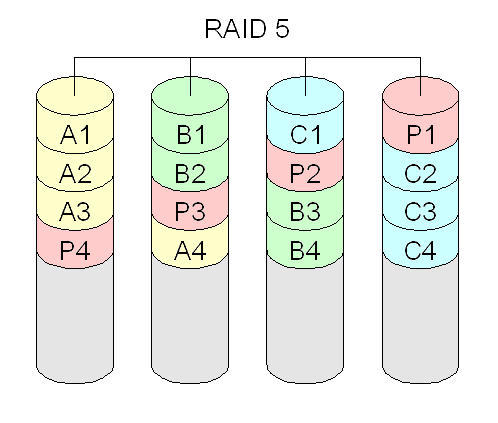
- RAID 6: combina discos ou partições para ter redundância de dados (segurança), usando um esquema baseado em paridade de forma duplicada. Isto garante que os dados se preservam mesmo que dois discos se danifiquem. Requer no mínimo quatro discos (pois há dois discos adicionais para paridades).
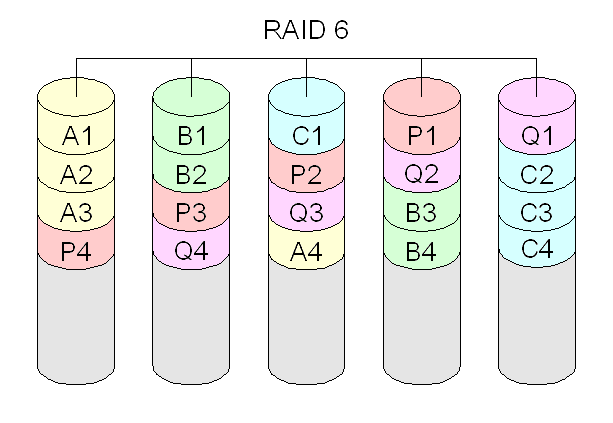
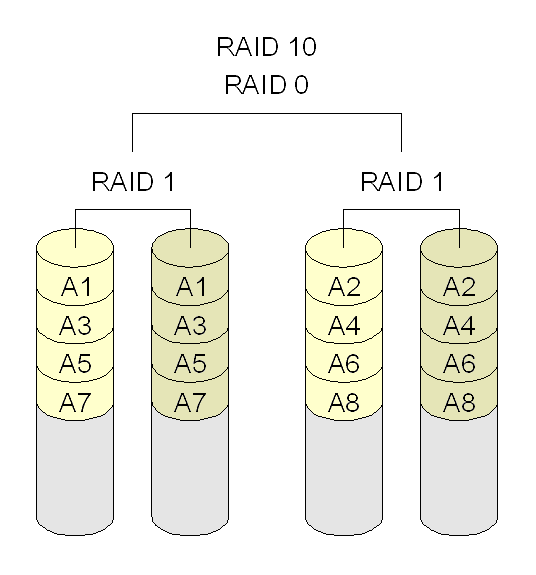
- RAID 10: combina RAID 1 e RAID 0, criando um volume com espelhamento (RAID 1), e depois fazendo o striping (RAID 0). Requer no mínimo quatro discos.
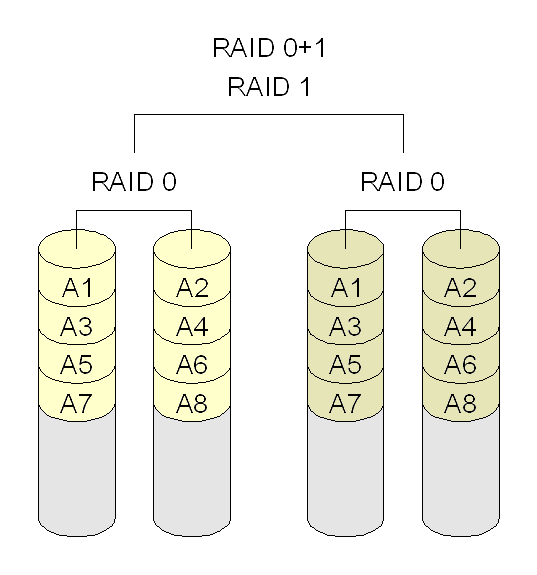
- RAID 01: combina RAID 0 e RAID 1, criando um volume com striping (RAID 0), e depois fazendo o espelhamento (RAID 1). Requer no mínimo quatro discos.







Criação de um volume RAID no Linux:
- Usar o comando mdadm --create --verbose /dev/md0 --level=NIVEL_RAID --raid-devices=NUM_PARTICOES PARTICAO_1 PARTICAO_2 ...
- NIVEL_RAID pode ser linear, 0, 1, 4, 5, 6, 10, mp, faulty (mais comuns são 0, 1 e 5).
- NUM_PARTICOES é a quantidade de partições usadas no volume.
- As partições são identificadas com o caminho (pathname) do dispositivo correspondente no Linux. Ex: a primeira partição do primeiro disco SCSI ou SATA é /dev/sda1, a segunda partição desse disco é /dev/sda2, a primeira partição do segundo disco SCSI ou SATA é /dev/sdb1, e assim por diante.
- /dev/md0 é o caminho do dispositivo que corresponde ao volume RAID a ser criado. O primeiro volume RAID é /dev/md0, o segundo é /dev/md1, e assim por diante.
- Formatar o volume RAID: mkfs.ext4 -j /dev/md0
- Uma vez testado o volume RAID, sua configuração pode ser salva para posterior uso: mdadm --detail --scan >> /etc/mdadm/mdadm.conf
- Isto é importante para que o volume possa ser ativado automaticamente no próximo boot.
Para ativar um volume já criado, basta executar mdadm --assemble caminho_do_volume. Ex: mdadm --assemble /dev/md0, mdadm --assemble /dev/md1.
Atividade:
- Crie duas partições de mesmo tamanho no disco /dev/sdb. Marque-as como sendo do tipo Linux RAID
- Crie um volume RAID nível 1 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
- Pare o volume existente, com mdadm -S /dev/md0
- Crie um volume RAID nível 0 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
- Pare o volume existente, com mdadm -S /dev/md0
- Crie um volume RAID nível 5 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
- Pare o volume existente, com mdadm -S /dev/md0
22/02: LVM
Armazenamento com Gerenciador de Volumes Lógicos (LVM). Ver páginas 57 e 58 da apostila.
Há um HOWTO com informação adicional sobre LVM no Linux, e outro com uma definição mais geral na Wikipedia.
LVM combina volumes físicos (ou PV, de Physical Volume), tais como discos, partições e volumes RAID, em uma abstração chamada grupo de volumes (ou VG, de Volume Group). Um VG funciona como um grande disco virtual, que pode ser dividido em volumes lógicos (LV, de Logical Volume). Cada LV pode ser usado para conter um sistema de arquivos, memória virtual (área de swap), ou qualquer outra finalidade de armazenamento (ex: área de dados de um banco de dados Oracle). A figura abaixo mostra a relação entre esses componentes, com exemplos de utilização dos LV:

Diagrama do LVM (obtido no Linux DevCenter)
Um resumo dos componentes do LVM segue abaixo:
- VG: Volume Group, que representa um disco lógico
- PE: Physical Extent, ou uma subdivisão do PV (são todas de mesmo tamanho), que funciona como unidade de alocação de espaço
- LE: Logical Extent, o equivalente ao PE, porém no contexto do LV
- PV: Physical Volume, ou uma partição física
- LV: Logical Volume, ou uma partição lógica criada dentro do VG
Em sua estrutura interna, o LVM divide cada PV em pequenas partições chamadas de PE (Physical Extent). Um tamanho típico para as PE é de 4 MB. Essas PE são usadas para alocar espaço para os LV, porém não há nenhuma relação entre a ordem física das PE nos PV e a ordem em que elas são alocadas aos LV - é normal inclusive PE de diferentes PV serem alocadas ao mesmo LV. Dentro de cada LV cada PE é chamada de LE (Logical Extent). A figura abaixo relaciona as PE com as LE dos LV:

Diagrama para LVM versão 1 (LVM1) no Linux.
Criação do LVM no Linux
A sequência de criação de um VG e seus LV é a seguinte:
- Criar partições físicas do tipo 8E (Linux LVM), que serão usadas para serem os PV
- Preparar essas partições para serem usadas como PV, usando o comando lvm pvcreate caminho_partição (ex: lvm pvcreate /dev/sdb1)
- Criar o VG, usando o comando lvm vgcreate nome_vg pv1 [pv2 ...] (ex: lvm vgcreate meu_vg /dev/sdb1 /dev/sdb2)
- Criar os LV, com o comando lvm lvcreate nome_vg -L tamanho_LV -n nome_LV (ex: lvm lvcreate meu_vg -L 512M -n teste)
- Formatar os LV (ex: mke4fs -j /dev/meu_vg/teste, para formatar com sistema de arquivos ext4)
Abaixo segue um exemplo de uma sequência de comandos relacionados com LVM, desde o particionamento de um disco até o redimensionamento de um LV existente:
# Prepara as partições (devem ser do tipo 8E (Linux LVM)
fdisk /dev/sdb
# Prepara essas duas partições para serem usadas como volumes físicos
lvm pvcreate /dev/sdb1
lvm pvcreate /dev/sdb2
# Cria o volume group "vg"
lvm vgcreate vg /dev/sdb1 /dev/sdb2
# Cria dentro do volume group "vg" um volume lógico "dados" com 512 MB iniciais
lvm lvcreate vg -L 512M -n dados
# Cria dentro do volume group "vg" um volume lógico "teste" com 256 MB iniciais
lvm lvcreate vg -L 256M -n teste
# Mostra informações sobre todos os volumes lógicos
lvm lvs
# Mostra detalhes sobre o volume lógico "dados", que pertence ao volume group "vg"
lvm lvdisplay /dev/vg/dados
# Formata o volume lógico "dados" com sistema de arquivos do tipo "ext4"
mkfs.ext4 -j /dev/vg/dados
# Formata o volume lógico "teste" com sistema de arquivos do tipo "xfs"
mkfs.xfs /dev/vg/dados
# Aumenta em 512 MB o tamanho do volume lógico "dados"
lvm lvresize -L +512M /dev/vg/dados
# Aumenta o sistema de arquivos contido no volume lógico "dados", para adaptá-lo ao seu novo tamanho
resize2fs /dev/vg/dados
Questões importantes:
- O que é LVM, e qual sua relação com os discos físicos ?
- Para que usar LVM (o que se ganha com seu uso) ?
- Existe algum problema que possa ocorrer com o uso do LVM ? Por exemplo, se um disco apresentar defeito ?
Atividade:
- Com o fdisk crie três novas partições, no início do espaço livre do disco, uma de tamanho de 512 MB, outra de 1GB e a terceira com 1.4 GB. Formate-as com sistema de arquivos ext4.
- Monte estas partições em /dados, /soft e /outra.
- Configure o sistema para que faça a montagem automaticamente, ou seja, em todo reinício da máquina.
- Desfaça os itens 2 e 3, para dar prosseguimento ao exercício.
- Crie um grupo de volume LVM (VG) com nome GerVg, contendo as duas partições criadas no item 1. Esse VG deverá ter tamanho total de 1512 MB.
- Crie 4 volumes lógicos, "dados", "home", "teste", "softwares", respectivamente com 300 , 400, 100 e 500 MB, dentro do VG.
- Formate os volumes lógicos.
- Monte as novas partições em /dados, /usuarios, /nada e /soft.
- Aumente o tamanho de "home" em 500 MB, redimensionando o sistema de arquivos apropriadamente (e sem desmontá-lo).
- Com o fdisk remova completamente as partições criadas, para não deixar o hd “bagunçado”. Remova também todos os diretórios criados.
RAID + LVM
LVM não proporciona proteção dos dados ... pelo contrário. Por combinar volumes físicos para serem usados em volumes lógicos, e pela forma como faz a alocação de espaço (em que os LE dos volumes lógicos podem apresentar um mapeamento arbitrário e fora de sequência aos PE dos volumes físicos), na verdade o LVM amplia a chance de dores de cabeça no evento de um defeito em um disco. Por isto é fundamental que a segurança dos dados seja provida por outra técnica, sendo o mais recomendado RAID.
RAID combina discos ou partições de forma a incrementar o desempenho e/ou segurança dos dados, conforme visto anteriormente. Um volume RAID (ou array RAID), composto de múltiplos discos, se apresenta como se fosse um único disco. Para usá-lo de forma a prover segurança de dados para o LVM, o volume RAID deve ser usado como volume físico do LVM. Além disto, dado o objetivo do uso do RAID, devem-se usar os níveis RAID 1, RAID 5, RAID 6 ou RAID 10 (melhor os dois primeiros). Fazendo isto, os volumes LVM estarão menos vulneráveis a falhas de hardware.
Atividade:
- Usando dois discos físicos com 4 GB cada, combine RAID e LVM para criar um Volume Group que aproveite todo o espaço disponível e esteja protegido contra defeitos em um dos discos.
- Crie dois sistemas de arquivos do tipo EXT4 dentro desse Volume Group:
- Um com 1GB, a ser montado em /dados
- Outro com 2 GB, a ser montado em /usuarios
- Simule um defeito em um dos discos e verifique se esses sistemas de arquivos continuam disponíveis:
- Se o Linux estiver rodando em um computador real, remova a alimentação de um dos discos
- Se estiver rodando com VirtualBox, desligue a máquina virtual, remova um dos discos virtuais, e então a reinicie
25/02: Usuários e grupos
Criação de contas de usuários e de grupos, e seu uso para conferir permissões de acesso a arquivos, diretórios e recursos do sistema operacional. Apostila, páginas 61 a 65.
Um usuário no Linux (e no Unix em geral) é definido pelo seguinte conjunto de informações:
- Nome de usuário (ou login): um apelido que identifica o usuário no sistema
- UID (User Identifier): um número único que identifica o usuário
- GID (Group Identifier): o número do grupo primário do usuário
- Senha (password): senha para verificação de acesso
- Nome completo (full name): nome completo do usuário
- Diretório inicial (homedir): o subddiretório pessoal do usuário, onde ele é colocado ao entrar no sistema
- Shell: o programa a ser executado quando o usuário entrar no sistema
As contas de usuários, que contêm as informações acima, podem ficar armazenadas em diferentes bases de dados (chamadas de bases de dados de usuários). Dentre elas, a mais simples é composta pelo arquivo /etc/passwd:
root:x:0:0:root:/root:/bin/bash
sshd:x:71:65:SSH daemon:/var/lib/sshd:/bin/false
suse-ncc:x:105:107:Novell Customer Center User:/var/lib/YaST2/suse-ncc-fakehome:/bin/bash
wwwrun:x:30:8:WWW daemon apache:/var/lib/wwwrun:/bin/false
dayna:x:1000:100:Dayna M Bortoluzzi:/home/dayna:/bin/bash
man:x:13:62:Manual pages viewer:/var/cache/man:/bin/bash
news:x:9:13:News system:/etc/news:/bin/bash
uucp:x:10:14:Unix-to-Unix CoPy system:/etc/uucp:/bin/bash
sobral:x:1001:100:Marcelo Maia Sobral:/data1/sobral:/bin/bash
Acima um exemplo de arquivo /etc/passwd
Cada linha desse arquivo define uma conta de usuário no seguinte formato:
nome de usuário:senha:UID:GID:Nome completo:Diretório inicial:Shell
O campo senha em /etc/passwd pode assumir os valores:
- x: significa que a senha se encontra em /etc/shadow
- *: significa que a conta está bloqueada
- senha encriptada: a senha de fato, porém encriptada usando algoritmo hash MD5 ou crypt. Porém usualmente a senha fica armazenada no arquivo /etc/shadow.
O arquivo /etc/shadow armazena exclusivamente as informações relativas a senha e validade da conta. Nele cada conta possui as seguintes informações:
- Nome de usuário
- Senha encriptada (sobrepõe a senha que porventura exista em /etc/passwd)
- Data da última modificação da senha
- Dias até que a senha possa ser modificada (validade mínima da senha)
- Dias após que a senha deve ser modificada
- Dias antes da expiração da senha em que o usuário deve ser alertado
- Dias após a expiração da senha em que a conta é desabilitada
- Data em que a conta foi desabilitada
Um exemplo do arquivo /etc/shadow segue abaixo:
root:$2a$05$8IZNUuFTMoA3xv5grggWa.oBUBfvrE4MfgRDTlUI1zWDXGOHi9dzG:13922::::::
suse-ncc:!:13922:0:99999:7:::
uucp:*:13922::::::
wwwrun:*:13922::::::
sobral:$1$meoaWjv3$NUhmMHVdnxjmyyRNlli5M1:14222:0:99999:7:::
Exercício: quando a senha do usuário sobral irá expirar ?
Gerenciamento de usuários e grupos.
Atividade:
- Crie o grupo turma.
- Crie o diretório /home/contas.
- Faça cópia dos arquivos a serem alterados: /etc/login.defs e /etc/default/useradd.
- Faça com que o diretório home dos usuários, a serem criados a partir de agora, seja por padrão dentro de /home/contas.
- Faça com que os usuários sejam criados com o seguinte perfil, por padrão:
- Expiração de senha em 15 dias a partir da criação da conta;
- Usuário possa alterar senha a qualquer momento;
- Data da expiração da conta em 17 dias a partir de hoje.
- Inicie os avisos de expiração da senha 4 dia antes de expirar.
- Iniciar a numeração de usuários (ID) a partir de 1000.
- Crie um usuário com o nome de manoel, pertencente ao grupo turma.
- Dê ao usuário manoel a senha mane123.
- Acrescente ao perfil do usuário seu nome completo e endereço: Manoel da Silva, R. dos Pinheiros, 2476666.
- Verifique o arquivo /etc/passwd.
- Mude, por comandos, o diretório home do manoel de /home/contas/manoel para /home/manoel.
- Mude o login do manoel para manoelsilva.
- Logue como manoelsilva.
- Recomponha os arquivos originais do item 3.
Permissionamento de arquivos e grupos de usuários
- Crie a partir do /home 3 diretórios, um com nome aln (aluno), outro prf (professor) e o último svd (servidor).
- Crie 3 grupos com os mesmos nomes acima.
- Crie 3 contas pertencentes ao grupo aln: aluno1, aluno2, aluno3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/aln/. Por exemplo para o aluno1 teremos /home/aln/aluno1.
- Crie 3 contas pertencentes ao grupo prf: prof1, prof2, prof3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/prf/.
- Crie 3 contas pertencentes ao grupo svd: serv1, serv2, serv3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/svd/.
- Os diretórios dos alunos, e todo o seu conteúdo, devem ser visíveis, mas não apagáveis, aos membros do próprio grupo e de todos os demais usuários da rede.
- Já os diretórios dos professores e servidores, devem ser mutuamente visíveis, mas não apagáveis, entre os membros dos grupos professores e servidores mas não deve ser sequer visível aos membros do grupo alunos.
01/03: Quotas de disco
Quotas de disco, que servem para limitar o uso de espaço pelos usuários. Implantação das quotas.
04/03: Agendamento de tarefas
Agendamento de tarefas administrativas com crontab.
08/03: Backups
Backups com software amanda.
11/03: Shell scripts para automatizar tarefas
15/03: Shell scripts para automatizar tarefas
18/03: Shell scripts para automatizar tarefas
25/03: 1a avaliação
1a avaliação individual