GER-2010-1
Gerência de Redes - semestre 2010-1
Informações gerais
Professor: Marcelo Maia Sobral
Email: msobral@gmail.com
Skype: mm-sobral
Lista de email (forum): ger-ifsc@googlegroups.com
Atendimento paralelo: 2a feira 10h - 11 h, 4a feira 10h - 12 h ou 16h - 17 h, 5a feira 10 - 11h, 6a feira 10 - 12h (no Laboratório de Desenvolvimento de Tele)
Reavaliação (recuperação): no final do semestre
Referências adicionais
- Valle, Odilson Tadeu. Gerência de Redes. IFSC - Unidade São José. 2009.
- Ubuntu Server Guide
- Guia Foca Linux (intermediário ou avançado)
- Demais referências contidas na página principal de GER.
Listas e avaliações simuladas
08/02: Introdução
Apresentação da disciplina e do ambiente de trabalho. Instalação do Ubuntu Linux Server 9.10.
Foi apresentada uma visão geral sobre Gerência de Redes, que trata do projeto, implantação, manutenção e monitoramento de serviços de rede. Na disciplina há uma ênfase em servidores, que são equipamentos (usualmente computadores) que disponibilizam os serviços de rede. Normalmente existem vários servidores em uma rede, os quais operam com algum grau de integração (sejam as contas de usuários e grupos, sistemas de arquivos compartilhados, nomeação de recursos, e outros possíveis serviços). Uma discussão mais aprofundada se encontra na apostila, nos capítulos 1 e 11.
Instalou-se o Ubuntu Server 9.10 na máquina virtual tecnologo-ger2 (VirtualBox). Usou-se um particionamento manual que isola os sistemas de arquivos / (raiz), /usr, /var e /home, além da partição de swap. Enfatizou-se que o uso de apenas um sistema de arquivos, como sugerido pelo instalador do sistema operacional, não é a melhor opção para um servidor. Do contrário, se um sistema de arquivos ficar cheio (por exemplo, devido aos arquivos de usuários), podem-se comprometer os serviços mantidos no servidor, porque é comum que os processos que os implementam precisem criar arquivos temporários para trabalharem. Outros motivos têm relação com a intergidade dos sistemas de arquivos, pois aqueles que sofrem modificações continuamente estão mais sujeitos a ficarem corrompidos em caso de desligamento súbito da máquina, apesar de isto ser mais difícil atualmente com sistemas de arquivos com journaling. Finalmente, em servidores com mais de um volume físico para armazenamento, torna-se necessário ou interessante isolar um sistema de arquivos em um subconjunto desses volumes.
Os tamanhos escolhidos para esses sistemas de arquivos são:
- /: 512 MB
- /usr: 1.5 GB
- /var: 512MB
- swap: 512 MB
- /home: 120 MB aprox. (o que sobrou)
Esse particionamento serviu somente para a instalação inicial, e provavelmente será modificado em breve.
O único serviço de rede instalado foi o Openssh server.
11/02: O processo de boot e instalação de software
O boot
O processo de inicialização do sistema operacional, chamado de boot. Tradicionalmente no Unix System V isto se faz com a definição de níveis de execução (runlevels) e uma tabela que descreve que processos ou serviços devem existir em cada nível. Os níveis de execução são:
- Monousuário (single-user), ou administrativo: usado para manutenção do sistema, admite somente o login do superusuário. Não inicia serviços de rede.
- Multiusuário com rede (parcial): admite logins de usuários, mas não ativa acesso a recursos de rede (como sistemas de arquivo remotos)
- Multiusuário com rede plena
- Não usado
- Multiusuário com rede plena e ambiente gráfico: ativa também o ambiente gráfico X11
- Reinício do sistema (reboot)
As distribuições Linux em geral adotam a inicialização no estilo Unix System V. No entanto, o Ubuntu usa um outro processo chamado de upstart. Esse serviço de inicialização confere maior flexibilidade e mesmo simplicidade à definição de que serviços devem ser executados. O upstart não usa o conceito de níveis de execução, mas devido à sua flexibilidade ele pode emular esse estilo de inicialização. Para o upstart, um serviço deve ser iniciado ou parado dependendo de uma combinação de eventosm, sendo que um evento indica a ocorrência de uma etapa da inicialização.
O upstart é implementado pelo processo init (programa /sbin/init), que é o primeiro processo criado pelo sistema operacional. Quer dizer, logo após terminar a carga e inicialização do kernel, este cria um processo que executa o programa /sbin/init. O upstart lista o subdiretório /etc/init e procura arquivos com extensão .conf. Cada arquivo desses descreve um serviço a ser controlado pelo upstart. Por exemplo, o serviço tty2 é escrito no arquivo tty2.conf:
# tty2 - getty
#
# This service maintains a getty on tty2 from the point the system is
# started until it is shut down again.
start on runlevel [23]
start on runlevel [!23]
respawn
exec /sbin/getty -8 38400 tty2
Abaixo segue o significado de cada linha:
- start on runlevel [23]: o serviço deve ser iniciado quando ocorrerem os eventos "runlevel 2" ou "runlevel 3"
- stop on runlevel [!23]: o serviço deve ser parado quando ocorrer qualquer evento "runlevel X", sendo X diferente de 2 e 3
- respawn: o serviço deve ser reiniciado automaticamente caso termine de forma anormal
- exec /sbin/getty -8 38400 tty2: a ativação do serviço implica executar o /sbin/getty -8 38400 tty2
Em linhas gerais, a descrição do serviço informa quando ele deve ser ativado (start), quando deve ser parado (stop), o tipo de execução (respawn para reinício automático, ou task para uma única execução), e que ação deve ser executada para ativar o serviço (exec para executar um programa, ou script .. end script para executar uma sequência de comandos de shell). Maiores detalhes podem ser lidos na página de manual do init.
Um exemplo de criação de serviço no upstart
Foi proposta a criação de um serviço chamado faxineiro, para remover dos diretórios temporários (/tmp e /var/tmp) todos os arquivos que não tenham sido modificados há mais de um dia. Esse novo serviço deve ser executado no boot, logo após o serviço mountall. A solução encontrada foi a seguinte:
- Criar o arquivo /etc/init/faxineiro.conf
- Adicionar o seguinte conteúdo a esse arquivo:
start on filesystem task console output script find /tmp -type f -mtime +1 -exec rm -f {} \; -print find /var/tmp -type f -mtime +1 -exec rm -f {} \; -print echo Faxineiro executado \!\!\! end script - Reiniciar o sistema para testá-lo (executar reboot)
Instalação de software
A instalação de software pode ser feita de diversas formas, dentre as quais serão destacadas três:
- Com utilitário apt-get: busca o software de um repositório de rede e o instala; dependências (outros softwares necessários) são automaticamente instaladas. Esses softwares buscados da rede estão no formato dpkg (Debian Package). Exemplo de uso do apt-get:
# Instala o navegador de texto lynx apt-get install lynx # Testa o navegador lynx lynx http://www.ifsc.edu.br/ # Remove o lynx apt-get --auto-remove remove lynx
- Diretamente com utilitário dpkg: instala um software que está contido em um arquivo no formato dpkg. Exemplo de uso:
# Obtém os pacotes Debian para o lynx wget http://www.sj.ifsc.edu.br/~msobral/ger/lynx_2.8.7pre6-1_all.deb wget http://www.sj.ifsc.edu.br/~msobral/ger/lynx-cur_2.8.7pre6-1_i386.deb # Instala os pacotes dpkg -i lynx-cur_2.8.7pre6-1_i386.deb lynx_2.8.7pre6-1_all.deb # Testa o lynx lynx # Remove os pacotes instalados dpkg -r lynx lynx-cur
- A partir do código fonte: busca-se manualmente na rede o código fonte do software desejado, que deve então ser compilado e instalado. Esta opção se aplica quando não existe o software no formato dpkg, ou a versão disponível em formato dpkg foi compilada de uma forma que não atende os requisitos para seu uso em seu servidor.
18/02: RAID
RAID (Redundant Array of Independent Disks) se destina a combinar discos de forma a incrementar o desempenho de entrada e saída e, principalmente, segurança dos dados contra defeitos em discos. RAID pode ser provido via software ou hardware (melhor este último). O Linux possui implementação por software em seu kernel, e neste HOWTO há uma descrição resumida.
Há vários níveis RAID, que correspondem a diferentes combinações de discos e partições. São eles:
- LINEAR: concatena discos ou partições, mas não provê acréscimos de desempenho, nem de segurança dos dados (pelo contrário ! se um disco falhar, perdem-se todos os dados ...).
- RAID 0 (ou striping): combina discos ou partições de forma alternada, para distribuir os acessos entre eles (aumentar desempenho). Porém, se um disco falhar perdem-se todos os dados. Requer um mínimo de dois discos.
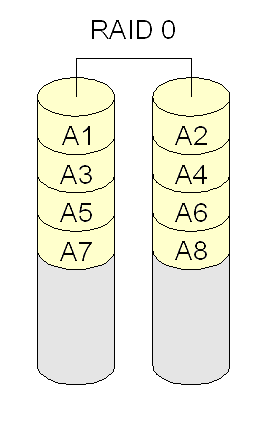
- RAID 1 (ou mirroring): combina discos ou partições para espelhar dados (segurança). Requer o dobro de discos necessários para guardar os dados (ex: se há dois discos com dados, são necessários outros dois para espelhamento). Se todos os discos falharem, é possível continuar a operar usando os discos espelhados. Requer no mínimo dois discos.
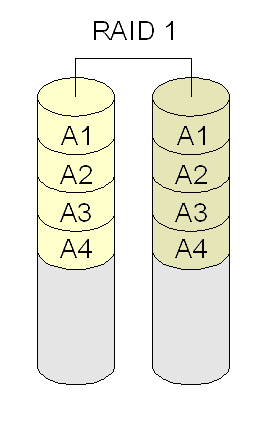
- RAID 4 e 5: combina discos ou partições para ter redundância de dados (segurança), usando um esquema baseado em paridade. Se um disco falhar, é capaz de continuar operando (porém com desempenho reduzido até que esse disco seja reposto). RAID 4 na prática não se usa, pois apresenta um gargalo no disco onde residem os blocos de paridades. Requer no mínimo três discos.
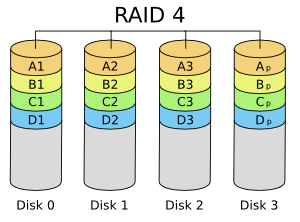
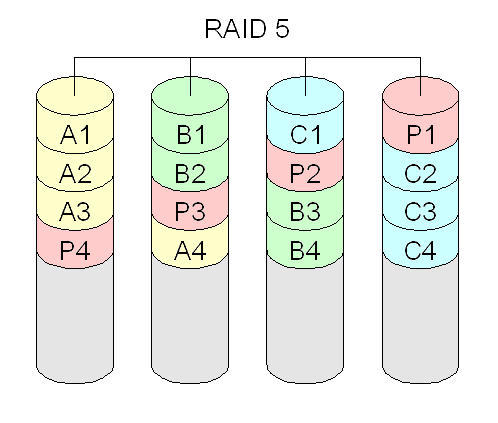
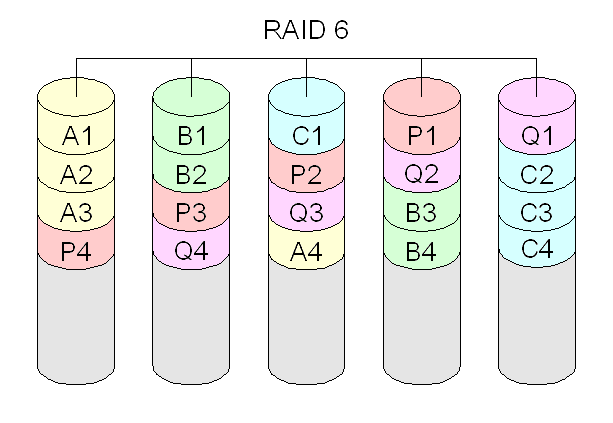
- RAID 6: combina discos ou partições para ter redundância de dados (segurança), usando um esquema baseado em paridade de forma duplicada. Isto garante que os dados se preservam mesmo que dois discos se danifiquem. Requer no mínimo quatro discos (pois há dois discos adicionais para paridades).
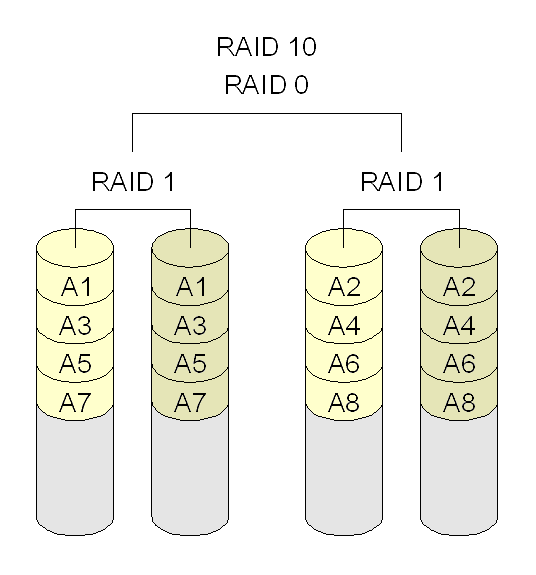
- RAID 10: combina RAID 1 e RAID 0, criando um volume com espelhamento (RAID 1), e depois fazendo o striping (RAID 0). Requer no mínimo quatro discos.
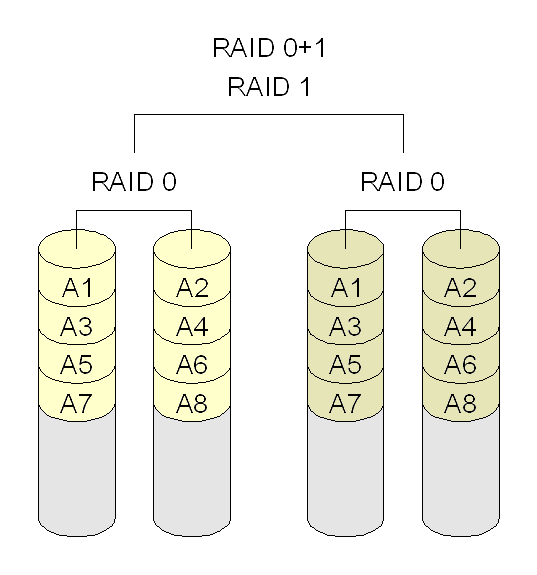
- RAID 01: combina RAID 0 e RAID 1, criando um volume com striping (RAID 0), e depois fazendo o espelhamento (RAID 1). Requer no mínimo quatro discos.







Criação de um volume RAID no Linux:
- Usar o comando mdadm --create --verbose /dev/md0 --level=NIVEL_RAID --raid-devices=NUM_PARTICOES PARTICAO_1 PARTICAO_2 ...
- NIVEL_RAID pode ser linear, 0, 1, 4, 5, 6, 10, mp, faulty (mais comuns são 0, 1 e 5).
- NUM_PARTICOES é a quantidade de partições usadas no volume.
- As partições são identificadas com o caminho (pathname) do dispositivo correspondente no Linux. Ex: a primeira partição do primeiro disco SCSI ou SATA é /dev/sda1, a segunda partição desse disco é /dev/sda2, a primeira partição do segundo disco SCSI ou SATA é /dev/sdb1, e assim por diante.
- /dev/md0 é o caminho do dispositivo que corresponde ao volume RAID a ser criado. O primeiro volume RAID é /dev/md0, o segundo é /dev/md1, e assim por diante.
- Formatar o volume RAID: mkfs.ext4 -j /dev/md0
- Uma vez testado o volume RAID, sua configuração pode ser salva para posterior uso: mdadm --detail --scan >> /etc/mdadm/mdadm.conf
- Isto é importante para que o volume possa ser ativado automaticamente no próximo boot.
Para ativar um volume já criado, basta executar mdadm --assemble caminho_do_volume. Ex: mdadm --assemble /dev/md0, mdadm --assemble /dev/md1.
Atividade:
- Crie duas partições de mesmo tamanho no disco /dev/sdb. Marque-as como sendo do tipo Linux RAID
- Crie um volume RAID nível 1 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
- Pare o volume existente, com mdadm -S /dev/md0
- Crie um volume RAID nível 0 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
- Pare o volume existente, com mdadm -S /dev/md0
- Crie um volume RAID nível 5 com essas partições. Formate-o e monte-o em /mnt. Qual o tamanho total dele ?
- Pare o volume existente, com mdadm -S /dev/md0
22/02: LVM
Armazenamento com Gerenciador de Volumes Lógicos (LVM). Ver páginas 57 e 58 da apostila.
Há um HOWTO com informação adicional sobre LVM no Linux, e outro com uma definição mais geral na Wikipedia.
LVM combina volumes físicos (ou PV, de Physical Volume), tais como discos, partições e volumes RAID, em uma abstração chamada grupo de volumes (ou VG, de Volume Group). Um VG funciona como um grande disco virtual, que pode ser dividido em volumes lógicos (LV, de Logical Volume). Cada LV pode ser usado para conter um sistema de arquivos, memória virtual (área de swap), ou qualquer outra finalidade de armazenamento (ex: área de dados de um banco de dados Oracle). A figura abaixo mostra a relação entre esses componentes, com exemplos de utilização dos LV:

Diagrama do LVM (obtido no Linux DevCenter)
Um resumo dos componentes do LVM segue abaixo:
- VG: Volume Group, que representa um disco lógico
- PE: Physical Extent, ou uma subdivisão do PV (são todas de mesmo tamanho), que funciona como unidade de alocação de espaço
- LE: Logical Extent, o equivalente ao PE, porém no contexto do LV
- PV: Physical Volume, ou uma partição física
- LV: Logical Volume, ou uma partição lógica criada dentro do VG
Em sua estrutura interna, o LVM divide cada PV em pequenas partições chamadas de PE (Physical Extent). Um tamanho típico para as PE é de 4 MB. Essas PE são usadas para alocar espaço para os LV, porém não há nenhuma relação entre a ordem física das PE nos PV e a ordem em que elas são alocadas aos LV - é normal inclusive PE de diferentes PV serem alocadas ao mesmo LV. Dentro de cada LV cada PE é chamada de LE (Logical Extent). A figura abaixo relaciona as PE com as LE dos LV:

Diagrama para LVM versão 1 (LVM1) no Linux.
Criação do LVM no Linux
A sequência de criação de um VG e seus LV é a seguinte:
- Criar partições físicas do tipo 8E (Linux LVM), que serão usadas para serem os PV
- Preparar essas partições para serem usadas como PV, usando o comando lvm pvcreate caminho_partição (ex: lvm pvcreate /dev/sdb1)
- Criar o VG, usando o comando lvm vgcreate nome_vg pv1 [pv2 ...] (ex: lvm vgcreate meu_vg /dev/sdb1 /dev/sdb2)
- Criar os LV, com o comando lvm lvcreate nome_vg -L tamanho_LV -n nome_LV (ex: lvm lvcreate meu_vg -L 512M -n teste)
- Formatar os LV (ex: mke4fs -j /dev/meu_vg/teste, para formatar com sistema de arquivos ext4)
Abaixo segue um exemplo de uma sequência de comandos relacionados com LVM, desde o particionamento de um disco até o redimensionamento de um LV existente:
# Prepara as partições (devem ser do tipo 8E (Linux LVM)
fdisk /dev/sdb
# Prepara essas duas partições para serem usadas como volumes físicos
lvm pvcreate /dev/sdb1
lvm pvcreate /dev/sdb2
# Cria o volume group "vg"
lvm vgcreate vg /dev/sdb1 /dev/sdb2
# Cria dentro do volume group "vg" um volume lógico "dados" com 512 MB iniciais
lvm lvcreate vg -L 512M -n dados
# Cria dentro do volume group "vg" um volume lógico "teste" com 256 MB iniciais
lvm lvcreate vg -L 256M -n teste
# Mostra informações sobre todos os volumes lógicos
lvm lvs
# Mostra detalhes sobre o volume lógico "dados", que pertence ao volume group "vg"
lvm lvdisplay /dev/vg/dados
# Formata o volume lógico "dados" com sistema de arquivos do tipo "ext4"
mkfs.ext4 -j /dev/vg/dados
# Formata o volume lógico "teste" com sistema de arquivos do tipo "xfs"
mkfs.xfs /dev/vg/dados
# Aumenta em 512 MB o tamanho do volume lógico "dados"
lvm lvresize -L +512M /dev/vg/dados
# Aumenta o sistema de arquivos contido no volume lógico "dados", para adaptá-lo ao seu novo tamanho
resize2fs /dev/vg/dados
Questões importantes:
- O que é LVM, e qual sua relação com os discos físicos ?
- Para que usar LVM (o que se ganha com seu uso) ?
- Existe algum problema que possa ocorrer com o uso do LVM ? Por exemplo, se um disco apresentar defeito ?
Atividade:
- Com o fdisk crie três novas partições, no início do espaço livre do disco, uma de tamanho de 512 MB, outra de 1GB e a terceira com 1.4 GB. Formate-as com sistema de arquivos ext4.
- Monte estas partições em /dados, /soft e /outra.
- Configure o sistema para que faça a montagem automaticamente, ou seja, em todo reinício da máquina.
- Desfaça os itens 2 e 3, para dar prosseguimento ao exercício.
- Crie um grupo de volume LVM (VG) com nome GerVg, contendo as duas partições criadas no item 1. Esse VG deverá ter tamanho total de 1512 MB.
- Crie 4 volumes lógicos, "dados", "home", "teste", "softwares", respectivamente com 300 , 400, 100 e 500 MB, dentro do VG.
- Formate os volumes lógicos.
- Monte as novas partições em /dados, /usuarios, /nada e /soft.
- Aumente o tamanho de "home" em 500 MB, redimensionando o sistema de arquivos apropriadamente (e sem desmontá-lo).
- Com o fdisk remova completamente as partições criadas, para não deixar o hd “bagunçado”. Remova também todos os diretórios criados.
RAID + LVM
LVM não proporciona proteção dos dados ... pelo contrário. Por combinar volumes físicos para serem usados em volumes lógicos, e pela forma como faz a alocação de espaço (em que os LE dos volumes lógicos podem apresentar um mapeamento arbitrário e fora de sequência aos PE dos volumes físicos), na verdade o LVM amplia a chance de dores de cabeça no evento de um defeito em um disco. Por isto é fundamental que a segurança dos dados seja provida por outra técnica, sendo o mais recomendado RAID.
RAID combina discos ou partições de forma a incrementar o desempenho e/ou segurança dos dados, conforme visto anteriormente. Um volume RAID (ou array RAID), composto de múltiplos discos, se apresenta como se fosse um único disco. Para usá-lo de forma a prover segurança de dados para o LVM, o volume RAID deve ser usado como volume físico do LVM. Além disto, dado o objetivo do uso do RAID, devem-se usar os níveis RAID 1, RAID 5, RAID 6 ou RAID 10 (melhor os dois primeiros). Fazendo isto, os volumes LVM estarão menos vulneráveis a falhas de hardware.
Atividade:
- Usando dois discos físicos com 4 GB cada, combine RAID e LVM para criar um Volume Group que aproveite todo o espaço disponível e esteja protegido contra defeitos em um dos discos.
- Crie dois sistemas de arquivos do tipo EXT4 dentro desse Volume Group:
- Um com 1GB, a ser montado em /dados
- Outro com 2 GB, a ser montado em /usuarios
- Simule um defeito em um dos discos e verifique se esses sistemas de arquivos continuam disponíveis:
- Se o Linux estiver rodando em um computador real, remova a alimentação de um dos discos
- Se estiver rodando com VirtualBox, desligue a máquina virtual, remova um dos discos virtuais, e então a reinicie
25/02: Usuários e grupos
Criação de contas de usuários e de grupos, e seu uso para conferir permissões de acesso a arquivos, diretórios e recursos do sistema operacional. Apostila, páginas 61 a 65.
Um usuário no Linux (e no Unix em geral) é definido pelo seguinte conjunto de informações:
- Nome de usuário (ou login): um apelido que identifica o usuário no sistema
- UID (User Identifier): um número único que identifica o usuário
- GID (Group Identifier): o número do grupo primário do usuário
- Senha (password): senha para verificação de acesso
- Nome completo (full name): nome completo do usuário
- Diretório inicial (homedir): o subddiretório pessoal do usuário, onde ele é colocado ao entrar no sistema
- Shell: o programa a ser executado quando o usuário entrar no sistema
As contas de usuários, que contêm as informações acima, podem ficar armazenadas em diferentes bases de dados (chamadas de bases de dados de usuários). Dentre elas, a mais simples é composta pelo arquivo /etc/passwd:
root:x:0:0:root:/root:/bin/bash
sshd:x:71:65:SSH daemon:/var/lib/sshd:/bin/false
suse-ncc:x:105:107:Novell Customer Center User:/var/lib/YaST2/suse-ncc-fakehome:/bin/bash
wwwrun:x:30:8:WWW daemon apache:/var/lib/wwwrun:/bin/false
dayna:x:1000:100:Dayna M Bortoluzzi:/home/dayna:/bin/bash
man:x:13:62:Manual pages viewer:/var/cache/man:/bin/bash
news:x:9:13:News system:/etc/news:/bin/bash
uucp:x:10:14:Unix-to-Unix CoPy system:/etc/uucp:/bin/bash
sobral:x:1001:100:Marcelo Maia Sobral:/data1/sobral:/bin/bash
Acima um exemplo de arquivo /etc/passwd
Cada linha desse arquivo define uma conta de usuário no seguinte formato:
nome de usuário:senha:UID:GID:Nome completo:Diretório inicial:Shell
O campo senha em /etc/passwd pode assumir os valores:
- x: significa que a senha se encontra em /etc/shadow
- *: significa que a conta está bloqueada
- senha encriptada: a senha de fato, porém encriptada usando algoritmo hash MD5 ou crypt. Porém usualmente a senha fica armazenada no arquivo /etc/shadow.
O arquivo /etc/shadow armazena exclusivamente as informações relativas a senha e validade da conta. Nele cada conta possui as seguintes informações:
- Nome de usuário
- Senha encriptada (sobrepõe a senha que porventura exista em /etc/passwd)
- Data da última modificação da senha
- Dias até que a senha possa ser modificada (validade mínima da senha)
- Dias após que a senha deve ser modificada
- Dias antes da expiração da senha em que o usuário deve ser alertado
- Dias após a expiração da senha em que a conta é desabilitada
- Data em que a conta foi desabilitada
Um exemplo do arquivo /etc/shadow segue abaixo:
root:$2a$05$8IZNUuFTMoA3xv5grggWa.oBUBfvrE4MfgRDTlUI1zWDXGOHi9dzG:13922::::::
suse-ncc:!:13922:0:99999:7:::
uucp:*:13922::::::
wwwrun:*:13922::::::
sobral:$1$meoaWjv3$NUhmMHVdnxjmyyRNlli5M1:14222:0:99999:7:::
Exercício: quando a senha do usuário sobral irá expirar ?
Um grupo é um conjunto de usuários definido da seguinte forma:
- Nome de group (group name): o nome que identifica o grupo no sistema
- GID (Group Identifier): um número único que identifica o grupo
- Lista de usuários: um conjunto de usuários que são membros do grupo
Assim como as contas de usuários, os grupos ficam armazenados em bases de dados de usuários, sendo o arquivo /etc/group a mais simples delas:
root:x:0:
wheel:x:10:dayna
trusted:x:42:
tty:x:5:
utmp:x:22:
uucp:x:14:
video:x:33:sobral
wheel:x:10:dayna
www:x:8:sobral
users:x:100:
radiusd:!:108:
vboxusers:!:1000:
Os membros de um grupo são os usuários que o têm como grupo primário (especificado na conta do usuário em /etc/passwd), ou que aparecem listados em /etc/group.
Gerenciamento de usuários e grupos
Para gerenciar usuários e grupos podem-se editar diretamente os arquivos /etc/passwd, /etc/shadow e /etc/group, porém existem utilitários que facilitam essa tarefa:
- useradd: adiciona um usuário
- Ex: useradd -c "Marcelo M. Sobral" -m sobral : cria o usuário sobral com nome completo "Marcelo M. Sobral"
- Ex: useradd -c "Marcelo M. Sobral" -g users -u 5000 -d /usuarios/sobral -s /bin/tcsh -m sobral : cria o usuário sobral com nome completo "Marcelo M. Sobral", UID 5000, grupo users, diretório inicial /usuarios/sobral e shell /bin/tcsh
- userdel: remove um usuário
- Ex: userdel sobral : remove o usuário sobral, porém preservando seu diretório home
- Ex: userdel -r sobral : remove o usuário sobral, incluindo seu diretório home
- usermod: modifica as informações da conta de um usuário
- Ex: usermod -u 5001 sobral : modifica o UID do usuário sobral
- Ex: usermod -g wheel sobral : modifica o GID do usuário sobral
- Ex: usermod -G users,wheel sobral : modifica os grupos secundários do usuário sobral
- Ex: usermod -d /contas/sobral sobral : modifica o diretório inicial do usuário sobral (mas não copia os arquivos ...)
- groupadd: adiciona um grupo
- Ex: groupadd -g 4444 ger: cria o grupo ger com GID 4444
- groupdel: remove um grupo
- Ex: groupdel ger: remove o grupo ger
- groupmod: modifica um grupo
- Ex: groupmod -g 5555 ger: modifica o GID do grupo ger
- Ex: groupmod -A sobral ger: adiciona o usuário sobral ao grupo ger
- Ex: groupmod -R sobral ger: remove o usuário sobral do grupo ger
Esses utilitários usam os arquivos /etc/login.defs e /etc/default/useradd para obter seus parâmetros default. O arquivo /etc/login.defs contém uma série de diretivas e padrões que serão utilizados na criação das próximas contas de usuários. Seu principal conteúdo é:
MAIL_DIR dir # Diretório de e-mail
PASS_MAX_DAYS 99999 #Número de dias até que a senha expire
PASS_MIN_DAYS 0 #Número mínimo de dias entre duas trocas senha
PASS_MIN_LEN 5 #Número mínimo de caracteres para composição da senha
PASS_WARN_AGE 7 #Número de dias para notificação da expiração da senha
UID_MIN 500 #Número mínimo para UID
UID_MAX 60000 #Número máximo para UID
GID_MIN 500 #Número mínimo para GID
GID_MAX 60000 #Número máximo para GID
CREATE_HOME yes #Criar ou não o diretório home
Como o login.defs o arquivo /etc/default/useradd contém padrões para criação de contas. Seu principal conteúdo é:
GROUP=100 #GID primário para os usuários criados
HOME=/home #Diretório a partir do qual serão criados os “homes”
INACTIVE=-1 #Quantos dias após a expiração da senha a conta é desativada
EXPIRE=AAAA/MM/DD #Dia da expiração da conta
SHEL=/bin/bash #Shell atribuído ao usuário.
SKEL=/etc/skel #Arquivos e diretórios padrão para os novos usuários.
O arquivo /etc/default/useradd contém alguns valores default de uso exclusivo do utilitário useradd:
GROUP=100
HOME=/home
INACTIVE=-1
EXPIRE=
SHELL=/bin/bash
SKEL=/etc/skel
GROUPS=video,dialout
CREATE_MAIL_SPOOL=no
Permissões
Há uma maneira de restringir o acesso aos arquivos e diretórios para que somente determinados usuários possam acessá-los. A cada arquivo e diretório é associado um conjunto de permissões. Essas permissões determinam quais usuários podem ler, e escrever (alterar) um arquivo e, no caso de ser um arquivo executável, quais usuários podem executá-lo. Se um usuário tem permissão de execução para um diretório, significa que ele pode realizar buscas dentro daquele diretório, e não executá-lo como se fosse um programa.
Quando um usuário cria um arquivo ou um diretório, o LINUX determina que ele é o proprietário (owner) daquele arquivo ou diretório. O esquema de permissões do LINUX permite que o proprietário determine quem tem acesso e em que modalidade eles poderão acessar os arquivos e diretórios que ele criou. O super-usuário (root), entretanto, tem acesso a qualquer arquivo ou diretório do sistema de arquivos.
O conjunto de permissões é dividido em três classes: proprietário, grupo e usuários. Um grupo pode conter pessoas do mesmo departamento ou quem está trabalhando junto em um projeto. Os usuários que pertencem ao mesmo grupo recebem o mesmo número do grupo (também chamado de Group Id ou GID). Este número é armazenado no arquivo /etc/passwd junto com outras informações de identificação sobre cada usuário. O arquivo /etc/group contém informações de controle sobre todos os grupos do sistema. Assim, pode -se dar permissões de acesso diferentes para cada uma destas três classes.
Quando se executa ls -l em um diretório qualquer, os arquivos são exibidos de maneira semelhante a seguinte:
> ls -l
total 403196
drwxr-xr-x 4 odilson admin 4096 Abr 2 14:48 BrOffice_2.1_Intalacao_Windows/
-rw-r--r-- 1 luizp admin 113811828 Out 31 21:28 broffice.org.2.0.4.rpm.tar.bz2
-rw-r--r-- 1 root root 117324614 Dez 27 14:47 broffice.org.2.1.0.rpm.tar.bz2
-rw-r--r-- 1 luizp admin 90390186 Out 31 22:04 BrOo_2.0.4_Win32Intel_install_pt-BR.exe
-rw-r--r-- 1 root root 91327615 Jan 5 21:27 BrOo_2.1.0_070105_Win32Intel_install_pt-BR.exe
>
As colunas que aparecem na listagem são:
- Esquema de permissões;
- Número de ligações do arquivo;
- Nome do usuário dono do arquivo;
- Nome do grupo associado ao arquivo;
- Tamanho do arquivo, em bytes;
- Mês da criação do arquivo; Dia da criação do arquivo;
- Hora da criação do arquivo;
- Nome do arquivo;
O esquema de permissões está dividido em 10 colunas, que indicam se o arquivo é um diretório ou não (coluna 1), e o modo de acesso permitido para o proprietário (colunas 2, 3 e 4), para o grupo (colunas 5, 6 e 7) e para os demais usuários (colunas 8, 9 e 10).
Existem três modos distintos de permissão de acesso: leitura (read), escrita (write) e execução (execute). A cada classe de usuários você pode atribuir um conjunto diferente de permissões de acesso. Por exemplo, atribuir permissão de acesso irrestrito (de leitura, escrita e execução) para você mesmo, apenas de leitura para seus colegas, que estão no mesmo grupo que você, e nenhum acesso aos demais usuários. A permissão de execução somente se aplica a arquivos que podem ser executados, obviamente, como programas já compilados ou script shell. Os valores válidos para cada uma das colunas são os seguintes:
- 1 d se o arquivo for um diretório;-se for um arquivo comum;
- 2,5,8 r se existe permissão de leitura;-caso contrário;
- 3,6,9 w se existe permissão de alteração;-caso contrário;
- 4,7,10 x se existe permissão de execução;-caso contrário;
A permissão de acesso a um diretório tem outras considerações. As permissões de um diretório podem afetar a disposição final das permissões de um arquivo. Por exemplo, se o diretório dá permissão de gravação a todos os usuários, os arquivos dentro do diretório podem ser removidos, mesmo que esses arquivos não tenham permissão de leitura, gravação ou execução para o usuário. Quando a permissão de execução é definida para um diretório, ela permite que se pesquise ou liste o conteúdo do diretório.
A modificação das permissões de acesso a arquivos e diretórios pode ser feita usando-se os utilitários:
- chmod: muda as permissões de acesso (também chamado de modo de acesso). Somente pode ser executado pelo dono do arquivo ou pelo superusuário
- Ex: chmod +x /home/usuario/programa : adiciona para todos os usuários a permissão de execução ao arquivo /home/usuario/programa
- Ex: chmod -w /home/usuario/programa : remove para todos os usuários a permissão de escrita do arquivo /home/usuario/programa
- Ex: chmod o-rwx /home/usuario/programa : remove todas as permissões de acesso ao arquivo /home/usuario/programa para todos os usuários que não o proprietário e membros do grupo proprietário
- Ex: chmod 755 /home/usuario/programa : define as permissões rwxr-xr-x para o arquivo /home/usuario/programa
- chown: muda o proprietário de um arquivo. Somente pode ser executado pelo superusuário.
- Ex: chown sobral /home/usuario/programa: faz com que o usuário sobral seja o dono do arquivo
- chgrp: muda o grupo dono de um arquivo. Somente pode ser executado pelo superusuário.
- Ex: chgrp users /home/usuario/programa: faz com que o grupo users seja o grupo dono do arquivo /home/usuario/programa
Há também o utilitário umask, que define as permissões default para os novos arquivos e diretórios que um usuário criar. Esse utilitário define uma máscara (em octal) usada para indicar que permissões devem ser removidas. Exemplos:
- umask 022: tira a permissão de escrita para group e demais usuários
- umask 027: tira a permissão de escrita para group, e todas as permissões para demais usuários
Atividade
- Crie o grupo turma.
- Crie o diretório /home/contas.
- Faça cópia dos arquivos a serem alterados: /etc/login.defs e /etc/default/useradd.
- Faça com que o diretório home dos usuários, a serem criados a partir de agora, seja por padrão dentro de /home/contas.
- Faça com que os usuários sejam criados com o seguinte perfil, por padrão:
- Expiração de senha em 15 dias a partir da criação da conta;
- Usuário possa alterar senha a qualquer momento;
- Data do bloqueio da conta em 7 dias após a expiração da senha.
- Inicie os avisos de expiração da senha 4 dia antes de expirar.
- Iniciar a numeração de usuários (ID) a partir de 1000.
- Crie um usuário com o nome de manoel, pertencente ao grupo turma.
- Dê ao usuário manoel a senha mane123.
- Acrescente ao perfil do usuário seu nome completo e endereço: Manoel da Silva, R. dos Pinheiros, 2476666.
- Verifique o arquivo /etc/passwd.
- Mude, por comandos, o diretório home do manoel de /home/contas/manoel para /home/manoel.
- Mude o login do manoel para manoelsilva.
- Logue como manoelsilva.
- Recomponha os arquivos originais do item 3.
Permissionamento de arquivos e grupos de usuários
- Crie a partir do /home 3 diretórios, um com nome aln (aluno), outro prf (professor) e o último svd (servidor).
- Crie 3 grupos com os mesmos nomes acima.
- Crie 3 contas pertencentes ao grupo aln: aluno1, aluno2, aluno3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/aln/. Por exemplo para o aluno1 teremos /home/aln/aluno1.
- Crie 3 contas pertencentes ao grupo prf: prof1, prof2, prof3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/prf/.
- Crie 3 contas pertencentes ao grupo svd: serv1, serv2, serv3. Estas contas deverão ter seus diretórios homes criados por comando dentro do diretório /home/svd/.
- Os diretórios dos alunos, e todo o seu conteúdo, devem ser visíveis, mas não apagáveis, aos membros do próprio grupo e de todos os demais usuários da rede.
- Já os diretórios dos professores e servidores, devem ser mutuamente visíveis, mas não apagáveis, entre os membros dos grupos professores e servidores mas não deve ser sequer visível aos membros do grupo alunos.
01/03: Quotas de disco
No início da aula finalizaram-se os exercícios sobre RAID e LVM.
Quotas de disco servem para limitar o uso de espaço pelos usuários. Ver também apostila de Gerência de Redes, páginas 65 a 69.
Em servidores não se pode correr o risco de poucos usuários utilizarem tanto espaço de disco que impeça outros usuários de trabalharem. Quer dizer, deve-se implantar algum mecanismo que limite o espaço a ser usado por cada usuário, para evitar que o espaço livre no volume se esgote. Quotas de disco é um mecanismo simples para impor tal limitação, estando disponível em todos os sistemas operacionais usados em servidores.
Os sistemas operacionais Linux oferecem um mecanismo simples para impor quotas. Para cada sistema de arquivos é possível ativar ou não o uso de quotas, e fazer um controle de quota por usuário ou grupo. Os sistemas de arquivos de uso mais difundido, tais como EXT3FS, EXT4FS, XFS, ReiserFS e JFS, suportam o uso de quotas (o que não é o caso de VFAT, usado majoritariamente em pendrives atualmente, por exemplo). O sistema operacional controla diretamente o uso do espaço, evitando que o limite estabelecido seja ultrapassado. Desta forma, se um arquivo estiver sendo gravado e o limite de espaço for atingido, a operação de escrita é abortada com um erro de quota excedida (como resultado, o arquivo ficaria truncado). Mas como essa forma de impor um limite pode ser muito estrita, o sistema de quotas define na verdade dois limites:
- soft limit: pode ser ultrapassado, no entanto gera um alerta para o usuário. No entanto, se o espaço total usado pelo usuário ficar acima desse limite continuamente por um número predefinido de dias, esse limite se torna estrito (quer dizer, se torna um hard limit).
- hard limit: não pode ser ultrapassado, gerando um erro de escrita.
Abaixo pode-se ver um exemplo do uso de disco pelo usuário msobral, em um sistema de arquivos com quotas ativadas. Nesse caso, msobral está usando em torno de 30 MB dentro do sistema de arquivos contido no dispositivo /dev/sdb2, e que está montado em /usuarios. O uso total atual está na coluna blocos (1 kB cada), soft limit aparece na coluna quota e o hard limit está em limite:
msobral@ger:~$ quota -v msobral
Sistema de arquivos blocos quota limite grace arquivos quota limite grace
/dev/sdb2 30724 100000 150000 2 0 0
msobral@ger:~$ ls -l /usuarios/msobral/teste
total 30720
-rw-r--r-- 1 msobral msobral 62914560 2010-02-28 19:32 teste
Além disto, note-se que há outras colunas reportadas acima, tais como grace e arquivos. A coluna grace informa quantos dias o usuário ainda tem de prazo, caso esteja acima do soft limit, antes que ele se torne um hard limit (normalmente iniciando com 7 dias). Além disso, é possível limitar também a quantidade de arquivos por ele mantidos. A coluna arquivos informa quantos arquivos e diretórios um usuário possui, e as colunas que a sucedem informam seus limites.
A decisão de que limites devem ser impostos aos usuários é de grande importância, pois devem-se conciliar as necessidades desses usuários e a quantidade de espaço em disco disponível para eles. Uma política para uso de espaço seria dividir a capacidade total do volume pela quantidade de usuários. Porém sabe-se que usuários têm diferentes práticas de uso dos recursos de rede, incluindo as áreas de armazenamento de arquivos. Muitos usuários fazem pouco uso do espaço disponível, enquanto outros realmente aproveitam tudo que lhes for alocado. Assim, uma outra política seria definir um limite individual maior, mesmo que a soma dos limites de usuários exceda a capacidade total do volume. Não é incomum que a soma das quotas individuais seja o dobro ou mais do espaço total existente. Cabe ao administrador o bom senso e, principalmente, o conhecimento sobre o padrão de uso de seus usuários, para melhor definir as quotas e assim o aproveitamento dos discos dos servidores.
Por fim, quotas não implicam nenhuma reserva de espaço em disco para os usuários.
Implantação de quotas
Vários passos são necessários para implantar quotas em um sistema de arquivos. Em primeiro lugar, deve-se certificar de que os utilitários necessários para sua configuração estejam instalados:
apt-get install quota
# mostra a man page do utilitário quota
man quota
Cada sistema de arquivos onde se desejam ativar quotas deve ser montado com a opção quota. Assim, a linha do arquivo /etc/fstab correspondente a um sistema de arquivos desses deve ser similar a:
/dev/sdb2 /usuarios ext4 defaults,quota 0 1
Ao montar o sistema de arquivos pela primeira vez, devem-se tanto atualizar manualmente as informações permanentes sobre quotas (mantidas em um arquivo aquota.user, que fica na raiz do sistema de arquivos), quanto ativar manualmente as quotas:
# Monta o sistema de arquivos /usuarios (só funciona assim por que ele está descrito em /etc/fstab)
mount /usuarios
# Atualiza as informações sobre quotas: isto varre todo o sistema de arquivos para contabilizar quanto espaço cada usuário possui, e grava
# o resultado no arquivo aquota.user
quotacheck -f /usuarios
# Ativa as quotas no sistema de arquivos
quotaon -v /usuarios
# Gera uma listagem das quotas dos usuarios
repquota /usuarios
Uma vez estando o sistema de arquivos definido com a opção quota, as quotas serão ativadas automaticamente no boot do sistema. O procedimento acima é necessário somente na implantação das quotas.
Uma vez estando as quotas ativadas, podem-se editar as quotas de usuaŕios com o utilitário edquota.
edquota sobral
Esse utilitário executa um editor de texto comum para editar as quotas, e então grava o resultado no arquivo aquota.user. O editor de texto executado é aquele indicado na variável de ambiente EDITOR (ex: nano, vim, ...). Abaixo pode-se ver o editor vi sendo chamado para editar as quotas:

Uma prática comum para automatizar a edição de quotas (e fazê-la de forma não-interativa) é definir alguns usuários que servem como perfis (ex: aluno, professor, funcionario), e definir as quotas para cada um deles. Assim , cada novo usuário que for criado pode ter suas quotas copiadas a partir de um desses perfis, usando-se edquota -p:
# copia as quotas do usuário professor para msobral
edquota -p professor msobral
Outra forma de definir quotas de forma não-interativa (bom para shell scripts ou outros programas que automatizem o gerenciamento de usuários) é com o utilitário setquota. Com esse programa devem-se informar diretamente na linha de comando os limites tanto de espaço em disco quanto de arquivos:
# Define quotas para o usuário msobral:
# espaço em disco: soft limit = 100 MB, hard limit = 150 MB
# quantidade de arquivos: ilimitado
setquota -u msobral 100000 150000 0 0 /usuarios
Finalmente, os usuários que excederam seus soft limit podem ser alertado por email pelo utilitário warnquota. Esse programa pode ser executado periodicamente pelo agendador de tarefas (ex: diariamente).
Sumário de utilitários sobre quotas
- quota: visualização de quotas
- quotaon: ativação de quotas em sistemas de arquivos (executado normalmente no boot)
- quotacheck: verificação dos dados sobre quotas (contidos no arquivo aquota.user)
- edquota: edição de quotas de usuários e grupos
- setquota: outro utilitário para editar quotas
- repquota: relatório de quotas de todos os usuários
- warnquota: alerta usuários com quotas excedidas
Atividade
- Configure o Linux para permitir o uso de quotas de usuários no “/home”.
- Estabeleça para os usuários do tipo alunos a seguinte quota: blocos (soft = 500 e hard = 1000).
- Estabeleça para os usuários do tipo professores e servidores a seguinte quota: blocos (soft = 600 e hard = 800).
- Logue como estes usuários e crie ou copie vários arquivos dentro de seus homes e verifique as mensagens de estouro de quotas de usuários.
- Crie um usuário chamado operador, e defina que sua quota é ilimitada. Crie arquivos para esse usuário, e verifique se há alguma restrição do sistema de quotas.
- Em um servidor se deseja limitar que alunos no total não excedam 100 MB, e professores e servidores estejam limitados a 200 MB. Quer dizer, todos os alunos juntos não podem execeder esse limite, assim como profesores e funcionários. Pesquise como implementar isto com o sistema de quotas do Linux (dica: veja quotas para grupos).
04/03: Quotas de disco
Continuou-se a aula sobre quotas.
08/03: Agendamento de tarefas
Agendamento de tarefas administrativas com crontab. Apostila de Gerência de Redes, capítulo 19.
O cron é um programa de agendamento de tarefas. Com ele pode-se fazer a programação para execução de qualquer programa numa certa periodicidade ou até mesmo em um exato dia, numa exata hora. Um uso comum do cron é o agendamento de tarefas administrativas de manutenção do seu sistema, como por exemplo, análise de segurança w backup. Estas tarefas são programadas para, todo dia, toda semana ou todo mês, serem automaticamente executadas através da crontab e um script shell comum. A configuração do cron geralmente é chamada de crontab.
Os sistemas Linux possuem o cron na instalação padrão. A configuração tem duas partes: uma global, e uma por usuário. Na global, controlada pelo root, o crontab pode ser configurado para executar qualquer tarefa de qualquer lugar, como qualquer usuário. Já na parte por usuário, cada usuário tem seu próprio crontab, sendo restringido apenas ao que o usuário pode fazer (e não tudo, como é o caso do root).
Uso do crontab
Para configurar um crontab por usuário, utiliza-se o comando crontab, junto com um parâmetro, dependendo do que se deseja fazer. Abaixo uma relação:
- crontab -e: Edita a crontab atual do usuário logado
- crontab -l: Exibe o atual conteúdo da crontab do usuário
- crontab -r: Remove a crontab do usuário
Se você quiser verificar os arquivos crontab dos usuários, você precisará ser root. O comando crontab coloca os arquivos dos usuários no diretório /var/spool/cron/crontabs . Por exemplo, a crontab do usuário aluno estará no arquivo /var/spool/cron/crontabs/aluno.
Existe também uma crontab global, que fica no arquivo /etc/crontab, e só pode ser modificado pelo root. Vamos estudar o formato da linha do crontab, que é quem vai dizer o que executar e quando. Vamos ver um exemplo:
30 12,22 * * * /home/aluno/scripts/backup.sh >/dev/null 2>&1
A linha é dividida em campos separados por tabs ou espaço:
| Campo | Função |
|---|---|
| 1o | Minuto |
| 2o | Hora |
| 3o | Dia do mês |
| 4o | Mês |
| 5o | Dia da semana |
| 6o | Programa a ser executrado |
Todos estes campos, sem contar com o 6o., são especificados por números. Veja a tabela abaixo para os valores destes campos:
| Campo | Função |
|---|---|
| Minuto | 0-59 |
| Hora | 0-23 |
| Dia do mês | 1-31 |
| Mês | 1-12 |
| Dia da semana | 0-6 (0=domingo, 6=sábado) |
Então o que nosso primeiro exemplo estava dizendo? A linha está dizendo: "Execute o comando /root/scripts/backup.sh às 12:30 h e às 22:30h, todos os dias".
Vamos analisar mais alguns exemplos:
1,21,41 * * * * echo "Meu crontab rodou mesmo!"
Aqui está dizendo: "Executar o comando do sexto campo toda hora, todo dia, nos minutos 1, 21 e 41".
30 4 * * 1 rm -rf /tmp/*
Aqui está dizendo: "Apagar todo conteúdo do diretório /tmp toda segunda-feira, as 4:30 da manhã."
45 19 1,15 * * /usr/local/bin/backup
Aqui está dizendo: "Executar o comando 'backup' todo dia 1 e 15 às 19:45.".
E assim pode-se ir montando inúmeros jeitos de agendamento possível. No arquivo do crontab global, o sexto campo pode ser substituído pelo nome do usuário, e um sétimo campo adicionado com o programa para a execução, como mostrado no exemplo a seguir:
*/5 * * * * root /usr/bin/mrtg /etc/mrtg/mrtg.cfg
Aqui está dizendo: "Executar o mrtg como usuário root, de 5 em 5 minutos sempre."
0 19-23/2 * * * /root/script
Aqui está dizendo: “Executar o 'script' entre as 19 e 23 de 2 em duas horas.”
Atividade
- Agende o comando date para escrever/adicionar sua saída ao arquivo /root/date a cada minuto.
- Pressuponha que o script /root/abacaxi.sh exista, agende o mesmo para ser executado:
- De dois em dois dias às 11 h e 55 min.
- Todo dia 5 às 3 h e 50 min.
- No dia 14 de cada mês entre as 8 e 18 h, de hora em hora.
11/03: Backups
Obs: o conteúdo abaixo foi copiado do capítulo 20 da apostila.
Um dos principais quesitos de segurança de redes é a integridade física dos dados e informações armazenadas.
O backup é uma ou várias cópias de segurança dos dados, para a recuperação dos dados em caso de acidentes. Objetiva assegurar a integridade contra possíveis quedas do sistema ou problemas com o disco principal. Inlcui também assegurar a recuperação de arquivos de usuários apagados/corrompidos acidentalmente ou não.
Existem várias formas de se garantir a disponibilidade da informação. A mais importante sem dúvidas é a cópia destes dados em local seguro, ou seja, o backup de dados, pois traz flexibilidade à organização de, a qualquer momento, voltar no tempo com os seus dados. O conceito de um local seguro por muitas vezes é o maior ponto de variação dentro do assunto backup e este merece atenção especial, pois por muitas vezes pensamos que o local seguro possa ser a torre do prédio ao lado, o que nem sempre é verdade.
Existem várias formas de se fazer o backup dos dados. Formas simples e baratas para pequenas empresas e usuários domésticos, que possuem poucas informações. Formas mais complexas e caras nas médias e grandes corporações, onde a quantidade de informações é imensa e também precisa de um backup desses dados. Isso nos leva a questão de política de backup e forma de armazenamento, onde existe então esta variação de custo X segurança. Entre estes pontos é possível se chegar a extremos de confiabilidade o que por muitas vezes é diminuído devido ao custo da solução. A escolha de uma boa política aliada a uma forma de armazenamento suficientemente adequada à situação pode trazer ao administrador um custo compatível com o valor da informação que ele deseja salva-guardar.
Tipos de backup
O tipo de backup a ser utilizado varia de acordo com cada organização, dependendo da quantidade de informação, e da velocidade que estas informações são atualizadas, cabe ao administrador de rede e/ou gestor de política de segurança analisar e definir a melhor forma. Basicamente existem 3 tipos.
Backups totais
Um backup total captura todos os dados, incluindo arquivos de todas as unidades de disco rígido. Cada arquivo é marcado como tendo sido submetido a backup; ou seja, o atributo de arquivamento é desmarcado ou redefinido. Uma fita atualizada de backup total pode ser usada para restaurar um servidor completamente em um determinado momento.
Vantagens :
- Cópia total dos dados: isso significa que você tem uma cópia completa de todos os dados e se for necessária uma recuperação do sistema torna-se mais prático.
- Acesso rápido aos dados de backup: não é necessário pesquisar em várias fitas para localizar o arquivo que deseja restaurar, porque os backups totais incluem todos os dados contidos nos discos rígidos em um determinado momento.
Desvantagens:
- Dados redundantes: backups totais mantêm dados redundantes, porque os dados alterados e não alterados são copiados para fitas sempre que um backup total é executado.
- Tempo: backups totais levam mais tempo para serem executados e podem ser muito demorados.
- Espaço em midia: manter várias versões de backups totais exige uma quantidade grande de midia para essa finalidade (ex: fitas ou discos rígidos)
Backups incrementais
Backup incremental captura todos os dados que foram alterados desde o backup total ou incremental mais recente. Você deve usar uma fita de backup total (não importa há quanto tempo ela tenha sido criada) e todos os conjuntos de backups incrementais subseqüentes para restaurar um servidor. Um backup incremental marca todos os arquivos como tendo sido submetidos a backup; ou seja, o atributo de arquivamento é desmarcado ou redefinido.
Vantagens:
- Uso eficiente do tempo: o processo de backup leva menos tempo porque apenas os dados que foram modificados ou criados desde o último backup total ou incremental são copiados para a fita.
- Uso eficiente da mídia de backup: o backup incremental usa menos fita porque apenas os dados que foram modificados ou criados desde o último backup total ou incremental são copiados para a fita.
Desvantagens:
- Restauração completa complexa: pode ser necessário restaurar os dados de um conjunto incremental de várias fitas para obter uma restauração completa do sistema.
- Restaurações parciais demoradas: pode ser necessário pesquisar em várias fitas para localizar os dados necessários para uma restauração parcial.
Há uma variação desse tipo de backup em que a cada backup se armazenam somente as partes dos arquivos que foram modificadas, ao invés de salvar todos os arquivos alterados. Desta forma se aproveita melhor o espaço disponível na midia de backup, porém ao custo de maior processamento para identificar os dados alterados e também para recuperar versões de arquivos.
Backups diferenciais
Um backup diferencial captura os dados que foram alterados desde o último backup total. Você precisa de uma fita de backup total e da fita diferencial mais recente para executar uma restauração completa do sistema. Ele não marca os arquivos como tendo sido submetidos a backup (ou seja, o atributo de arquivamento não é desmarcado).
Vantagem:
- Restauração rápida: a vantagem dos backups diferenciais é que eles são mais rápidos do que os backups incrementais, porque há menos fitas envolvidas. Uma restauração completa exige no máximo dois conjuntos de fitas — a fita do último backup total e a do último backup diferencial.
Desvantagens:
- Backups demorados e maiores: backups diferenciais exigem mais espaço em fita e mais tempo do que backups incrementais porque quanto mais tempo tiver se passado desde o backup total, mais dados haverá para copiar para a fita diferencial.
- Aumento do tempo de backup: a quantidade de dados dos quais é feito backup aumenta a cada dia depois de um backup total.
Modos de backup
O modo de backup determina como o backup deve ser executado em relação ao tipo de dados a serem incluídos nele. Há duas maneiras de executar os backups de dados.
Backup online
São backups feitos em servidores que precisam estar 24h por dia disponível aos usuários. Geralmente são banco de dados, servidores de e-mail, etc. Um detalhe bastante importante é que o software de backup e a aplicação precisam ter suporte a este tipo de backup.
Vantagem:
- Servidor sempre disponível podendo ser realizado o backup durante o expediente normal de trabalho.
Desvantagem:
- O desempenho do servidor é prejudicado durante a realização do backup.
Backup offline
São backups de dados feito quando ninguém está tentando acessar as informações. Geralmente é agendado para ser realizado à noite.
Vantagem:
- Como o servidor estará apenas fazendo o backup dos dados é mais rápido que o processo de backup on-line.
Desvantagem:
- Ninguém poderá acessar os dados durante a execução do backup.
Softwares de backup
Existem muitos softwares de backup que combinam diferentes características como as apontadas nas subseções anteriores.
- Lista de softwares de backup obtida na Wikipedia
- Uma comparação entre softwares de backup feita pelo pelo projeto Box Backup
Dentre os softwares listados, escolheu-se Amanda por razões históricas e por seu funcionamento razoavelmente simples.
Amanda
O Amanda (Advanced Maryland Automatic Network Disk Archiver) é um sistema de backup cliente/servidor. Um servidor Amanda realiza num único dispositivo de armazenamento (fita ou disco rígido) o backup de qualquer número de computadores que tenham o cliente do Amanda e uma conexão de rede com o servidor. Um problema comum em locais com um grande número de discos é que a quantidade de tempo requerida para o backup dos dados diretamente na fita excede a quantidade de tempo para a tarefa. O Amanda resolve este problema utilizando um disco auxiliar para realizar o backup de diversos sistemas de arquivos ao mesmo tempo. O Amanda cria “conjuntos de arquivos”: um grupo de fitas utilizadas sobre o tempo para criar os backups completos de todos os sistemas de arquivos listados no arquivo de configuração do Amanda. O “conjunto de arquivos” também pode conter backups incrementais (ou diferenciais) noturnos de todos os sistemas de arquivos. Para restaurar um sistema de arquivos é necessário o backup completo mais recente e os incrementais, este controle é feito pelo próprio Amanda.
O arquivo de configurações provê um controle total da realização dos backups e do tráfego de rede que o Amanda gera. O Amanda utilizará qualquer programa de backup para gravar os dados nas fitas, por exemplo tar. O Amanda está disponível como pacote na maioria das distribuições Linux, e também em código fonte, porém ele não é instalado por padrão.
Referências sobre Amanda:
Para instalar o servidor Amanda no Ubuntu devem-se executar os seguintes comandos:
sudo apt-get install amanda-common
sudo apt-get install amanda-server
sudo apt-get install dump
Para instalar o cliente Amanda:
sudo apt-get install amanda-common
sudo apt-get install amanda-client
Após a instalação o diretório de configuração padrão /etc/amanda estará criado, porém sem os arquivos de configuração. Esses podem ser obtidos de um exemplo. Em seguida deve-se adaptar a configuração para a nova instalação, usando-se o manual online quando necessário:
- man amanda
- man amanda.conf
- man amanda-client.conf
Como exemplo pode-se configurar o sistema para um backup fictício, já que não dispomos de unidades de fita para um verdadeiro backup. Para “Backup em HD com Amanda” pode-se ver um tutorial. Há também uma documentação mais detalhada no sitio do Amanda.
Atividade
- Instale configure o Amanda para atender a seguinte lista de configurações:
- Fita do tipo HARD-DISK
- Número de fitas disponíveis igual a 20.
- Rótulos nas fitas Gerencia.
- Ciclo de dumps igual a 5 dias.
- Nome da organização Gerencia.
- Acrescente um cliente, que corresponde a um diretório de localhost a ser salvo no backup.
- Faça alguns backups, e investigue onde e como os backups foram salvos (comando amcheck Gerencia)
- Recupere um dos backups, gravando os arquivos em um diretório a parte
- Acrescente um computador de um colega como cliente
- Repita o procedimento de backup e recuperação
15/03: Shell scripts para automatizar tarefas
Capítulo 21 da apostila.
- Shell scripts: programas interpretados pelo shell (no nosso caso, bash)
- Estrutura de um shell script:
#!/bin/bash # Este programa diz alo echo "Alo $LOGNAME, tenha um bom dia!"
- Variáveis:
- Definição de variáveis
- Mostrando o valor de variáveis
#!/bin/bash dir=/home/aluno desktop=$dir/Desktop echo Seu diretorio home é $dir echo Sua área de trabalho do ambiente gráfico fica no diretório $desktop
- Forma alternativa de mostrar valores de variáveis:Repare nas chaves em volta do nome da variável. Isto é particularmente necessário quando se deseja delimitar o nome da variável, como no exemplo abaixo:
#!/bin/bash dir=/home/aluno desktop=${dir}/Desktop echo Seu diretorio home é ${dir} echo Sua área de trabalho do ambiente gráfico fica no diretório ${desktop}
#!/bin/bash basedir=/home/aluno # a sentença abaixo funciona como esperado echo aluno1 tem diretório home ${basedir}1 # ... mas esta a seguir não ! echo aluno1 tem diretório home $basedir1
- Forma alternativa de mostrar valores de variáveis:
- Argumentos de execução do shell
#!/bin/bash echo Quantidade de argumentos: $# echo Os argumentos são: $* echo Nome do script: $0 echo Primeiro argumento: $1 echo Segundo argumento: $2
- Mostrando parte do conteúdo de uma variável (o equivalente a substrings):
#!/bin/bash letras=abcdefghjijklmnopqrstuvwxyz echo Todas as letras: ${letras} echo Quantidade de caracteres na variável letras: ${#letras} echo a primeira letra: ${letras:0:1} echo 5 primeiras letras: ${letras:0:5} echo a última letra: ${letras:${#letras}-1} echo 5 últimas letras: ${letras:${#letras}-5:${#letras}} echo ... ou ... ${letras:${#letras}-5} echo a primeira metade das letras: ${letras:0:${#letras}/2} echo a segunda metade das letras: ${letras:${#letras}/2}
- Tratando variáveis que podem estar indefinidas ou vazias:
#!/bin/bash x=ok echo Variavel x=${x} # Mostra o valor "vazia", porque y é uma variável indefinida, mas não altera y echo Variavel y=${y:-vazia} echo Variavel y=${y} # Mostra o valor "vazia", porque y é uma variável indefinida, e faz com que y="vazia" echo Variavel y=${y:=vazia} echo Variavel y=${y}
- Variáveis predefinidas: LOGNAME, HOME, PATH, MAIL, EDITOR, PAGER, SHELL, TERM, HOST, ...
- Captura do resultado da execução de comandos
#!/bin/bash resultado=$(ls $HOME | wc -l) echo Existem $resultado arquivos ou diretórios em $HOME
- Expressões aritméticas:
#!/bin/bash x=1 y=3 # Abaixo apenas concatena os valores de x e y echo x + y = ${x} + ${y} # Abaixo faz a soma de x e y echo x + y = $((${x} + ${y}))
- Estruturas condicionais:
- Teste de condição: se condição então ... senão ... fimSe
#!/bin/bash # Este programa também diz alo if [ "$LOGNAME" = "root" ]; then echo "Alo SENHOR, tenha um bom dia ... e às suas ordens !" else echo "Alo $LOGNAME, tenha um bom dia." fi
- Condições a serem usadas no if ... then ... else se baseiam no programa test. Alguns exemplos:
x=0 y=1 # operador -eq: igualdade numerica if [ $x -eq 0 ]; then echo Variavel x zerada fi # operador -o: OU logico if [ $x -eq 1 -o $y -eq 1 ]; then echo Uma das variáveis x ou y tem valor diferente de zero fi # operador -a: E logico if [ $x -eq 1 -a $y -eq 1 ]; then echo Ambas variáveis x ou y tem valor diferente de zero fi # operador -le: <= (less or equal) if [ $x -le 10 ]; then echo Variável x menor ou igual a 10 fi # operador -lt: < (less than) if [ $x -lt 10 ]; then echo Variável x menor que 10 fi # operador -ge: >= (greater or equal) if [ $x -ge 10 ]; then echo Variável x maior ou igual a 10 fi # operador -gt: > (greater than) if [ $x -gt 10 ]; then echo Variável x maior que 10 fi # operador !: NEGACAO if [ ! $x -gt 10 ]; then echo Variável x menor ou igual a 10 fi
- Variações do uso do teste condicional:
if comando then comandos executados se "comando" retornar status "ok" (0) else comandos executados se "comando" retornar status "não ok" (diferente de 0) fi if comando1 then comandos executados se "comando1" retornar status "ok" (0) elif comando2 comandos executados se "comando2" retornar status "ok" (0) else comandos executados se não entrar nos "if" acima fi comando1 && comando2 # construção na linha acima eh equivalente a (porta E): if comando1 then comando2 fi comando1 || comando2 # construção na linha acima eh equivalente a (porta OU): if comando1 then : else comando2 fi
- Condições a serem usadas no if ... then ... else se baseiam no programa test. Alguns exemplos:
- Selecionando entre múltiplos valores:
#!/bin/bash case $x in 0) echo x=zero ;; 1) echo x=um ;; *) echo x desconhecido: $x ;; esac
- Teste de condição: se condição então ... senão ... fimSe
Programas úteis
Os programas utilitários abaixo são comumente usados em shell scripts:
- basename: mostra o prefixo de um pathname (ex: ao executar dirname /home/aluno/Desktop se obtém /home/aluno)
- dirname: mostra o último componente de um pathname (ex: ao executar basename /home/aluno/Desktop se obtém Desktop)
- cut: divide as linhas dos arquivos em colunas, e mostra colunas específicas
- grep: mostra linhas de arquivos que contenham determinada palavra ou padrão de caracteres
- sort: ordena as linhas de um arquivo
- paste: combina linhas de arquivos
- wc: conta linhas, palavras e caracteres
- tail: mostra as últimas linhas de um arquivo
- head: mostra as primeiras linhas de um arquivo
- du: mostra a utilização de disco de um determinado arquivo ou diretório
Atividade
- Faça um script que mostre os 5 usuários que estão ocupando mais espaço em seus diretórios home.
- Modifique o script acima para que a quantidade de usuários a serem mostrados seja parametrizada.
- Faça um script que obtenha o código fonte de um programa, descompacte-o e compile-o, e, finalmente, instale-o. Assuma que o software esteja compactado com tar e gzip, e que para compilá-lo deve-se seguir o procedimento visto na aula de 11/02. Para testá-lo use o programa lynx, cujo código fonte se encontra aqui.
- Faça um script que mostre o nome completo de um usuário, a partir do seu login informado como argumento de linha de comando.
Solução 1:Solução 2 (mais simples, porém só funciona para usuários locais):#!/bin/bash usuario=${1:?Informe um usuario} nome=$(finger $usuario | head -1) nome=$(echo $nome | cut -d" " -f4-) echo Nome completo: ${nome:-INEXISTENTE!!!}
#!/bin/bash usuario=${1:?Informe um usuario} nome=$(grep ${usuario} /etc/passwd | cut -d: -f5) echo Nome completo: ${nome:-INEXISTENTE !!!}
- Faça um script que mostre os grupos a que pertence um usuário. Esse script deve consultar os arquivos /etc/passwd e /etc/group.
Solução 1: funciona, mas pode mostrar grupos errados se o usuário informado for uma substring do nome de outro usuário:Solução 2: trata o caso que geraria erro na solução 1:#!/bin/bash usuario=${1:?Informe um usuario} grupos=$(grep ${usuario} /etc/group | cut -d: -f1) echo Grupos: ${grupos}
#!/bin/bash usuario=${1:?Informe um usuario} grupos=$(grep -E "(:${usuario}|,${usuario}$|,${usuario},)" /etc/group | cut -d: -f1) echo Grupos: ${grupos}
- Faça um script que mostre o seguinte resultado, para um dado usuário:
Quantidade de processos para um_usuario: um_numero Os PIDs de seus processos são: lista de PIDs
- Script apaga contas sem uso: sabe-se que a cada logon do usuário, pelo menos um de seus arquivos é modificado. Sabe-se também que o usuário tem arquivos em /home/nome_do_usuario e em /home/samba/profiles/home_do_usuario. Faça um script teste se um dado usuário não se logou faz mais de 12 meses, e remova sua conta caso afirmativo. Obs: ao remover a conta o script deve salvar uma cópia dos arquivos do usuário, usando o programa tar combinado com gzip.
18/03: Shell scripts para automatizar tarefas
Continuação do conteúdo da aula anterior, que foi somente até variáveis. Estruturas de repetição:
- for:
#!/bin/bash for dir in /home/*; do echo Diretório: ${dir} done for x in 1 2 3 4 5; do echo x = ${x} done for (( x=1; $x < 5; x=$x+1 )); do echo x=$x done
- while:
#!/bin/bash # enquanto x <= 5 while [ ${x} -le 5 ]; do echo $x x=$(($x+1)) done # Mostra os processos do usuario aluno, enquanto ele estiver logado while (who | grep aluno > /dev/null); do date ps aux | grep aluno echo "" sleep 5 done
Atividades
- Faça um script que estabeleça cotas a todos os usuários do sistema, a partir do usuário padrão de nome modelo.
Solução:#!/bin/bash lista=$(cut -d: -f1 /etc/passwd) for usuario in $lista; do if [ ${usuario} != root ]; then edquota -p modelo $usuario fi done
- Em um diretório existem diversos arquivos compactados com zip, como se pode ver abaixo: Faça um script que descompacte cada arquivo desses em um subdiretório que tenha o nome do arquivo em questão, porém excluída sua extensão (ex: para banana.zip, deve-se descompactá-lo dentro de "banana"). Dica: use o esqueleto de script mostrado abaixo:
$ ls arq1.zip banana.zip laranja.zip $
Você pode usar os arquivos .zip contidos nesse arquivo (que está no formato TAR, apesar da extensão .pdf ...) Solução:#!/bin/bash for arq in *.zip; do echo $arq done
#!/bin/bash for arq in *.zip; do base=$(basename $arq .zip) mkdir $base cd $base unzip ../$arq cd .. done
- Script apaga contas sem uso: sabe-se que a cada logon do usuário, pelo menos um de seus arquivos é modificado. Sabe-se também que o usuário tem arquivos em /home/nome_do_usuario e em /home/samba/profiles/nome_do_usuario. Faça um script que apague usuários que não se logaram nos últimos 12 meses. Dica: use o script abaixo como ponto de partida, mas note que ele testa apenas um usuário (informado via argumento de linha de comando): Solução 1: assumindo que todo usuário tenha seu diretório home dentro de /home
#!/bin/bash usuario=${1:?Uso: $0 usuario} ok=$(find /home/$usuario -mtime -365 | wc -l) if [ $ok == 0 ]; then echo Removendo o usuario $usuario # Comando para executar o usuario else echo usuario $usuario nao serah removido ... fi
Solução 2: obtendo os usuários a partir de /etc/passwd (e filtrando os usuários de sistema, que possuem UID < 1000)#!/bin/bash cd /home for usuario in *; do ok=$(find /home/$usuario -mtime -365 | wc -l) ok2=$(find /home/samba/profiles/$usuario -mtime -365 |wc -l) if [ $ok -eq 0 -a $ok2 == 0 ]; then echo removendo conta else echo conta não será removida fi done
#!/bin/bash for usuario in $(cut -d: -f1 /etc/passwd); do uid=$(grep ^${usuario}: /etc/passwd | cut -d: -f3) if [ $uid -ge 1000 ]; then ok=$(find /home/$usuario -mtime -365 | wc -l) ok2=$(find /home/samba/profiles/$usuario -mtime -365 |wc -l) if [ $ok -eq 0 -a $ok2 -eq 0 ]; then echo removendo conta else echo conta não será removida fi fi done
- Script de alerta de quota a exceder: faça um script que verifica as quotas de todos os usuários, e gere uma lista de usuários cujas quotas estão excedidas ou prestes a exceder.
- Script trava contas coletivas: a saída do comando smbstatus |grep alunos é algo parecido com: Faça um script que gere uma lista das contas de alunos que estão sendo utilizadas por mais de uma pessoa em máquinas distintas ao mesmo tempo. Para isto deve-se rodar o dito comando a cada 5 minutos e verificar os usuários em duplicata, afonso no exemplo. O smbstatus tem um “retardo” que pode acusar dois logins simultâneos, mesmo isto não sendo verdade, para eliminar as duplicidades incorretas, deve-se analisar duas coletas seqüenciais e eliminar os casos em que a duplicidade de usuário não ocorre. Em resumo, se em uma coleta houver duplicidade, analisa-se a próxima, se o mesmo usuário estiver duplicado insere-se o mesmo na lista de contas coletivas.
7175 afonso alunos negreiros (192.168.1.161) 12168 afonso alunos idal (192.168.1.222) 12141 jessica alunos haley (192.168.1.169) 8443 vitorsd alunos costelo (192.168.1.144) 11326 felipesl alunos baraovermelho (192.168.1.113) 12641 1521 alunos 200.135.233.1 (200.135.233.1)
22/03: Shell scripts para automatizar tarefas
Continuação dos exercícios da aula de 18/03
25/03: 1a avaliação
1a avaliação individual
29/03: Serviços de rede
Visão geral de serviços e funções de rede típicos: Configuração de interfaces de rede. Noções de roteamento.
Ver capítulo 22 da apostila.
Correção da avaliação feita em 25/03
Parte prática:
- Questão 1: A solução envolve quatro tarefas:
- Particionar os discos, preparando-os para criação do volume RAID 1:
# Os discos devem aparecer como /dev/sdb e /dev/sdc # Para cada um dos discos, cria uma partição primária ocupando todo o disco. Marca como sendo tipo 8e (Linux LVM) fdisk /dev/sdb fdisk /dev/sdc
- Criação do volume RAID1 usando as partições criadas na tarefa 1:
# Cria um volume RAID 1 composto pelas partições dos discos acima, o qual será chamado de /dev/md0 mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1 # Grava a configuração do volume RAID, para que seja automaticamente reativado no boot mdadm --detail --scan >> /etc/mdadm/mdadm.conf
- Criação de um Volume Group LVM, usando como volume físico o volume RAID 1 criado na tarefa 2; criação de um volume lógico para cada sistema de arquivos:
# Prepara o volume RAID 1 para ser usado como volume físico LVM lvm pvcreate /dev/md0 # Cria o Volume Group, usando o volume RAID 1 como volume físico lvm vgcreate prova /dev/md0 # Cria um volume lógico para cada sistema de arquivos lvm lvcreate prova -L 1024M -n dir lvm lvcreate prova -L 800M -n cont lvm lvcreate prova -L 1200M -n tec lvm lvcreate prova -L 400M -n col # Formata os volumes lógicos mkfs.ext4 -j /dev/prova/dir mkfs.ext4 -j /dev/prova/cont mkfs.ext4 -j /dev/prova/tec mkfs.ext4 -j /dev/prova/col
- Criação dos pontos de montagem, e adição dos novos sistemas de arquivos a /etc/fstab:
# Cria os pontos de montagem for d in dir tec col cont; do mkdir -p /dados/$d done # adiciona os pontos de montagem a /etc/fstab for d in dir tec col cont; do echo "/dev/prova/$d /dados/$d ext4 defaults,quota 0 2" >> /etc/fstab done # Monta os sistemas de arquivos mount -a
- Particionar os discos, preparando-os para criação do volume RAID 1:
- Questão 2:
- Criação dos grupos diretoria, contabilidade, tecnologo e colaboradores, e de dois usuários para cada grupo:
for g in diretoria contabilidade tecnologo colaboradores; do groupadd $g done # usuarios da diretoria useradd -g diretoria -c "Diretor 1" -m dir1 useradd -g diretoria -c "Diretor 2" -m dir2 # esses usuarios devem tambem ser membros dos demais grupos ... for g in contabilidade tecnologo colaboradores; do usermod -G $g dir1 usermod -G $g dir2 done # usuarios da contabilidade useradd -g contabilidade -c "Contador 1" -m cont1 useradd -g contabilidade -c "Contador 2" -m cont2 # usuarios tecnologos useradd -g tecnologo -c "Tecnologo 1" -m tec1 useradd -g tecnologo -c "Tecnologo 2" -m tec2 # usuarios colaboradores useradd -g colaboradores -c "Colaborador 1" -m col1 useradd -g colaboradores -c "Colaborador 2" -m col2
- Definição dos grupos donos dos diretórios, e suas permissões:
# define os grupos donos dos diretorios chgrp diretoria /dados/dir chgrp contabilidade /dados/cont chgrp tecnologo /dados/tec chgrp colaboradores /dados/col # define as permissoes de acesso chmod g+rwx /dados/* chmod o-rwx /dados/dir chmod o-rwx /dados/cont chmod o-rwx /dados/tec chmod o+rx-w /dados/col
- Ativação de quotas e definição das quotas dos usuários:
# Primeiro deve-se inicializar o sistema de quotas nos sistemas de arquivos quotacheck -va # Definir as quotas dos usuários setquota -u dir1 150000 200000 0 0 /dados/dir setquota -u dir1 120000 150000 0 0 /dados/cont setquota -u dir1 800000 100000 0 0 /dados/tec setquota -u dir1 40000 50000 0 0 /dados/col edquota -p dir1 dir2 setquota -u cont1 120000 150000 0 0 /dados/cont edquota -p cont1 cont2 setquota -u tec1 800000 100000 0 0 /dados/tec edquota -p tec1 tec2 setquota -u col1 40000 50000 0 0 /dados/col edquota -p col1 col2 # Ativar as quotas quotaon -va
- Criação dos grupos diretoria, contabilidade, tecnologo e colaboradores, e de dois usuários para cada grupo:
- Questão 3:
- Escrever o script de faxina, que será gravado em /root/limpa.sh:
#!/bin/bash dir=${1:?Faltou o diretorio ... Uso: $0 diretorio N M} N=${2:?Faltou N ... Uso: $0 diretorio N M} M=${1:?Faltou M ... Uso: $0 diretorio N M} # Lista de arquivos a compactar. Exclui os arquivos já compactados por este script # (esses arquivos terão acrescidos a si o sufixo -FAXINA, e depois serão compactados) lista_compact=$(find $dir -type f -atime +$N ! -name "*-FAXINA.gz") # Lista de arquivos a remover (somente os compactados por este script) lista_remove=$(find $dir -type f -atime +$M -name "*-FAXINA.gz") # Compacta os arquivos que estã faz N dias sem acesso for arq in $lista_compact; do mv $arq ${arq}-FAXINA gzip ${arq}-FAXINA done # Remove os arquivos compactados que estão faz M dias sem acesso for arq in $lista_remove; do rm -f $arq done
- Editar a crontab, para que o script seja executado nos dias e horários especificados:
$ crontab -e 0 23 1-5 * * /root/scripts/limpa.sh /dados/dir 30 60 15 23 1-5 * * /root/scripts/limpa.sh /dados/cont 30 30 30 23 1-5 * * /root/scripts/limpa.sh /dados/tec 15 30 59 23 1-5 * * /root/scripts/limpa.sh /dados/col 7 15
- Escrever o script de faxina, que será gravado em /root/limpa.sh:
Visão geral de serviços de rede

- DHCP: configuração automática de endereços IP em máquinas clientes
- DNS: serviço de nomes, que associa nomes a endereços IP, entre outras finalidades.
- LDAP: serviço de diretórios (um banco de dados hierárquico), para guardar informações administrativas, tais como usuários, grupos e contatos de email, usadas por outros serviços de rede.
- HTTP: acesso a documentos em geral (uso mais notório para acesso a páginas Web)
- FTP: transferência de arquivos
- SMTP, IMAP4, POP3, LMTP: protocolos para envio de email e acesso a caixas de entrada
- NFS e Samba: sistemas de arquivos de rede
- Web proxy: controle de acesso e cache para acesso a WWW
- NAT: tradução transparente de endereços IP, para mascarar endereços internos de uma rede (função de rede)
- Filtro IP: restrições aplicadas a tráfego IP, visando melhorar o nível de segurança (função de rede)
- SSH: acesso remoto seguro ao shell em um servidor
- VPN: redes privativas virtuais
Interfaces de rede
Qualquer dispositivo (físico ou lógico) capaz de transmitir e receber datagramas IP. Interfaces de rede ethernet são o exemplo mais comum, mas há também interfaces PPP (seriais), interfaces tipo túnel e interfaces loopback. De forma geral, essas interfaces podem ser configuradas com um endereço IP e uma máscara de rede, e serem ativadas ou desabilitadas. Em sistemas operacionais Unix a configuração de interfaces de rede se faz com o programa ifconfig:
Para mostrar todas as interfaces:
dayna@dayna:~> ifconfig -a
dsl0 Link encap:Point-to-Point Protocol
inet addr:189.30.70.200 P-t-P:200.138.242.254 Mask:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1492 Metric:1
RX packets:34260226 errors:0 dropped:0 overruns:0 frame:0
TX packets:37195398 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:3
RX bytes:19484812547 (18582.1 Mb) TX bytes:10848608575 (10346.0 Mb)
eth1 Link encap:Ethernet HWaddr 00:19:D1:7D:C9:A9
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:37283974 errors:0 dropped:0 overruns:0 frame:0
TX packets:42055625 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:20939614658 (19969.5 Mb) TX bytes:18284980569 (17437.9 Mb)
Interrupt:16 Base address:0xc000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:273050 errors:0 dropped:0 overruns:0 frame:0
TX packets:273050 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:21564572 (20.5 Mb) TX bytes:21564572 (20.5 Mb)
dayna@dayna:~>
Para configurar uma interface de rede (que fica automaticamente ativada):
dayna@dayna:~> ifconfig eth1 192.168.1.100 netmask 255.255.255.0
Para desativar uma interface:
dayna@dayna:~> ifconfig eth1 down
Para ativar uma interface:
dayna@dayna:~> ifconfig eth1 up
Ao se configurar uma interface de rede, cria-se uma rota automática para a subrede diretamente acessível via aquela interface. Isto se chama roteamento mínimo.
dayna@dayna:~> ifconfig eth1 192.168.10.0 netmask 255.255.0.0
dayna@dayna:~> netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
192.168.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth1
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo
dayna@dayna:~>
Pode-se associar mais de um endreço a uma mesma interface de rede. Isto se chama IP alias:
dayna@dayna:~> ifconfig eth1:0 192.168.1.110 netmask 255.255.255.0
dayna@dayna:~> ifconfig eth1:1 192.168.2.100 netmask 255.255.255.0
dayna@dayna:~> ifconfig -a
eth1 Link encap:Ethernet HWaddr 00:19:D1:7D:C9:A9
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:37295731 errors:0 dropped:0 overruns:0 frame:0
TX packets:42068558 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:20942258027 (19972.0 Mb) TX bytes:18294794452 (17447.2 Mb)
Interrupt:16 Base address:0xc000
eth1:0 Link encap:Ethernet HWaddr 00:19:D1:7D:C9:A9
inet addr:192.168.1.110 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:16 Base address:0xc000
eth1:1 Link encap:Ethernet HWaddr 00:19:D1:7D:C9:A9
inet addr:192.168.2.100 Bcast:192.168.2.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:16 Base address:0xc000
dayna@dayna:~>
Configuração no boot
Todo sistema operacional possui alguma forma de configurar suas interfaces de rede, para que sejam automaticamente ativadas no boot com seus endereços IP. Por exemplo, em sistemas Linux Ubuntu (descrito em maiores detalhes em seu manual online), a configuração de rede se concentra no arquivo /etc/network/interfaces:
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo eth1
iface lo inet loopback
address 127.0.0.1
netmask 255.0.0.0
# a interface ethernet eth1
iface eth1 inet static
address 192.168.1.100
netmask 255.255.255.0
gateway 192.168.1.254
Esses arquivo é lido pelos scripts ifup e ifdown. Esses scripts servem para ativar ou parar interfaces específicas, fazendo todas as operações necessárias para isto:
# Ativa a interface eth1
ifup eth1
# Desativa a interface eth1
ifdown eth1
Para ativar, desativar ou recarregar as configurações de todas as interfaces de rede:
# desativa todas as interfaces de rede
sudo /etc/init.d/networking stop
# ativa todas as interfaces de rede
sudo /etc/init.d/networking start
# recarrega as configurações de todas as interfaces de rede
sudo /etc/init.d/networking restart
Rotas estáticas
Ver capítulo 23 da apostila.
Rotas estáticas podem ser adicionadas a uma tabela de roteamento. Nos sistemas operacionais Unix, usa-se o programa route:
# adiciona uma rota para a rede 10.0.0.0/24 via o gateway 192.168.1.254
route add -net 10.0.0.0 netmask 255.255.255.0 gw 192.168.1.254
# adiciona uma rota para a rede 172.18.0.0/16 via a interface PPP pp0
route add -net 172.18.0.0 netmask 255.255.0.0 dev ppp0
# adiciona a rota default via o gateway 192.168.1.254
route add default gw 192.168.1.254
# adiciona uma rota para o host 192.168.1.101 via o gateway 192.168.1.253
route add -host 192.168.1.101 gw 192.168.1.253
A tabela de rotas pode ser consultada com o programa netstat:
dayna@dayna:~> netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
10.0.0.0 192.168.1.254 255.255.255.0 U 0 0 0 eth1
192.168.1.101 192.168.1.253 255.255.255.0 UH 0 0 0 eth1
172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 ppp0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo
0.0.0.0 192.168.1.254 0.0.0.0 U 0 0 0 eth1
Rotas podem ser removidas também com route:
# remove a rota para 10.0.0.0/24
route delete -net 10.0.0.0 netmask 255.255.255.0
# remove a rota para o host 192.168.1.101
route delete -host 192.168.1.101
Atividade
- Verifique a configuração de sua interface de rede eth1, na máquina virtual Tecnologo-ger2. Se necessário corrija-a assim: ip 192.168.2.X, sendo X o número do computador + 100 (exemplo: para o micro 2 X=102), roteador default = 192.168.2.1.
- Teste a comunicação do seu computador, fazendo ping 192.168.2.1. Tente pingar outras máquinas da rede.
- Tente também pingar o IP 200.135.37.65.
- Veja a tabela de rotas, usando netstat -rn.
- Verifique a rota seguida pelos datagramas enviados, usando traceroute -n 200.135.37.65.
- Configure sua máquina virtual para que a informação de rede, configurada manualmente acima, fique permanente. Quer dizer, no próximo boot essa configuração deve ser ativada automaticamente.
- Adicione um IP alias a sua interface eth1. Esse novo IP deve estar na subrede 10.0.0.0.0/24
- Tente pingar os computadores de seus colegas, usando ambos endereços: da rede 192.168.2.0/24 e da rede 10.0.0.0/24.
- Enquanto acontecem os pings, visualize o tráfego pela interface eth1, usando o programa tcpdump:
# Mostra o tráfego ICMP que passa pela interface eth1 tcpdump -i eth1 -ln icmp - Pense em uma utilidade para IP alias ...
05/04: Coleta de tráfego e NAT
Obs: provas corrigidas
Coleta e análise de tráfego
Uma ferramenta básica de análise de tráfego de rede faz a coleta das PDUs por interfaces de rede, revelando as informações nelas contidas. Dois programas bastante populares para essa finalidade são:
- tcpdump: um analisador de tráfego em modo texto
dayna:/data/tmp # tcpdump -i dsl0 -ln tcp port 80 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on dsl0, link-type LINUX_SLL (Linux cooked), capture size 96 bytes 22:14:37.797702 IP 74.125.47.136.80 > 201.35.226.9.21688: F 3660173220:3660173220(0) ack 4262495618 win 122 <nop,nop,timestamp 403588225 348814601> 22:14:37.836844 IP 201.35.226.9.21688 > 74.125.47.136.80: . ack 1 win 54 <nop,nop,timestamp 348874613 403588225> 22:14:38.410477 IP 201.35.226.9.21688 > 74.125.47.136.80: F 1:1(0) ack 1 win 54 <nop,nop,timestamp 348874756 403588225> 22:14:38.770653 IP 74.125.47.136.80 > 201.35.226.9.21688: . ack 2 win 122 <nop,nop,timestamp 403589203 348874756> 22:14:39.906734 IP 64.233.163.83.80 > 201.35.226.9.23018: P 534213879:534214123(244) ack 1779175654 win 133 <nop,nop,timestamp 2294865159 348870211>
- wireshark: o equivalente em modo gráfico (porém com muitas outras funcionalidades)
Outros programas úteis (ou ao menos interessantes):
- iptraf: gera estatísticas de tráfego por interfaces de rede
- iftop: mostra os fluxos em uma interface de rede
- nstreams: analisa a saída do tcpdump, e revela os fluxos em uma rede
- driftnet: analisa o tráfego em uma interface, e captura imagens, videos e audio
NAT
A tradução de endereço de rede (NAT - Network Address Translation), proposta pela RFC 1631 em 1994, é uma função de rede criada para contornar o problema da escassez de endereços IP. Com a explosão no crescimento da Internet, e o mau aproveitamento dos endereços IP (agravado pelo endereçamento hierárquico), percebeu-se que o esgotamento de endereços poderia ser logo alcançado a não ser que algumas medidas fossem tomadas. Esse problema somente seria eliminado com a reformulação do protocolo IP, de forma a aumentar o espaço de endereços, que resultou na proposta do IPv6 em 1998. Porém no início dos anos 1990 a preocupação era mais imediata, e pensou-se em uma solução provisória para possibilitar a expansão da rede porém reduzindo-se a pressão por endereços IP. O NAT surgiu assim como uma técnica com intenção de ser usada temporariamente, enquanto soluções definitivas não se consolidassem. Ainda hoje NAT é usado em larga escala, e somente deve ser deixado de lado quando IPv6 for adotado mundialmente (o que deve demorar).
NAT parte de um princípio simples: endereços IP podem ser compartilhados por nodos em uma rede. Para isto, usam-se endereços IP ditos não roteáveis (também chamados de inválidos) em uma rede, sendo que um ou mais endereços IP roteáveis (válidos) são usados na interface externa roteador que a liga a Internet. Endereços não roteáveis pertencem às subredes 10.0.0.0/8, 192.168.0.0/16 e 172.16.0.0/12, e correspondem a faixas de endereços que não foram alocados a nenhuma organização e, portanto, não constam das tabelas de roteamento dos roteadores na Internet. A figura abaixo mostra uma visão geral de uma rede em que usa NAT:

Para ser possível compartilhar um endereço IP, NAT faz mapeamentos (IP origem, port origem, protocolo transporte) -> (IP do NAT, port do NAT, , protocolo transporte), sendo protocolo de transporte TCP ou UDP. Assim, para cada par (IP origem, port origem TCP ou UDP) o NAT deve associar um par (IP do NAT, port do NAT TCP ou UDP) (que evidentemente deve ser único). Assim, por exemplo, se o roteador ou firewall onde ocorre o NAT possui apenas um endeerço IP roteável, ele é capaz em tese de fazer até 65535 mapeamentos para o TCP (essa é a quantidade de ports que ele pode possui), e o mesmo para o UDP. Na prática é um pouco menos, pois se limitam os ports que podem ser usados para o NAT. Note que o NAT definido dessa forma viola a independência entre camadas, uma vez que o roteamento passa a depender de informação da camada de transporte.
NAT no Linux
Ver capítulo 35, seção 4, da apostila.
O NAT no Linux se configura com iptables. As regras devem ser postas na tabela nat, e aplicadas a chain POSTROUTING, como no seguinte exemplo:
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -o eth0 -j MASQUERADE
A regra acima faz com que todo o tráfego originado em 192.168.1.0/24, e que sai pela interface eth0 deve ser mascarado com o endereço IP dessa interface. Esta regra diz o seguinte: todos os pacotes que passarem (POSTROUTING) por esta máquina com origem de 192.168.1.0/24 e sairem pela interface eth0 serão mascarados, ou seja sairão desta máquina com o endereço de origem como sendo da eth0. O alvo MASQUERADE foi criado para ser usado com links dinâmicos (tipicamente discados ou ADSL), pois os mapeamentos se perdem se o link sair do ar. Para uso mais geral, com links permanentes, deve-se usar o alvo SNAT:
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -o eth0 -j SNAT --to-source 200.135.37.66
Uma outra possibilidade é mapear para um endereço da rede interna um tráfego originado externamente. Por exemplo, pode haver um servidor na rede interna que precisa ser acessado externamente, porém ele não possui um endereço IP roteável. O NAT no Linux possui a função DNAT que pode fazer essa tarefa:
iptables -t nat -A PREROUTING -p tcp -d 200.135.37.66 --dport 8080 -i eth0 -j DNAT --to-destination 192.168.1.10:80
Nesse exemplo, datagramas com IP destino 200.135.37.66 e contendo um segmento TCP com port 8080 são desviados para o port 80 no IP 192.168.1.10. Quer dizer, o IP de destino desses datagramas é de fato substituído por 192.168.1.10, e o port de destino é mudado para 80.
Note que DNAT é aplicado a chain PREROUTING.
Com estas configurações o cliente acessa qualquer site na internet mas não pode ser acessado. Por isto alguns textos colocam NAT na categoria de técniccas de segurança. Apesar de NAT prover o isolamento entre rede externa e interna, a não ser para os tráfegos mapeados, não se pode usá-lo sozinho como proteção de uma rede. Quer dizer, não se pode prescindir de um bom firewall e políticas de segurança adequadas.
Atividade
- Coleta de tráfego
- Faça um ou mais pings para algum(ns) sítios e, com o uso de parâmetros apropriados, faça com que o tcpdump:
- Capture todos os pacotes da rede.
- Capture somente os pacotes gerados por sua máquina.
- Capture somente pacotes destinados à sua máquina.
- Capture pacotes destinados ou originados da máquina 172.18.0.1.
- Faça com que os pacotes capturados anteriormente sejam salvos num arquivo, chamado “pacotes_capturados“.
- Se desejar instale e capture pacotes com o WireShark.
- Faça um ou mais pings para algum(ns) sítios e, com o uso de parâmetros apropriados, faça com que o tcpdump:
- Roteamento estático
- Configure a segunda interface de rede de sua máquina servidora, conforme números de IPs sugeridos na Ilustração mais abaixo.
- Configure sua máquina servidora para rotear pacotes.
- Configure sua máquina cliente para ser seu cliente de rede, conforme Ilustração 1.
- Montar as tabelas estáticas de roteamento de modo que todas as máquinas tenham acesso entre si (“pingando” ente elas).
- Faça testes. Se houver problemas usar tcpdump ou WireShark para monitorar individualmente as interfaces e verificar onde está o problema. Lembre-se que os pacotes devem ter rota de ida e volta, portanto o problema pode ser no seu roteador ou de seu vizinho. Uma boa sequência de testes é:
- Pingar entre cliente e roteador.
- Do cliente pingar a interface externa do roteador.
- Do cliente pingar a máquina do professor. Se funcionar até aqui seu roteador estará corretamente configurado.
- Do roteador pingar a interface externa de outro roteador.
- Do roteador pingar outro cliente.
- Do seu cliente pingar outro cliente.
- NAT
- Desfaça as tabelas de roteamento e configure a máquina servidora para fazer NAT, nos mesmos moldes do item 2.
- Faça testes pingando para redes externas e para as redes dos colegas.

08/04: DNS
Ver capítulo 25 da apostila.
DNS (Domain Name System) é uma base de dados distribuída e hierárquica. Nela se armazenam informações para mapear nomes de máquinas da Internet para endereços IP e vice-versa, informação para roteamento de email, e outros dados utilizados por aplicações da Internet.
A informação armazenada no DNS é identificada por nomes de domínio que são organizados em uma árvore, de acordo com as divisões administrativas ou organizacionais. Cada nodo dessa árvore, chamado de domínio, possui um rótulo. O nome de omínio de um nodo é a concatenação de todos os rótulos no caminho do nodo até a raiz. Isto é representado como uma string de rótulos listados da direita pra esquerda e separados por pontos (ex: ifsc.edu.br, sj.ifsc.edu.br). Um rótulo precisa ser único somente dentro do domínio pai a que pertence.
Por exemplo, um nome de domínio de uma máquina no IFSC pode ser mail.ifsc.edu.br, em que br é o domínio do topo da hierarquia ao qual mail.sj.ifsc.edu.br pertence. Já edu é um subdomíno de br, ifsc um subdomínio de edu, e mail o nome da máquina em questão.
Por razões administrativas, o espaço de nomes é dividido em áreas chamadas de zonas, cada uma iniciando em um nodo e se estendendo para baixo para os nodos folhas ou nodos onde outras zonas iniciam. Os dados de cada zona são guardados em um servidor de nomes, que responde a consultas sobre uma zona usando o protocolo DNS.
Clientes buscam informação no DNS usando uma biblioteca de resolução (resolver library), que envias as consultas para um ou mais servidores de nomes e interpreta as respostas.

(tirado do manual do BIND9)
Ver também o livro sobre DNS e BIND da O'Reilly.
Registros DNS
Cada rótulo na hierarquia DNS possui um conjunto de informações associadas a si. Essas informações são guardas em registros de diferentes tipos, dependendo de seu significado e propósito. Cada consulta ao DNS retorna assim as informações do registro pedido associado ao rótulo. Por exemplo, para ver o registro de endereço IP associado a www.ifsc.edu.br pode-se executar esse comando (o resultado teve alguns comentários removidos):
msobral@dell-iron:~$ dig sj.ifsc.edu.br mx
;; QUESTION SECTION:
;sj.ifsc.edu.br. IN MX
;; ANSWER SECTION:
sj.ifsc.edu.br. 3600 IN MX 10 hendrix.sj.ifsc.edu.br.
;; AUTHORITY SECTION:
sj.ifsc.edu.br. 3600 IN NS ns.pop-udesc.rct-sc.br.
sj.ifsc.edu.br. 3600 IN NS ns.pop-ufsc.rct-sc.br.
sj.ifsc.edu.br. 3600 IN NS hendrix.sj.ifsc.edu.br.
;; ADDITIONAL SECTION:
hendrix.sj.ifsc.edu.br. 3600 IN A 200.135.37.65
ns.pop-ufsc.rct-sc.br. 11513 IN A 200.135.15.3
ns.pop-udesc.rct-sc.br. 37206 IN A 200.135.14.1
Cada uma das informações acima mostra um determinado registro e seu conteúdo, como descrito na tabela abaixo:
| Nome | TTL | Classe | Registro | Conteúdo do registro |
|---|---|---|---|---|
| hendrix.sj.ifsc.edu.br. | 3600 | IN | A | 200.135.37.65 |
| sj.ifsc.edu.br. | 3600 | IN | NS | hendrix.sj.ifsc.edu.br. |
| sj.ifsc.edu.br. | 3600 | IN | MX | 10 hendrix.sj.ifsc.edu.br. |
Obs: TTL é o tempo de validade (em segundos) da informação retornada do servidor de nomes, e classe é o tipo de endereço (no caso IN equivale a endereços Internet).
Os tipos de registros mais comuns são:
| Registro | Descrição | Exemplo |
|---|---|---|
| A | Endereço (Address) | www.sj.ifsc.edu.br IN A 200.135.37.66 |
| NS | Servidor de nomes (Name Server) | sj.ifsc.edu.br IN NS hendrix.sj.ifsc.edu.br. |
| CNAME | Apelido (Canonical Name) | mail.sj.ifsc.edu.br IN CNAME hendrix.sj.ifsc.edu.br. |
| MX | Roteador de email (Mail Exchanger) | sj.ifsc.edu.br IN MX mail.sj.ifsc.edu.br. |
| SOA | dados sobre o domínio (Start of Authority) | sj.ifsc.edu.br IN SOA hendrix.sj.ifsc.edu.br. root.sj.ifsc.edu.br. 2009120102 1200 120 604800 3600 |
| PTR | Ponteiro para nome (Pointer) | 65.37.135.200.in-addr.arpa IN PTR hendrix.sj.ifsc.edu.br. |
| TXT | Texto genérico (Text) | sj.ifsc.edu.br IN TXT "v=spf1 a mx ~all" |
Uma zona assim é composta de um conjunto de registros com todas as informações dos domínios nela contidos. O conteúdo de uma zona, contendo o domínio example.com, pode ser visualizado abaixo:
example.com 86400 IN SOA ns1.example.com. hostmaster.example.com. (
2002022401 ; serial
10800 ; refresh
15 ; retry
604800 ; expire
10800 ; minimum
)
IN NS ns1.example.com.
IN NS ns2.smokeyjoe.com.
IN MX 10 mail.another.com.
IN TXT "v=spf1 mx -all"
ns1 IN A 192.168.0.1
www IN A 192.168.0.2
ftp IN CNAME www.example.com.
bill IN A 192.168.0.3
fred IN A 192.168.0.4
Atividade
O objetivo é montar a seguinte estrutura:

Vamos configurar e testar um servidor DNS. Para tanto montaremos a estrutura indicada no diagrama, onde cada máquina será um servidor DNS, com um domínio próprio e, ao mesmo tempo, será cliente do servidor DNS da máquina 192.168.2.101. Esta, por sua vez, será servidor um servidor master do domínio redes.edu.br e servidor escravo, recebendo automaticamente uma cópia das zonas dos servidores masters, de todos os demais domínios criados. Esta, será também a única máquina com servidor DNS com zona reversa. Sendo assim todos os domínios, diretos e reversos, serão visíveis por meio deste servidor.
- Entendendo o serviço DNS. Antes de qualquer reconfiguração faça testes usando a ferramenta “dig”:
dig -x 200.135.37.65; dig www.das.ufsc.br; dig +trace www.polito.it; dig @200.135.37.65 www.polito.it.
- Siga o roteiro da apostila e inicialize o servidor DNS, criando o domínio redesX.edu.br (onde X é o último dígito do ip de sua máquina). Por questões práticas, acima mencionadas, não crie zona reversa.
- O servidor DNS deverá responder pelos nomes: da própria máquina (etiqueta), www, ftp e mail, todos apontando para o mesmo IP.
- No /etc/resolv.conf declare nameserver 192.168.2.101.
- Faça testes “pingando” nos nomes, ex:
ping www.redes4.edu.br ping m4.redes4.edu.br ping www.redes3.edu.br
- Teste o DNS reverso.
- Faça testes usando a ferramenta “dig”:
dig -x número.do.ip dig maquina.dominio.extensao.br; dig +trace maquina.dominio.extensao.br; dig @servidor.de.nomes maquina.dominio.extensao.br.
12/04: DNS
Será feita a atividade da aula de 08/04.
Na aula se mostrou como configurar um servidor DNS básico, que responde por um domínio. Em seguida, foi configurado o servidor DNS do computador do professor, que tem IP 192.168.2.101, para ser escravo (ou secundário) de todos os domínios criados pelos alunos. Para isto, foram necessárias estas modificações:
- Nos servidores DNS master (nos computadores dos alunos):
- Modificar a seção da zona em /etc/bind/named.conf.default-zones para permitir que o servidor slave copie o conteúdo da zona. Exemplo para o domínio "redes2.edu.br":
zone "redes2.edu.br" { type master; file "/etc/bind/redes2.zone"; // abaixo fica autorizado que 192.168.2.101 copie o conteúdo da zona allow-transfer { 192.168.2.101; }; }; - Modificar o arquivo de zona para indicar que há agora mais um servidor DNS para o domínio. No caso de redes2.edu.br:
redes2.edu.br. IN SOA ns.redes2.edu.br. admin.redes2.edu.br. ( 2010041202; serial 3H ; refresh 60 ; retry 1W ; expire 3W ; minimum ) IN NS ns; este é o servidor master deste domínio IN NS ns.redes1.edu.br. ; este é um servidor slave (o computador do professor) IN MX 10 mail mail IN A 192.168.2.102 www IN A 192.168.2.102 ftp IN A 192.168.2.102 ns IN A 192.168.2.102 - Reiniciar o servidor DNS:
service bind9 restart
- Configurar o resolver DNS para usar o servidor DNS 192.168.2.101. Isto se faz modificando o arquivo /etc/resolv.conf:
nameserver 192.168.2.101
- Modificar a seção da zona em /etc/bind/named.conf.default-zones para permitir que o servidor slave copie o conteúdo da zona. Exemplo para o domínio "redes2.edu.br":
- No servidor DNS escravo (computador do professor):
- Acrescentar em /etc/bind/named.conf.default-zones uma seção para cada zona correspondente aos domínios dos alunos. Exemplo para redes2.edu.br:
zone "redes2.edu.br" { type slave; masters { 192.168.2.102; }; file "/etc/bind/redes2.zone"; }; - Reiniciar o servidor DNS
- Acrescentar em /etc/bind/named.conf.default-zones uma seção para cada zona correspondente aos domínios dos alunos. Exemplo para redes2.edu.br:
- Testar a nova configuração, usando o utilitário dig:
# Busca o registro SOA dig redes2.edu.br soa # Busca o registro A dig mail.redes2.edu.br a
Informações e dicas
- Para instalar o servidor DNS (software BIND):
sudo apt-get install -y bind9
- Para iniciar o servidor de nomes:
service bind9 restart
- Exemplo de arquivo /etc/bind/named.conf:
options { # The directory statement defines the name server's working directory directory "/var/cache/bind"; # Write dump and statistics file to the log subdirectory. The # pathnames are relative to the chroot jail. dump-file "/var/log/named_dump.db"; statistics-file "/var/log/named.stats"; # The forwarders record contains a list of servers to which queries # should be forwarded. Enable this line and modify the IP address to # your provider's name server. Up to three servers may be listed. #forwarders { 192.0.2.1; 192.0.2.2; }; # Enable the next entry to prefer usage of the name server declared in # the forwarders section. #forward first; # The listen-on record contains a list of local network interfaces to # listen on. Optionally the port can be specified. Default is to # listen on all interfaces found on your system. The default port is # 53. #listen-on port 53 { 127.0.0.1; }; # The listen-on-v6 record enables or disables listening on IPv6 # interfaces. Allowed values are 'any' and 'none' or a list of # addresses. listen-on-v6 { any; }; # The next three statements may be needed if a firewall stands between # the local server and the internet. #query-source address * port 53; #transfer-source * port 53; #notify-source * port 53; # The allow-query record contains a list of networks or IP addresses # to accept and deny queries from. The default is to allow queries # from all hosts. #allow-query { 127.0.0.1; }; # If notify is set to yes (default), notify messages are sent to other # name servers when the the zone data is changed. Instead of setting # a global 'notify' statement in the 'options' section, a separate # 'notify' can be added to each zone definition. notify no; }; zone "." in { type hint; file "root.hint"; }; zone "localhost" in { type master; file "localhost.zone"; }; zone "0.0.127.in-addr.arpa" in { type master; file "127.0.0.zone"; }; zone "ger.br" in { type master; file "ger.zone"; }; zone "xxx.ger.br" in { type slave; masters { 172.18.0.23;}; file "xxx.zone"; }; - Exemplo para uma zona DNS:
example.com. 86400 IN SOA ns1.example.com. hostmaster.example.com. ( 2002022401 ; serial 10800 ; refresh 15 ; retry 604800 ; expire 10800 ; minimum ) IN NS ns1.example.com. IN NS ns2.smokeyjoe.com. IN MX 10 mail.another.com. IN TXT "v=spf1 mx -all" ns1 IN A 192.168.0.1 www IN A 192.168.0.2 ftp IN CNAME www.example.com. bill IN A 192.168.0.3 fred IN A 192.168.0.4 - Utilitário para testar o arquivo que contém o conteúdo de uma zona:
# named-checkzone nome_do_dominio arquivo_da_zona # Assume que você esteja no diretório onde está o redes.zone named-checkzone redes.edu.br redes.zone
- Utilitário para testar a configuração do BIND:
# Assume que você esteja no diretório onde está o named.conf named-checkconf named.conf - Exemplo de arquivo /etc/resolv.conf (usado pelo resolver, que é o cliente DNS contido em todo software de rede):
search ger.br nameserver 192.168.1.100
- Exemplo de um programa que resolve nomes (age como cliente DNS):
#include<netdb.h> #include<string.h> #include<stdio.h> int main(int argc, char ** argv) { struct hostent * host; struct in_addr addr; if (argc < 2) { printf("Uso: %s nome_DNS\n", argv[0]); return 1; } host = gethostbyname(argv[1]); if (host != NULL) { memcpy(&addr, host->h_addr, sizeof(struct in_addr)); printf("%s tem endereço %s\n", argv[1], inet_ntoa(addr)); } else { printf("%s desconhecido !\n", argv[1]); } return 0; }
- Exemplo de um programa que faz consultas DNS em geral (registros A, NS, PTR, CNAME, MX, SOA). Para compilá-lo, faça gcc -o dns dns.c -lresolv.
15/04: DNS e DHCP
Finalização da aula sobre DNS, mostrando a delegação de subdomínios.
Delegando subdomínios
Basicamente há dois requisitos para a delegação de subdomínios (maiores detalhes neste livro online):
- No domínio acima na hierarquia deve haver registros NS indicando quem são os responsáveis pelo subdomínio:
ger.edu.br IN SOA ns.ger.edu.br. admin.ger.edu.br. ( 2010041401 1H 15M 1W 1H) IN NS ns IN NS ns.outrodominio.com.br. IN MX 10 mail ns IN A 192.168.2.101 mail IN A 192.168.2.101 ; ; Abaixo está a delegação do domínio rede2.ger.edu.br rede2 IN NS ns.rede1 ns.rede2 IN A 192.168.2.102 ; ; Abaixo está a delegação do domínio rede3.ger.edu.br rede3 IN NS ns.rede3 ns.rede3 IN A 192.168.2.103 - No servidor responsável pelo subdomínio deve estar hospedado o mapa DNS (ou zona) correspondente.
IMPORTANTE ! o servidor DNS do subdomínio deve estar ativo para que a consulta às informações do subdomínio sejam obtidas. Isto vale mesmo que a consulta seja somente sobre o registro NS do subdomínio que foi delegado. (foi isto que impediu de funcionar o experimento em aula ...).
DNS dinâmico
DHCP
DHCP (Dynamic Host Configuration Protocol) é um protocolo para obtenção automática de configuração de rede, usado por computadores que acessam fisicamente uma rede. Esses computadores são tipicamente máquinas de usuários, que podem usar a rede esporadicamente (ex: usuários ocm seus laptops, com acesso via rede cabeada ou sem-fio), ou mesmo computadores fixos da rede. O principal objetivo do DHCP é fornecer um endereço IP, a máscara de rede, o endereço IP do roteador default e um ou mais endereços de servidores DNS. Assim, um novo computador que acesse a rede pode obter essa configuração sem a intervenção do usuário.
Para esse serviço pode haver um ou mais servidores DHCP. Um computador que precise obter sua configuração de rede envia mensagens DHCPDISCOVER em broadcast para o port UDP 67. Um servidor DHCP, ao receber tais mensagens, responde com uma mensagem DHCPOFFER também em broadcast, contendo uma configuração de rede ofertada. O computador então envia novamente em broadcast uma mensagem DHCPREQUEST, requisitando o endereço IP ofertado pelo servidor. Finalmente, o servidor responde com uma mensagem DHCPACK, completando a configuração do computador cliente. Como a configuração tem um tempo de validade (chamado de lease time), o cliente deve periodicamente renová-la junto ao servidor DHCP, para poder continuar usando-a. O diagrama abaixo mostra simplificadamente esse comportamento:

Abaixo segue um diagrama de estados detalhado do DHCP, mostrando todas as possíveis transições do protocolo:

O servidor DHCP identifica cada cliente pelo seu endereço MAC. Assim, o DHCP está fortemente relacionado a redes locais IEEE 802.3 (Ethernet) e IEEE 802.11 (WiFi).
Servidor DHCP
Em nosso experimento será usado o servidor DHCP desenvolvido pelo ISC (o mesmo que fez o servidor DNS BIND). Para usá-lo devem-se seguir estes passos:
- Instalá-lo com este comando:
sudo apt-get install -y dhcp3-server
- Editar sua configuração, que está em /etc/dhcp3/dhcpd.conf. Definir as configurações globais e as redes onde o servidor DHCP irá ofertar endereços:
default-lease-time 600; max-lease-time 7200; option subnet-mask 255.255.255.0; option broadcast-address 192.168.2.255; option routers 192.168.2.101; option domain-name-servers 192.168.2.101, 192.168.2.101; option domain-name "ger.edu.br"; subnet 192.168.2.0 netmask 255.255.255.0 { range 192.168.2.10 192.168.2.100; range 192.168.2.150 192.168.2.200; } - Iniciar o servidor DHCP:
sudo service dhcp3-server start
Maiores detalhes sobre esse servidor DHCP:
- dhcpd - o servidor DHCP
- dhcpd.conf - o arquivo de configuração do DHCP
- Opções do protocolo DHCP
- dhclient - o cliente DHCP
Atividades
- DNS:
- Configure um subomínio DNS com nome redeX.ger.edu.br, sendo X o número do seu computador.
- Usando o utilitário dig investigue o subdomínio que você criou: verifique as informações sobre ele existentes no servidor ns.ger.edu.br e em seu próprio servidor.
- Assuma que exista um servidor DNS secundário (escravo) para seu subdomínio em ns.ger.edu.br (que tem IP 192.168.2.101).
- DHCP:
- Instale e configure um servidor DHCP. Ele deve fornecer endereços IP na faixa 192.168.2.Y a 192.168.2.(Y+9), com Y definido pela expressão Y = X*5+20 (X é o número do seu computador). As demais configurações de rede devem ser:
- Endereço de rede: 192.168.2.0
- Máscara: 255.255.255.0
- Roteador default: 192.168.2.101
- Servidores DNS: 192.168.2.101, 192.168.2.101
- Tempo de aluguel default: 120 segundos
- Tempo de aluguel máximo: 300 segundos
- Ative o serviço DHCP em seu computador
- Use o utilitário dhcping para testar seu servidor DHCP. Ele deve ser instalado com
sudo apt-get install -y dhcping
- Instale e configure um servidor DHCP. Ele deve fornecer endereços IP na faixa 192.168.2.Y a 192.168.2.(Y+9), com Y definido pela expressão Y = X*5+20 (X é o número do seu computador). As demais configurações de rede devem ser:
19/04: DNS e DHCP; Introdução a WWW
Pegue aqui a prova prática simulada...
- Realização das atividades sobre DHCP.
- Foi feita a demonstração da delegação de domínios, que falhou na aula anterior. Na verdade as configurações estava corretas, mas para fzaer os testes era necessário que os servidores DNS dos subdomínios estivessem também ativados.
DNS reverso
Foi apresentado um resumo sobre DNS reverso, que havia faltado nas aulas anteriores.
DNS reverso se refere ao mapeamento entre endereços IP e nomes DNS. O objetivo é possibilitar descobrir que nome DNS está associado a um determinado IP. Os parágrafos abaixo são uma tradução da seção da RFC 1033 que trata do domínio IN-ADDR.ARPA:
A estrutura de nomes no sistema de domínios é montada de forma hierárquica, de forma que o endereço de um nome possa
ser encontrado descendo-se a árvore de domínios, e contatando um servidor para cada rótulo que compõe esse nome. Devido a
essa "indexação" baseada no nome, não há uma maneira fácil de traduzir de volta um endereço de um host para seu
nome de host.
Para facilitar a tradução reversa, foi criado um domínio que usa endereços de hosts como parte de um nome que então
aponta para os dados aquele host. Assim, existe agora um "índice" para registros de hosts baseado em seus endereços.
Esse domínio para mapeamento de endereços se chama IN-ADDR.ARPA. Dentro desse domínio, há subdomínios para cada
subrede, baseados no número da rede. Além disto, para manter a consistência e os agrupamentos naturais, os quatro
octetos do endereço de um host são postos em ordem reversa.
Por exemplo, a ARPANET é a rede 10. Isto significa que existe um domínio 10.IN-ADDR.ARPA. Dentro desse domínio há um
registro PTR associado a 51.0.0.10.IN-ADDR.ARPA que aponta o nome SRI-NIC.ARPA (que possui o endereço 10.0.0.51).
Como esse host também está na rede MILNET (rede 26, com endereço 26.0.0.73), há também um registro PTR mapeando
73.0.0.26.IN-ADDR.ARPA para o mesmo nome SRI-NIC.ARPA. O formato desses ponteiros está definido abaixo,
junto com exemplos:
<special-name> [<ttl>] [<class>] PTR <name>
O registro PTR é usado para possibilitar que nomes especiais apontem para alguma outra localização na árvore de domínios.
Eles são usados principalmente nos registros do domínio IN-ADDR.ARPA para traduzir endereços para nomes. Registros PTR
deveriam usar nomes oficiais e não apelidos (nota do professor: CNAME, mas veja que no caso de DNS reverso para
CIDR isso é flexibilizado ...).
Por exemplo, o host SRI-NI.ARPA com endereço 10.0.0.51 e 26.0.0.73 possuiria os seguintes registros nos respectivos
arquivos de zona para as redes 10 e 26:
51.0.0.10.IN-ADDR.ARPA. PTR SRI-NIC.ARPA.
73.0.0.26.IN-ADDR.ARPA. PTR SRI-NIC.ARPA.
Assim, no BIND a configuração de um domínio reverso implicaria a definição de uma zona e seu arquivo com os registros PTR. Por exemplo, a zona reversa para a subrede 192.168.2.0/24 precisaria da seguinte declaração em /etc/bin/named.conf.default-zones:
zone "2.168.192.in-addr.arpa" {
type master;
file "/etc/bind/ger.revzone";
};
O arquivo /etc/bind/ger.revzone conteria os registros PTR:
@ IN SOA ns.ger.edu.br. admin.ger.edu.br. (
2010041901
1H
1W
15M
1H)
IN NS ns.ger.edu.br.
;
1 IN PTR mail.ger.edu.br.
2 IN PTR www.ger.edu.br.
3 IN PTR micro.ger.edu.br.
;
; demais registros PTR ... possivelmente até 254
Resolução IP classless
O esquema descrito para DNS reverso se ancora na escrita de endereços IP com 4 octetos, e na hierarquização de endereços IP. Assim, ele não funciona para subredes cujas máscaras de rede não estejam perfeitamente alinhadas com os octetos (apenas as máscaras 255.0.0.0, 255.255.0.0 e 255.255.255.0 satisfazem esse critério). No entanto, a definição do CIDR (Classless Inter-Domain Routing), em que pode haver subredes de outros tamanhos, tornou a resolução DNS incompatível com as novas subdivisões de redes que passaram a ser usadas. Por exemplo, as subredes 192.168.2.0/26, 192.168.2.64/26, 192.168.2.128/26 e 192.168.2.192/26 não podem ter seu DNS reverso configurado independentemente (ele deve ser configurado para a subrede 192.168.2.0/24, gerando uma dificuldade administrativa para mantê-lo). Para sanar essas dificuldades, a RFC 2317 propôs uma extensão ao esquema de mapeamento.
A proposta é criar subdomínios reversos que expressem as faixas de endereços IP das subredes, e delegá-los a seus servidores DNS. Assim, as subredes acima exemplificadas corresponderiam aos subdomínios:
0-63.2.168.192.in-addr.arpa. IN NS ns.rede1.com.br.
64-127.2.168.192.in-addr.arpa. IN NS ns.rede2.org.br.
128-191.2.168.192.in-addr.arpa. IN NS ns.rede3.com.br.
192-255.2.168.192.in-addr.arpa. IN NS ns.rede4.edu.br.
Note que esses subdomínios estão contidos no domínio 2.168.192.in-addr.arpa. Em seguida é necessário criar um registro CNAME para cada possível endereço IP dessas subredes:
1 IN CNAME 1.0-63.2.168.192.in-addr.arpa.
2 IN CNAME 2.0-63.2.168.192.in-addr.arpa.
3 IN CNAME 3.0-63.2.168.192.in-addr.arpa.
; todos os IPs até ...
63 IN CNAME 63.0-63.2.168.192.in-addr.arpa.
; continua no IP 65 ...
65 IN CNAME 65.64-127.2.168.192.in-addr.arpa.
; ... até o IP 127
127 IN CNAME 127.64-127.2.168.192.in-addr.arpa.
; ... e assim por diante
Servidor web Apache
O servidor Apache (Apache server) é o mais bem sucedido servidor web livre. Foi criado em 1995 por Rob McCool, então funcionário do NCSA (National Center for Supercomputing Applications), Universidade de Illinois. Ele descende diretamente do NCSA httpd, um servidor web criado e mantido por essa organização. Seu nome vem justamente do reaproveitamento do NCSA httpd (e do fator de tê-lo tornado modular) fazendo um trocadilho com a expressão "a patchy httpd (um httpd remendável). Para ter ideia de sua popularidade, numa pesquisa realizada em dezembro de 2005 foi constatado que sua utilização supera 60% nos servidores ativos no mundo. O servidor é compatível com o protocolo HTTP versão 1.1. Suas funcionalidades são mantidas através de uma estrutura de módulos, podendo inclusive o usuário escrever seus próprios módulos — utilizando a API do software. É disponibilizado em versões para os sistemas Windows, Novell Netware, OS/2 e diversos outros do padrão POSIX (Unix, GNU/Linux, FreeBSD, etc).
Um servidor web é capaz de atender requisições para transferência de documentos. Essas requisições são feitas com o protocolo HTTP (HyperText Transfer Protocol), e se referem a documentos que podem ser de diferentes tipos. Uma requisição HTTP simples é mostrada abaixo:
GET / HTTP/1.1
Host: www.das.ufsc.br
A resposta a essa requisição pode ser:
HTTP/1.1 200 OK
Date: Sun, 18 Apr 2010 23:33:28 GMT
Server: Apache
Last-Modified: Thu, 27 Oct 2005 12:19:19 GMT
ETag: "70cdaf8395f06808ed756104ee1a95b5f74a3eb3"
Accept-Ranges: bytes
Content-Length: 108
Content-Type: text/html
<HTML><HEAD><meta http-equiv="REFRESH" content="0;
URL=http://www.das.ufsc.br/das/index.php"></HEAD></HTML>
Para o servidor Web, os principais componentes de uma requisição HTTP são o método HTTP a executar e o localizador do documento a ser retornado (chamado de URI - Uniform Resource Indicator). No exemplo acima, a requisição pede o método GET aplicado à URI /. O resultado é composto do status do atendimento, cabeçalhos informativos e o conteúdo da resposta. No exemplo, o status é a primeira linha (HTTP/1.1 200 OK), com os cabeçalhos logo a seguir. Os cabeçalhos terminam ao aparecer uma linha em branco, e em seguida vem o conteúdo (ou corpo) da resposta.
Todo documento possui um especificador de tipo de conteúdo, chamado de Internet media Type. O cabeçalho de resposta Content-type indica o media type, para que o cliente HTTP (usualmente um navegador web) saiba como processá-lo. No exemplo acima, o documento retornado é do tipo text/html, o que indica ser um texto HTML. Outros possíveis media types são: text/plain (texto simples), application/pdf (um texto PDF), application/x-gzip (um conteúdo compactado com gzip).
Um documento no contexto do servidor web é qualquer conteúdo que pode ser retornado como resposta a uma requisição HTTP. No caso mais simples, um documento corresponde a um arquivo em disco, mas também podem ser gerados dinamicamente. Existem diversas tecnologias para gerar documentos, tais como PHP, JSP, ASP, CGI, Python, Perl, Ruby, e possivelmente outras. Todas se caracterizam por uma linguagem de programação integrada intimamente ao servidor web, obtendo dele informação sobre como gerar o conteúdo da resposta. Atualmente, boa parte dos documentos que compõem um site web são gerados dinamicamente, sendo PHP, JSP e ASP as tecnologias mais usadas.
22/04: 2a avaliação
26/04: WWW
Ver capítulo 26 da apostila.
Continuação sobre WWW e o servidor Apache.
Informações gerais sobre Apache no Ubuntu
- Instalação:
sudo apt-get install apache2
- Arquivos de configuração ficam em /etc/apache2:
- apache2.conf: a configuração inicia aqui
- Diretório sites-available: configurações de hosts virtuais
- Diretório sites-enabled: hosts virtuais atualmente ativados
- Para iniciar o Apache:
sudo service apache2 start
- Para testar o Apache: com um navegador acesse a URL http://192.168.2.X/ (X é 102 para o micro 2, 103 para o 3, e assim por diante).
Uma configuração básica
O servidor Apache precisa de algumas informações básicas para poder ativar um site:
- Qual seu nome de servidor: seu nome DNS , como www.sj.ifsc.edu.br
- Em que portas ele atende requisições: as portas TCP onde ele recebe requisições HTTP. Por default é a porta 80, mas outras portas podem ser especificadas.
- Onde estão os documentos que compõem o site hospedado: o caminho do diretório onde estão esses documentos
- Quem pode acessar os documentos: restrições baseadas em endereços IP de clientes e/ou nomes de usuários e grupos.
No exemplo abaixo, define-se um servidor WWW chamado www.ger.edu.br, que atende requisições nos ports 80 e 443:
# O nome de servidor
ServerName www.ger.edu.br
# As portas onde se atendem requisições HTTP
Listen 80 443
# Onde estão os documentos desse site
DocumentRoot /var/www/ger
# As restrições de acesso aos documentos
<Directory /var/www/ger>
Options Indexes
DirectoryIndex index.html index.php
order allow,deny
allow from all
</Directory>
Além dessas configurações, diversas outras se referem a opções do Apache, tais como modos de operação, identificação de tipos de documentos, extensões (funcionalidades) suportadas, e outras. Usualmente essas configurações já estão definidas de forma conveniente no arquivo de configuração do Apache.
Atividades
- Instale o servidor Apache
- Execute o Apache, usando o comando:
sudo service apache2 start
- Acesse seu servidor Apache, usando a URL http://IP_da_máquina_virtual/
- No seu domínio DNS redeX.ger.edu.br (X é o número do seu computador), adicione um registro A para www, associando-o ao IP de sua máquina virtual. Crie também um registro A para o nome webmail, associando-o ao mesmo IP.
29/04: WWW
Continuação sobre o Apache.
Referência: guia de diretivas do Apache.
Mais sobre restrições de acesso
Um servidor Web típico deve suportar em sua configuração a especificação de que requisições HTTP ele é capaz de atender. Isto inclui o nome do servidor (ex: www.das.ufsc.br), e as localizações dos documentos que ele pode retornar, assim como restrições de acesso a esses documentos. No caso do servidor Apache, a configuração reside em arquivos contidos no diretório /etc/apache2. Toda a configuração é feita por meio de diretivas, que são válidas para determinados escopos. Escopos correspondem aos conjuntos de documentos para os quais se aplica, e pode ser um diretório (que contém arquivos que correspondem a documentos), ou uma localização (que corresponde a uma determinada URI). Como os documentos se organizam de forma parecida com diretórios, os escopos também são hierárquicos. Isto significa que a configuração contida em um escopo é válida para todos os escopos abaixo dele, a não ser naqueles onde ela é redefinida. Por exemplo, no arquivo /etc/apache2/sites-enabled/000-default (que especifica a configuração do site default) há o seguinte escopo:
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
Ele indica que o escopo / (diretório raiz) tem como opção habilitada somente FollowSymLinks ("siga links simbólicos"), e para fins de controle de acesso não permite nenhuma modificação. Assim, todos os diretórios abaixo desse terão as mesmas restrições, a não ser que um novo escopo mais específico seja definido. De fato, nesse arquivo de configuração há outros escopos:
<Directory /var/www/>
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order allow,deny
allow from all
</Directory>
Esse novo escopo se aplica ao diretório /var/www, adicionando algumas opções e modificando as restrições de acesso (permite o acesso de todos). Uma configuração semelhante, porém baseada na URI, segue abaixo:
<Location /docs>
Options Indexes -FollowSymLinks
AllowOverride None
Order allow,deny
allow from 192.168.2.0/24
</Location>
Veja que ela se aplica a URI /docs. Assim, todas as URIs abaixo de /docs estão sujeitas às restrições ali definidas.
Hosts virtuais
Há muitos recursos no servidor Apache, que estão descritos em profundidade em sua documentação. Além da lista de diretivas, seguem abaixo alguns que merecem uma olhada:
- Hosts virtuais (Virtual Hosts)
- Autenticação e controle de acesso
- Suporte a redirecionamentos
- Expressões regulares
- Filtros
- Ativação de extensões
- Associação de plugins e extensões a mime-types
Dentre essas, Hosts virtuais tem largo uso porque possibilita que um mesmo servidor Apache hospede de forma independente diferentes sites. Cada site atende por um diferente nome de servidor (ServerName na terminologia do Apache), que corresponde ao seu nome DNS . Por exemplo, www.sj.ifsc.edu.br, webmail.sj.ifsc.edu.br são hosts virtuais hospedados no mesmo servidor Apache que fica no servidor hendrix.sj.ifsc.edu.br (verifique a resolução DNS desses nomes com o utilitário 'dig).
Um host virtual define a configuração de um site. Essa configuração fica sendo exclusiva desse site, e portanto não interfere (nem é interferida) pelas configurações de outras hosts virtuais. No entanto, tudo o que foi definido para o site global vale para os hosts virtuais, a não ser que neles seja redefinido. Assim, o exemplo anterior para o site www.ger.edu.br poderia estar dentro de um host virtual:
<VirtualHost *:80>
# O nome de servidor
ServerName www.ger.edu.br
# Onde estão os documentos desse site
DocumentRoot /var/www/ger
# As restrições de acesso aos documentos
<Directory /var/www/ger>
Options Indexes
DirectoryIndex index.html index.php
order allow,deny
allow from all
</Directory>
</VirtualHost>
Módulos
Módulos estendem a funcionalidade do Apache, e podem ser ativados ou desativados em sua configuração. Módulos são ativados com a diretiva LoadModule:
LoadModule php5_module /usr/lib/apache2/modules/libphp5.so
Alguns módulos muito usados são:
- PHP (Personal Homepage): uma linguagem de programação voltada para a criação de páginas dinâmicas. Para disponibilizá-la deve-se instalar o pacote com o módulo php5: Para testá-lo crie um arquivo chamado teste.php com o conteúdo abaixo, e coloque-o no DocumentRoot do seu site:
sudo apt-get install -y php5
<?php echo "Hello world"; ?>
- SSL (Secure Socket Layer): provê o acesso a página com sigilo e autenticação baseada em certificados digitais.
- Rewrite: possibilita manipular URLs e URIs por meio de expressões regulares.
- ... e muitos outros: ver no site oficial do Apache.
Atividades
- Crie hosts virtuais para www.redeX.ger.edu.br e webmail.redeX.ger.edu.br. Esses hosts virtuais deve ter como DocumentRoot respectivamente os diretórios /var/www/novo e /var/www/webmail.
- Teste o acesso ao seu novo servidor WWW, usando as URLs http://www.redeX.ger.edu.br/ e http://webmail.redeX.ger.edu.br/ .
- Restrinja o acesso ao novo servidor WWW a pessoas autorizadas. Essas pessoas devem se autenticar, fornecendo um usuário e senha. Para isto, algumas diretivas devem ser adicionadas:
AuthType Basic AuthName "Acesso Restrito" AuthUserFile /etc/apache2/senhas Require user aluno
Além disto, o arquivo de senhas precisa ser criado:htpasswd -c -s /etc/apache2/senhas usuario
- Modifique a restrição acima para que ela seja aplicada somente aos acessos a URI /docs.
- Ative o módulo PHP5. Instale-o com:
sudo apt-get install -y php5
... e em seguida teste-o criando uma página de nome index.php, com o seguinte conteúdo:<?php for ($i=0; $i < 10; $i++) { echo $i . ": Funcionou ?<br>"; } ?>
03/05: Email
Ver capítulo 27 da apostila.
O correio eletrônico (email) é um dos principais serviços na Internet. De fato foi o primeiro serviço a ser usado em larga escala. Trata-se de um método para intercâmbio de mensagens digitais. Os sistemas de correio eletrônico se baseiam em um modelo armazena-e-encaminha (store-and-forward) em que os servidores de email aceitam, encaminham, entregam e armazenam mensagens de usuários.
Uma mensagem de correio eletrônico se divide em duas partes:
- Cabeçalhos: contém informações de controle e atributos da mensagem
- Corpo: o conteúdo da mensagem
Received: from zeus.das.ufsc.br (zeus.das.ufsc.br [150.162.12.8])
by mx.google.com with ESMTP id e12si8422753vcx.66.2010.04.25.07.40.18;
Sun, 25 Apr 2010 07:40:19 -0700 (PDT)
Received: from submissoes.sbc.org.br (submissoes.sbc.org.br [143.54.31.12])
by zeus.das.ufsc.br (Departamento de Automacao e Sistemas (DAS-UFSC)) with ESMTP id BA97E7BD90
for <tele@ifsc.edu.br>; Sun, 25 Apr 2010 11:30:00 -0300 (BRT)
Received: from submissoes.sbc.org.br (localhost [127.0.0.1])
by submissoes.sbc.org.br (8.14.3/8.14.3/Debian-4) with ESMTP id o3PEZ70L029107
for <tele@ifsc.edu.br>; Sun, 25 Apr 2010 11:35:07 -0300
Received: (from www-data@localhost)
by submissoes.sbc.org.br (8.14.3/8.14.3/Submit) id o3PEZ7kH029104;
Sun, 25 Apr 2010 11:35:07 -0300
Date: Sun, 25 Apr 2010 11:35:07 -0300
Message-Id: <201004251435.o3PEZ7kH029104@submissoes.sbc.org.br>
From: WTR 2010 <lbecker@das.ufsc.br>
To: "Telê Santana" <tele@ifsc.edu.br>
Subject: Final version and registration
MIME-Version: 1.0
Content-Type: text/plain
Content-Transfer-Encoding: 8bit
Dear Coach,
Please remember to upload the camera-ready version of your paper and to
register in the competition by April 27.
See you in Spain,
FIFA World Cup Staff - Spain - 1982
Na mensagem acima, os cabeçalhos são as linhas iniciais. Os cabeçalhos terminam quando aparece uma linha em branco, a partir de que começa o corpo da mensagem.
Funcionamento do email
Os componentes da infraestrutura de email são:
- MUA (Mail User Agent): o aplicativo que o usuário usa para envio e acesso a mensagens. Atualmente é bastante comum MUA do tipo webmail, mas existem outros como Mozilla Thunderbird, KMail e Microsoft Outlook.
- MDA (Mail Delivery Agent): o servidor responsável por receber dos usuários mensagens a serem enviadas. Assim, quando um usuário quer enviar uma mensagem, usa um MUA que contata o MDA para fazer o envio. Exemplos de software são Postfix, Sendmail, Qmail e Microsoft Exchange.
- MTA (Mail Transport Agent): o servidor responsável por transmitir mensagens até seu destino, e receber mensagens da rede para seus usuários. Comumente faz também o papel de MDA. Exemplos de softwares são Postfix, Sendmail, Qmail e Microsoft Exchange.
A figura abaixo ilustra uma infraestrutura de email típica.

Os protocolos envolvidos são:
- SMTP (Simple Mail Transfer Protocol): usado para envios de mensagens entre MTAs, e entre MUA e MDA/MTA.
- IMAP (Internet Mail Access Protocol): usado por MUAs para acesso a mensagens armazenadas em caixas de email em servidores.
- POP (Post Office Protocol): mesma finalidade que IMAP, porém com funcionalidade mais limitada. Se destina a situações em que o normal é copiar as mensagens parao computador do usuário, e então removê-las do servidor.
- LMTP (Local Mail Transfer Protocol): usado para entrega de mensagens entre MTA e MDA/MTA, sendo que o servidor de destino não mantém uma fila de mensagens (quer dizer, ele entrega diretamente na caixa de entrada de um usuário ou a encaminha imediatamente).
Endereçamento
Endereços de email estão intimamente ligados ao DNS. Cada usuário de email possui um endereço único mundial, definido por um identificador de usuário e um domínio de email, escritos usando-se o símbolo especial @ (lê-se at, do original em inglês) para conectá-los:
tele@ifsc.edu.br
Nesse exemplo, o identificador de usuário é tele, e o domínio é ifsc.edu.br.
Os domínios de email tem correspondência direta com domínios DNS. De fato, para criar um domínio de email deve-se primeiro criá-lo no DNS. Além disto, o domínio DNS deve ter associado a si um ou mais registros MX (Mail exchanger) para apontar os MTAs responsáveis por receber emails para o domínio. Por exemplo, o domínio DNS ifsc.edu.br possui esse registro MX:
> dig ifsc.edu.br mx
;; QUESTION SECTION:
;ifsc.edu.br. IN MX
;; ANSWER SECTION:
ifsc.edu.br. 3581 IN MX 5 hermes.ifsc.edu.br.
... e o domínio gmail.com:
> dig gmail.com mx
;; QUESTION SECTION:
;gmail.com. IN MX
;; ANSWER SECTION:
gmail.com. 3600 IN MX 20 alt2.gmail-smtp-in.l.google.com.
gmail.com. 3600 IN MX 30 alt3.gmail-smtp-in.l.google.com.
gmail.com. 3600 IN MX 40 alt4.gmail-smtp-in.l.google.com.
gmail.com. 3600 IN MX 5 gmail-smtp-in.l.google.com.
gmail.com. 3600 IN MX 10 alt1.gmail-smtp-in.l.google.com.
MTA Postfix
O primeiro software MTA usado em larga escala na Internet foi o sendmail. Esse MTA possui muitas funcionalidades, e enfatiza a felxibilidade em sua configuração. No entanto, configurá-lo e ajustá-lo não é tarefa fácil. Além disto, houve vários problemas de segurança no passado envolvendo esse software. Assim outras propostas surgiram, como qmail e postfix. Tanto qmail quanto postfix nasceram como projetos preocupados com a segurança nas operações de um MTA, e também se apresentaram como MTAs mais simples de configurar e operar. Em nossas aulas será usado o postfix, mas recomenda-se experimentar usar as outras duas opcões citadas.
O postfix é um MTA modularizado, que divide as tarefas de processamento das mensagens em diversos componentes que rodam como processos separados. Isto difere bastante do sendmail, que se apresenta como um software monolítico. No postfix, um conjunto de subsistemas cuida de processar cada etapa da recepção ou envio de uma mensagem, como mostrado na figura abaixo:

Configuração
A configuração do postfix é armazenada em arquivos, que normalmente residem no diretório /etc/postfix. Os dois principais são:
- master.cf: configurações para execução dos subsistemas do Postfix (define que subsistemas estão ativados, quantas instâncias rodar de cada um, e seus argumentos de execução)
- main.cf: configurações usadas pelos subsistemas
No Ubuntu deve-se iniciar o uso do Postfix com esses comandos:
sudo apt-get install -y postfix
# O comando abaixo deve ser usado se o postfix já foi instalado, mas deseja-se recriar sua configuração
sudo dpkg-reconfigure postfix
As configurações iniciais informadas na instalação são suficientes para que o postfix possa ser iniciado. No entanto muitos detalhes provavelmente precisarão ser ajustados para que ele opere como desejado.
Para um rápido teste do postfix pode-se fazer a sequência abaixo:
> sudo service postfix restart
> telnet localhost 25
220 ger ESMTP postfix (Ubuntu)
helo mail
250 ger
mail from: msobral@gmail.com
250 2.1.0 OK
rcpt to: postmaster@ger.edu.br
250 2.1.5 OK
data
354 End data with <CR><LF>.<CR><LF>
subject: Teste
blabla
.
250 2.0.0 OK: queued as 71259CCA3
quit
221 2.0.0 Bye
Connection closed by foreign host
>
O resultado do teste (a mensagem entreguepara o usuário postmaster) pode ser visto no arquivo de log do postfix. No Ubuntu esse arquivo é /var/log/mail.log :
> tail /var/log/mail.log
May 2 17:29:42 ger postfix/smtpd[1965]: 71259CCA3: client=localhost[127.0.0.1]
May 2 17:30:48 ger postfix/cleanup[1970]: 71259CCA3: message-id=<20100502202942.71259CCA3@ger>
May 2 17:30:48 ger postfix/qmgr[1894]: 71259CCA3: from=<msobral@gmail.com>, size=323, nrcpt=1 (queue active)
May 2 17:30:48 ger postfix/local[1972]: 71259CCA3: to=<root@ger.edu.br>, orig_to=<postmaster@ger.edu.br>, relay=local, delay=102, delays=102/0.05/0/0.03, dsn=2.0.0, status=sent (delivered to mailbox)
May 2 17:30:48 ger postfix/qmgr[1894]: 71259CCA3: removed
May 2 17:31:25 ger postfix/smtpd[1965]: disconnect from localhost[127.0.0.1]
>
A mensagem de teste foi entregue em /var/mail/root:
> sudo cat /var/mail/root
From msobral@gmail.com Sun May 2 17:30:48 2010
Return-Path: <msobral@gmail.com>
X-Original-To: postmaster@ger.edu.br
Delivered-To: postmaster@ger.edu.br
Received: from mail (localhost [127.0.0.1])
by ger (Postfix) with SMTP id 71259CCA3
for <postmaster@ger.edu.br>; Sun, 2 May 2010 17:29:06 -0300 (BRT)
Subject: teste
Message-Id: <20100502202942.71259CCA3@ger>
Date: Sun, 2 May 2010 17:29:06 -0300 (BRT)
From: msobral@gmail.com
To: undisclosed-recipients:;
blabla
Atividades
- Instale o postfix em sua máquina virtual. Configure-o para que se comunicar na Internet, criando o domínio de email redeX.ger.edu.br (ou redeX.prova.br), sendo X o número do seu computador.
- Teste o funcionamento do postfix, enviando um email para postmaster@redeX.ger.edu.br.
- Teste o envio de mensagens para os domínios de seus colegas. Acompanhe o processamento das mensagens olhando o log do postfix.
- Tente usar o servidor SMTP de seu colega para enviar uma mensagem para o domínio de um terceiro colega.
- Edite a configuração do postfix (arquivo /etc/postfix/main.cf), de forma a negar receber mensagens vindas de clientes sem DNS reverso, ou com domínio de email de remetente desconhecido. Dica: ver a documentação oficial do postfix. Solução vista em aula: adicionar as seguintes linhas a /etc/postfix/main.cf:
smtpd_recipient_restrictions = # rejeita domínio DNS do remetente desconhecido reject_unknown_sender_domain permit_mynetworks # a restrição abaixo serve para restringir o uso deste MTA como relay reject_unauth_destination # rejeita clientes sem DNS reverso reject_unknown_client
06/05: Email
Atenção para vários problemas comuns na implantação do correio eletrônico:
- Domínio DNS sem registro MX: sem isso os MTAs não sabem como enviar mensagens para esse domínio
- Registro MX aponta um nome de host desconhecido: causa o mesmo problema acima
- Nome de host configurado como localhost no Postfix: o nome de host (parâmetro myhostname em /etc/postfix/main.cf) deve ser o nome DNS do servidor onde roda o Postfix.
- Erros de configuração (sintaxe) em /etc/postfix/main.cf: tais erros podem fazer com que um dos subsistemas do Postfix aborte sua execução, impedindo que se processe uma mensagem. Por exemplo, se um parâmetro usado pelo subsistema smtpd (que recebe mensagens com protocolo SMTP) estiver errado, o smtpd não iniciam, ou termina abruptamente, abortando a recepção de mensagens.
Atividades
- Realizar as atividades da aula de 03/05
10/05: Email
MDA Dovecot
Dovecot é um MDA de fácil instalação que suporta acessos com IMAP e POP3. As caixas de entrada podem ser armazenadas nos formatos mailbox ou Maildir.
Para instalar o Dovecot:
sudo apt-get install -y dovecot-imapd dovecot-pop3d
Configuração fica no arquivo /etc/dovecot/dovecot.conf. Algumas opções de configuração importantes:
protocols = pop3 pop3s imap imaps
pop3_uidl_format = %08Xu%08Xv
mail_location = maildir:~/Maildir
A caixa de entrada de cada usuário precisa ser criada da seguinte forma:
sudo maildirmake.dovecot /home/USUARIO/Maildir
sudo maildirmake.dovecot /home/USUARIO/Maildir/.Drafts
sudo maildirmake.dovecot /home/USUARIO/Maildir/.Sent
sudo maildirmake.dovecot /home/USUARIO/Maildir/.Trash
sudo maildirmake.dovecot /home/USUARIO/Maildir/.Templates
chown -R USUARIO /home/USUARIO/Maildir
chmod -R go-rwx /home/USUARIO/Maildir
O MTA precisa ser modificado para gravar as mensagens em formato Maildir. Assim, deve-se adicionar a seguinte linha a /etc/postfix/main.cf:
home_mailbox = Maildir/
Para iniciar o Dovecot:
service dovecot start
Webmail
Webmail é um MUA baseado em web, portanto acessível com um navegador. A popularização dos webmails se deu pela facilidade de uso, pois dispensam a instalação de um software MUA em computadores de usuários. Existem atualmente diversos webmail disponíveis, tais como:
- IMP e MIMP, sua versão com Ajax (Asynchronous Javscript Programming)
- Squirrelmail
- Roundcube, também baseado em Ajax.
- ... e outros (ver o verbete webmail na Wikipedia)
A grande maioria dos webmails usam o protocolo IMAP para acessarem as caixas de email de usuários. Algumas exceções são Uebimiau, projeto de webmail brasileiro que usa também POP3, e SqWebMail, que acessa diretamente as caixas de entrada em disco.
Os webmails são desenvolvidos em uma linguagem de programação para web, tal como PHP e Java, e usualmente precisam de uma infraestrutura de software para poderem funcionar. Essa estrutura é composta de um servidor web com suporte à linguagem de programação do webmail (ex: Apache com extensão PHP), um banco de dados (ex: MySQL, PostgreSQL ou Sqlite), um servidor IMAP com acesso às caixas de email de usuários, e um MTA para envio de mensagens.
Uma tela do Roundcube:

Atividades
- Instalar o Dovecot, e usá-lo para acessar a caixa de entrada e pastas IMAP.
- Instalar um webmail para acessar seu servidor IMAP. Sugestões: Roundcube, MIMP, IMP, Squirrelmail. Note que serão necessários diversos outros softwares como requisitos para esses webmails. Essas informações estão disponíveis nos sites desses softwares, e no arquivo INSTALL incluído nos pacotes de instalação (arquivos compactados contendo o código fonte).
13/05: LDAP
Ver documentação oficial do projeto Openldap.
LDAP (Lightweight Directory Access Protocol) é um protocolo de acesso a um serviço de diretório. Um diretório é um banco de dados hierárquico especificamente projetado para busca e navegação, além das funções básicas de localização e atualização. Diretórios costumam possuir informações definidas por atributos, e suportam mecanismos de filtragem sofisticados. Sem implementar as operações complexas encontradas em um banco de dados típico, diretórios costumam ser ajustados para prover respostas rápidas a operações de busca ou localização de grande volume. Para aumentar a disponibilidade e robustez, pode haver a replicação e distribuição das informações.
Como se vê, um serviço de diretório engloba novos conceitos e elementos em sua composição. Dentre os serviços já estudados, DNS é um tipo de diretório, e possui características como as descritas acima. No entanto, DNS foi criado com o propósito específico de prover um esquema de nomeação de hosts e serviços na Internet. LDAP, por outro lado, se apresenta como um diretório de uso geral, onde se podem guardar informações de qualquer natureza, e ser usado para qualquer finalidade.
Sendo um diretório, uma base de dados LDAP contém um conjunto de informações organizadas em árvore. O exemplo abaixo demonstra uma parte de uma possível árvore LDAP:

Dentro do LDAP as informações são modeladas com objetos que possuem um conjunto de atributos. Os diferentes tipos de objetos são definidos por um atributo especial chamado objectClass. Cada objectClass define que atributos deve possuir um objeto, incluindo atributos obrigatórios e opcionais. A isso se chama schema da base LDAP, sendo uma parte importante de sua implantação. Existem vários schemas predefinidos e padronizados, que são incluídos nos softwares que implementam o LDAP. Um exemplo de objectClass segue abaixo:
dn: uid=msobral,ou=People,dc=sj,dc=cefetsc,dc=edu,dc=br
objectClass: top
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: shadowAccount
objectClass: sambaSamAccount
cn: MARCELO MAIA SOBRAL
sn: msobral
uid: msobral
uidNumber: 3100
gidNumber: 500
homeDirectory: /home/professores/msobral
loginShell: /bin/bash
gecos: MARCELO MAIA SOBRAL
description: MARCELO MAIA SOBRAL
sambaLogonTime: 0
sambaLogoffTime: 2147483647
sambaKickoffTime: 2147483647
sambaPwdCanChange: 0
sambaPwdMustChange: 2147483647
displayName: MARCELO MAIA SOBRAL
sambaAcctFlags: [UX]
sambaSID: S-1-5-21-1612827373-3948523564-3779644005-7200
sambaPrimaryGroupSID: S-1-5-21-1612827373-3948523564-3779644005-2001
sambaProfilePath: \\DK\profiles\msobral
sambaHomePath: \\DK\msobral
sambaHomeDrive: H:
Esse objeto representa uma conta de usuário na rede IFSC. Como se pode ver, uma conta é descrita por diversos atributos, mostrados acima no formato:
nome_do_atributo: valor_do_atributo
Os vários atributos objectClass definem os schemas a serem aplicados a esse objeto. No caso, diferentes informações sobre um usuário para diferentes finalidades (identificação, conta Unix, conta Samba).
Cada objeto na base LDAP possui um localizador único, chamado Distinguished Name(ou simplesmente DN), e que funciona como o endereço do objeto dentro da base. O DN pode ser entendido também como o equivalente ao caminho do objeto na base, de forma similar ao caminho de um arquivo dentro de um sistema de arquivos. No objeto acima, seu DN aparece na primeira linha:
dn: uid=msobral,ou=People,dc=sj,dc=cefetsc,dc=edu,dc=br
Na terminologia LDAP, o objeto na base é chamado de entrada (entry). O DN se compõe do identificador da própria entrada (no exemplo, uid=msobral), concatenado aos identificadores das entradas antecessoras na árvore, até chegar à raiz (dc=br).
Outra entrada de uma base LDAP segue abaixo:
dn: cn=licenciatura,ou=Group,dc=sj,dc=cefetsc,dc=edu,dc=br
objectClass: posixGroup
cn: licenciatura
gidNumber: 1007
memberUid: divina
memberUid: mlucia
memberUid: anasch
Esse exemplo se refere a um grupo de usuários. Note a diferença no DN e no objectClass. Esse objeto possui assim um conjunto diferente de atributos, comparado ao objectClass posixAccount.
A principal aplicação LDAP é o armazenamento de informações administrativas em uma rede. Por exemplo, as contas de usuários, os grupos, apelidos de email (aliases), catálogos de endereços de email (address books), dentre outras informações. No caso particular de contas e grupos de usuários, o uso do LDAP proporciona a definição de contas distribuídas, que são válidas em todos os computadores que fazem parte de um domínio administrativo. Aqui no IFSC se usa o LDAP com esse propósito.
Pesquisando na base LDAP
Existe o utilitário ldapsearch para pesquisa na base LDAP. Para instalá-lo:
sudo apt-get install -y ldap-utils
Seu uso pode ser complexo, mas uma forma simples de utilizá-lo segue abaixo:
$ ldapsearch -x -h IP_servidor_LDAP atributo=valor
Ex: para obter o objeto do tipo conta de usuário mostrado anteriormente:
$ ldapsearch -x -h 172.18.0.1 -b dc=sj,dc=cefetsc,dc=edu,dc=br uid=msobral
... e para obter uma listagem de todos os grupos na base LDAP:
$ ldapsearch -x -h 172.18.0.1 -b dc=sj,dc=cefetsc,dc=edu,dc=br "objectClass=posixGroup"
OpenLDAP
OpenLDAP é uma implementação de código aberto de um servidor LDAP, junto com utilitários e bibliotecas. Para instalá-lo:
sudo apt-get install -y slapd ldap-utils ldapscripts libpam-ldap
Em seguida execute o seguinte procedimento:
- Edite os arquivos common-auth, common-account, common-password e common-session que estão em /etc/pam.d. Comente as linhas que se referem a pam_ldap.so e, na linha que menciona pam_unix.so certifique-se que success=1. Por exemplo, o arquivo common-auth deve ficar assim:
# here are the per-package modules (the "Primary" block) auth sufficient pam_unix.so nullok_secure auth [success=1 default=ignore] pam_ldap.so use_first_pass # here's the fallback if no module succeeds auth requisite pam_deny.so
- Faça o download da configuração do LDAP, e descompacte-a dentro de /etc/ldap. Modfique os arquivos init.ldif, slapd.conf e ldap.conf com os comandos (substitua X em redeX pelo número do seu computador):
sed s/dc=ger/dc=redeX,dc=ger/g init.ldif > x mv x init.ldif sed s/dc=ger/dc=redeX,dc=ger/g slapd.conf > x mv x slapd.conf sed s/dc=ger/dc=redeX,dc=ger/g ldap.conf > x mv x ldap.conf
- Pare o serviço slapd:
sudo service slapd stop
- Execute esse comando:
cd /etc/ldap mv slapd.d slapd.d.old - Edite /etc/default/slapd e certifique-se de que esta linha esteja assim:
SLAPD_CONF=/etc/ldap/slapd.conf
- Execute esses comandos dentro de /etc/ldap:
rm -rf /var/lib/ldap/* slapadd -v -l init.ldif chown -R openldap:openldap /var/lib/ldap
- Inicie o serviço slapd:
sudo service slapd start
- Teste se o LDAP está funcionando:
ldapsearch -x -b dc=redeX,dc=ger,dc=ifsc -h localhost
- Edite o arquivo /etc/ldapscripts/ldapscripts.conf para definir as informações sobre o acesso a base LDAP recém configurada.
- Adicione a senha de acesso à base LDAP, para que os scrits de ldapscripts consigam acessá-la:
echo -n teste > /etc/ldapscripts/ldapscripts.passwd - Crie uma conta de usuário:
ldapadduser um_usuario um_grupo
- Defina a senha desse usuário:
ldapsetpasswd um_usuario $(slappasswd -s uma_senha)
- Verifique o usuário criado:
ldapsearch -x -w teste -D "cn=admin,dc=ger,dc=ifsc" -h localhost uid=um_usuario
- Modifique o arquivo /etc/nsswitch.conf para que as linhas que se referem a paswd e group fique assim:
passwd files ldap group files ldap
- Edite o arquivo /etc/ldap.conf (configuração do cliente LDAP) e certifique-se de que ass seguintes linhas estarão dessa forma:
# The distinguished name of the search base. base dc=redeX,dc=ger,dc=ifsc # Another way to specify your LDAP server is to provide an uri ldap://localhost/ # The search scope. scope sub
- Teste se esse usuário pode ser visto como um usuário do Linux:
$ finger -m usuario Login: aluno Name: usuario Directory: /home/usuario Shell: /bin/bash Never logged in. No mail. No Plan.
Atividades
- Teste usar o servidor LDAP de um colega seu. As contas na base LDAP dele são visíveis no seu servidor ? O que mais eria necessário para que elas pudessem ser usadas normalmente (i.e o usuário pudesse selogar em qualquer computador em que ela fosse visível) ?
3a avaliação
A 3a avaliação será feita individualmente ou em duplas e fora do horário de aula. O prazo para entregá-la é 20/05.
Objetivo: instalar uma infraestrutura de correio eletrônico
Deve-se instalar uma infraestrutura de correio eletrônico composta por:
- MTA: um único MTA deve ser capaz de enviar mensagens para outros domínios de email e receber mensagens externas. Esse MTA deve aceitar fazer relay somente para os IPs contidos em seu domínio, ou para usuários autenticados. Mensagens vindas de clientes sem DNS reverso, com domínio de remetente desconhecido, ou incluídas em listas RBL e DNSBL devem ser rejeitadas. mensagens devem ser entregues para caixas de entrada no formato Maildir.
- MDA: possiblitar o acesso às mensagens com protocolos IMAP e POP3. Pode-se usar o Dovecot (recomendado), ou qualquer outro software que consigda acessar caixas de entrada no formato Maildir.
- MUA: usuários devem poder acessar o correio eletrônico tanto com um webmail quanto com um software específico (ex: Mozilla Thunderbird).
Note que serão necessários outros serviços:
- Software do webmail, podendo ser Roundcube, IMP, MIMP ou Squirrelmail.
- Servidor Web devidamente configurado para hospedar o webmail.
- Dependendo do modo de instalação do webmail, serão necessários outros softwares. A documentação do webmail escolhido contém os requisitos de instalação.
- Servidor DNS com as informações necessárias para o domínio de email implantado.
A instalação deve ser feita em uma máquina virtual. Na entrega do trabalho deve-se apresentá-lo ao professor, para que se possa verificar o correto funcionamento do correio eletrônico. Dev-se entregar um relatório de instalação que descreva a estrutura instalada, os softwares utilizados, e os procedimentos de instalação e configuração de todos os softwares.
17/05: LDAP
LDAP como base de dados administrativa
Uma base de dados administrativa do sistema contém informações necessárias para o acesso ao sistema (contas e grupos) e funcionamento de serviços (aliases de email, mapas de sistemas de arquivos do automounter), entre outros. Se essa base for implantada com arquivos, a informação nela contida vale somente para o sistema onde eles residem. No entanto, em uma rede de comutadores pode haver diversos servidores e estações de trabalho que devem funcionar em um mesmo domínio administrativo, compartilhando essas informações administrativas. Nesse caso, a base administrativa precisa residir em um repositório que possa ser acessado convenientemente por esses diferentes sistemas.
Serviços de diretório vêm sendo usados já faz algum tempo para implantar bases de dados administrativas, e isso não se limita ao mundo do Unix. No Windows, por exemplo, desde o Windows 2000 existe o Active Directory (AD) para guardar as informações do domínio Windows e que funciona como uma variação do LDAP. A Novell possui o Netware Directory Service (NDS). Em sistemas Unix, a Sun Microsystems lançou o uso do LDAP para esse propósito, o que foi seguido por outras variações do Unix (como o Linux).
Em sistemas Unix que seguem a especificação proposta pela Sun, a integração com o LDAP se faz com o auxílio do Pluggable Authentication Module (PAM) e Name Service Switch (NSS). PAM define um framework para autenticação e autorização, e NSS possibilita especificar de que fontes o sistema obtém informações administrativas. Assim, com PAM se pode indicar que as credenciais de um usuário devem ser verificadas de acordo com as informações contidas em uma base LDAP, e com NSS indica-se ao sistema que as informações de uma conta ou grupo devem ser também obtidas da base LDAP.
NSS e LDAP
As contas da base LDAP somente serão visíveis em um sistema após a correta configuração do NSS. O arquivo /etc/nsswitch.conf especifica as fontes de cada tipo de informação usada no Linux (e em outros Unix ...). Abaixo segue um exemplo de um arquivo nsswitch.conf típico:
passwd: compat
group: compat
shadow: compat
hosts: files mdns4_minimal [NOTFOUND=return] dns mdns4
networks: files
protocols: db files
services: db files
ethers: db files
rpc: db files
netgroup: nis
Na primeira coluna indica-se o tipo de informação, e nas demais colunas estão suas fontes:
- compat: guardadas nos arquivos tradicionais do Unix (/etc/passwd, /etc/group, ...), porém com compatibilidade com uma antiga sintaxe que possibilitava indicar no final do arquivo que mais informação deveria ser obtida de outras fontes (isso era usado no passado para usar o Network Information Service (NIS), um tipo de base de dados administrativa criado pela Sun Microsystems).
- files: guardadas nos arquivos tradicionais do Unix.
- db: guardadas em arquivos indexados usando Berkeley DB.
- nis: guardadas no NIS
- nis+: guardadas no NIS+ (um sucessor do NIS).
- ldap: guardadas no LDAP
- dns: obtidas no DNS
Para usar o LDAP como base de dados integrada ao NSS, foi definido o schema LDAP RFC 2307. Esseschema define os objectClass e atributos necessários para descrever contas, grupos, aliases, nomes de hosts, mapas automount e demais informações do NSS. Por exemplo, uma conta deve ser descrita da seguinte forma:
dn: uid=lester, dc=aja, dc=com
objectClass: top
objectClass: account
objectClass: posixAccount
uid: lester
cn: Lester the Nightfly
userPassword: {crypt}X5/DBrWPOQQaI
gecos: Lester
loginShell: /bin/csh
uidNumber: 10
gidNumber: 10
homeDirectory: /home/lester
... e um grupo seria assim:
dn: cn=tele,ou=Group,dc=sj,dc=cefetsc,dc=edu,dc=br
objectClass: posixGroup
objectClass: top
cn: tele
gidNumber: 32785
memberUid: alberto
memberUid: bau
Para se integrar o LDAP ao NSS, deve-se incluir a fonte ldap para todas as informações que irão ficar na base (pelo menos contas e grupos):
passwd: files ldap
group: files ldap
shadow: files ldap
# demais tipos de informações do NSS seguem abaixo ...
PAM e LDAP
No PAM há quatro serviços relacionados com autenticação e autorização:
- Autenticação: verifica as credenciais de um usuário (ex: senha)
- Account: confere a existência e validade de uma conta
- Password: efetua a modificação de credenciais (ex: mudança de senha)
- Session: para iniciar e terminar sessões de login (entrada no sistema)
A figura abaixo ilustra a arquitetura do PAM:

No Linux, a configuração do PAM se encontra no subdiretório /etc/pam.d (em outros sistemas, como o Solaris da Sun, ela fica toda no arquivo /etc/pam.conf). Nesse diretório há um arquivo para cada aplicativo que usa os serviços do PAM. Por exemplo, o servidor SSH possui a seguinte configuração PAM (arquivo /etc/pam.d/sshd):
# PAM configuration for the Secure Shell service
# Read environment variables from /etc/environment and
# /etc/security/pam_env.conf.
auth required pam_env.so # [1]
# In Debian 4.0 (etch), locale-related environment variables were moved to
# /etc/default/locale, so read that as well.
auth required pam_env.so envfile=/etc/default/locale
# Standard Un*x authentication.
@include common-auth
# Disallow non-root logins when /etc/nologin exists.
account required pam_nologin.so
# Uncomment and edit /etc/security/access.conf if you need to set complex
# access limits that are hard to express in sshd_config.
# account required pam_access.so
# Standard Un*x authorization.
@include common-account
# Standard Un*x session setup and teardown.
@include common-session
# Print the message of the day upon successful login.
session optional pam_motd.so # [1]
# Print the status of the user's mailbox upon successful login.
session optional pam_mail.so standard noenv # [1]
# Set up user limits from /etc/security/limits.conf.
session required pam_limits.so
# Standard Un*x password updating.
@include common-password
Cada linha da configuração PAM possui três informações:
- Coluna 1: O serviço PAM a que se refere
- Coluna 2: o status da configuração:
- required: obrigatória
- sufficient: obrigatória e, se for atendida, dispensa verificar as próximas configurações do mesmo serviço
- optional: não obrigatória (pode falhar)
- Coluna 3: o módulo PAM que a implementa
- Coluna 4: argumentos a serem passados ao módulo PAM (opcional)
Como muitas configurações são comuns aos diversos aplicativos que usam o PAM, existem comumente quatro arquivos onde essas são colocadas:
- common-auth
- common-account
- common-session
- common-password
Assim, esses arquivos podem ser incluídos na configuração PAM de um aplicativo:
@include common-auth
Para usar LDAP para autenticar usuários, é necessário primeiro que o NSS com LDAP esteja corretamente configurado. Em seguida, deve-se especificar que o módulo pam_ldap deve ser usado para autenticação. A forma mais fácil de fazer isso é incluí-lo no arquivo common-auth:
#
# /etc/pam.d/common-auth - authentication settings common to all services
#
auth required pam_env.so
auth sufficient pam_unix.so likeauth nullok
auth sufficient pam_ldap.so use_first_pass
auth required pam_deny.so
Atividades
- No computador do professor foi criada uma base LDAP com algumas contas e grupos. Configure o seu servidor para usar essa base como base administrativa. Teste a existência das contas operador e gerente, e do grupo ger.
- Tente se logar no seu servidor com essas contas. As senhas são, respectivamente, operador e gerente.
- Crie uma conta e um grupo em sua própria base LDAP. Use-a para acesso ao seu servidor.
- A administração da base LDAP pode ser feita muito mais facilmente usando uma ferramenta web. Instale e use a ferramenta PHPLdapAdmin para navegar e modificar informações na base LDAP. Obs: há um bug no PHPLdapAdmin do Ubuntu. Para corrigir o problema siga esse procedimento:
- Entre no diretório /usr/share/phpldadadmin.
- Faça o download desse patch.
- Execute:
$ patch -p0 < phpldapadmin.patch
- Aliases de email também podem ser guardados na base LDAP. Pesquise que schema deve ser usado, e como configurar o MTA Postfix para buscar os aliases no LDAP.
20/05: LDAP Replicas
Em uma instalação do LDAP, é de grande interesse ter mais de uma cópia ativa da base LDAP, chamada de replica. Assim evita-se a existência de um ponto simples de falha, além de se poder implementar balanceamento de carga entre as replicas. Em tal configuração, instalam-se dois ou mais servidores LDAP em diferentes computadores. Um dos servidores LDAP é o mestre, e os demais são os escravos. Modificações na base LDAP podem ser feitas somente no mestre, e são propagadas automaticamente para os escravos.
A configuração do escravo é idêntica à do mestre, porém possui essas diretivas adicionais:
# ponha essas diretivas depois de "database bdb"
database bdb
syncrepl rid=1
provider=ldap://192.168.1.11
type=refreshOnly
interval=00:00:05:00
searchbase="dc=ger,dc=ifsc"
filter="(objectClass=*)"
attrs="*"
scope=sub
schemachecking=off
bindmethod=simple
binddn="cn=admin,dc=ger,dc=ifsc"
credentials="teste"
updateref ldap://192.168.1.11
No mestre é necessário ativar a capacidade de prover atualizações para efeitos de sincronização da base com os escravos:
moduleload syncprov
# varias outras opcoes de configuracao ...
database bdb
# Adicionar a opcao abaixo
overlay syncprov
# mais opcoes de configuracao ...
Atividade
- Crie uma replica para sua base LDAP. Teste o acesso aos dados do escravo ... confira se são os mesmos do mestre.
- Faça o balanceamento de carga entre as replicas. Isto implica modificar /etc/ldap.conf da seguinte forma:
uri ldap://IP_do_mestre ldap://IP_do_escravo
- Teste o acesso transparente a ambas as replicas: pare o mestre e então tente acessar a base LDAP (use ldapsearch), depois reative o mestre e pare o escravo, repetindo o teste de acesso.
24/05: Servidor de arquivos
Um servidor de arquivos compartilha volumes (sistemas de arquivos) via rede. Para os computadores que acessam o servidor de arquivos, os volumes compartilhados parecem ser locais e se integram transparentemente às suas árvores de diretórios.
Um serviço de compartilhamento de sistema de arquivos possui algumas implicações:
- Segurança: o servidor de arquivos deve impor mecanismos para controle de acesso dos usuários remotos aos arquivos dos volumes compartilhados, de forma consistente com as restrições e direitos concedidos aos usuários locais. Para isso ser efetivo, torna-se necessário que os usuários da rede estejam definidos em um domínio administrativo.
- Desempenho: os acessos remotos aos arquivos são efetuados no nível de sistema de arquivos, o que significa que as transferências de dados são orientadas a blocos. Como a leitura e escrita de blocos se faz via mensagens na rede, há que cuidar para que o tamanho de blocos seja adequado para agilizar as transferências. Além disso, demais características no acesso ao sistema de arquivos remoto (atualização de atributos, gravação síncrona ou assíncrona) precisam ser ajustadas para reduzir os atrasos nas operações sobre arquivos e diretórios.
- Integridade de dados: sendo o sistema de arquivos remoto, e podendo ser acessado por mais de um cliente simultaneamente, são necessários mecanismos para evitar inconsistências dos dados vistos pelos diversos clientes. Outro detalhe a se cuidar trata de erros de transmissão e quedas ou interrupções momentâneas no servidor de arquivos.
Existem muitos tipos de sistemas de arquivos de rede, como NFS, Coda, Andrew FS, SMB/CIFS, porém nos concentraremos nos dois mais usados:
- NFS (Network File System): sistema de arquivos de rede nativo de muitos sistemas operacionais Unix
- SMB/CIFS (Service Message Block/Common Internet File System): mais conhecido como compartilhamento de arquivos e impressoras do Windows
NFS
NFS é um sistema de arquivos de rede criado pela Sun Microsystems em 1989, e descrito na RFC 1094. Seu uso predomina em sistemas operacionais Unix, porém há implementações para outras famílias de sistemas operacionais.
No NFS, um servidor compartilha um ou mais diretórios. Cada diretório compartilhado está sujeito a várias opções e restrições de acesso, como:
- clientes permitidos
- se são permitidos acessos como superusuário (root)
- se modificações são síncronas ou assíncronas
- protocolo de transporte usado (TCP ou UDP)
- tamanho de bloco para leitura ou escrita
- ... e outras
Um computador pode ser tanto servidor como cliente. Para o papel de servidor, uma tabela lista os diretórios a serem compartilhados e suas opções de compartilhamento. De forma geral, nos sistemas Unix essa tabela fica no arquivo /etc/exports, como neste exemplo:
# Compartilha /home para os computadores da rede 192.168.2.0/24, em modo leitura-escrita, porém sem acessos
# como superusuário. Modificações em modo assíncrono.
/home 192.168.2.0/24(rw,root_squash,async)
# Compartilha /home para os computadores da rede 192.168.2.0/24, em modo leitura-escrita, porém sem acessos
# como superusuário. Modificações em modo assíncrono. Porém para 192.168.2.101 se permitem acessos
# como superusuário.
/data 192.168.2.101(rw,no_root_squash) 192.168.2.0/24(rw,root_squash,async)
Para ter suporte ao serviço NFS, deve-se instalar o pacote nfs-kernel-server:
sudo apt-get install -y nfs-kernel-server
Após editar esse arquivo, deve-se atualizar o serviço NFS com o comando exportfs:
exportfs -r
Podem-se ver os diretórios exportados com o comando showmount:
showmount -e
Para o lado cliente, os sistemas de arquivos de rede a serem acessados são montados de forma semelhante a sistemas de arquivos locais (portanto, usando o comando mount e podendo ser incluídos em /etc/fstab):
# Monta o sistema de arquivos NFS IP_do_servidor:/home no ponto de montagem /home. Quer dizer,
# esse sistema de arquivos vai aparecer em /home. Usa blocos de 4kB para leitura e escrita.
$ mount -t nfs -o rsize=4096,wsize=4096,async IP_do_servidor:/home /home
Para que esse sistema de arquivos possa ser sempre montado quando o computador reiniciar, ele deve ser incluído em /etc/fstab:
IP_do_servidor:/home /home nfs rsize=4096,wsize=4096,async 0 0
Atividade
- Monte o diretório NFS /dados, que se encontra no servidor 192.168.2.101. Teste criar arquivos e diretórios.
- Compartilhe para a rede 192.168.2.0/24 o diretório /home de seu servidor, porém sem permitir acessos como superusuário. Use a outra máquina virtual para ser o cliente NFS, montando lá esse diretório.
Automounter
Em uma rede com muitos computadores que serão clientes NFS, torna-se pouco prático configurar cada computador individualmente para montar os sistemas de arquivos NFS. O serviço automounter possibilita a automação dessa tarefa, prtincipalmente se combinado ao LDAP. Inicialmente o automounter tinha como objetivo montar os sistemas de arquivos por demanda, e desmontá-los assim que não fossem mais necessários. Outra função do automounter era possibilitar montar um sistema de arquivos de uma lista de servidores, de forma a prover tolerância a falhas de servidores. Porém o automounter, se combinado a uma base de dados administrativa como LDAP (ou mesmo NIS e NIS+), ajuda a automatizar a montagem de sistemas de arquivos de forma homogênea nos clientes NFS, dispensando suas configurações individuais.
O automounter é um serviço que monta sistemas de arquivos de qualquer tipo automaticamente, de acordo com instruções contidas em seus mapas (automount maps). Esses mapas podem estar em arquivos ou na base LDAP. Em ambos os casos, os mapas são dividos em duas partes:
- Mapa mestre (auto.master): descreve os diretórios base onde devem ser montados os sistemas de arquivos e os nomes dos mapas de sistemas de arquivos correspondentes.
- Mapas de sistemas de arquivos: descrevem cada sistema de arquivos a ser montado.
No caso dos mapas estarem em arquivos, o mapa mestre fica em /etc/auto.master. Abaixo segue um auto.master de exemplo:
# diretório base, e mapa de sistemas de arquivos correspondente
/home2 /etc/auto.home
/dados /etc/auto.dados
Um mapa de sistema de arquivos contém cada sistema a ser montado, junto com opções de montagem. Por exemplo, o mapa /etc/auto.home poderia ser assim:
aluno -fstype=nfs,rsize=4096,wsize=4096,async server.ger.edu.br:/home/aluno
* -fstype=nfs,rsize=4096,wsize=4096,async server2.ger.edu.br:/home/&
'Para integrar automounter e LDAP (ver também esse guia do Ubuntu):
- Instale esses pacotes:
sudo apt-get install -y autofs autofs-ldap
- Edite /etc/ldap/slapd.conf, e adicione essa linha no início do arquivo:
include /etc/ldap/schema/autofs.schema
- Copie o seguinte conteúdo para um arquivo auto.ldif:
dn: ou=auto.master,dc=redeX,dc=ger,dc=ifsc objectClass: top objectClass: automountMap ou: auto.master dn: cn=/home2,ou=auto.master,dc=redeX,dc=ger,dc=ifsc objectClass: top objectClass: automount cn: /home2 automountinformation: ldap:192.168.2.X:ou=auto.home,dc=redeX,dc=ger,dc=ifsc dn: ou=auto.home,dc=redeX,dc=ger,dc=ifsc objectClass: top objectClass: automountMap ou: auto.home dn: cn=aluno,ou=auto.home,dc=redeX,dc=ger,dc=ifsc objectClass: top objectClass: automount cn: aluno automountinformation: -fstype=nfs,hard,intr,nodev,nosuid 192.168.2.X:/home/aluno
- Execute esses comandos para importar a informação acima à base LDAP:
service slapd stop slapadd -l auto.ldif service slapd start
- Edite o arquivo /etc/default/autofs, e certifique-se de que esses parâmetros estejam comfigurados corretamente:
TIMEOUT=300 DISABLE_DIRECT=1 LDAPURI=ldap://127.0.0.1 LDAPBASE="ou=auto.master,dc=redeX,dc=ger,dc=ifsc"
- Adicione esta linha a /etc/nsswitch.conf:
automount: files ldap
- Execute esses comandos, para corrigir a configuração do cliente LDAP:
cd /etc/ldap rm ldap.conf ln -s ../ldap.conf - Ative o serviço autofs:
service autofs start
- Teste se o automounter está funcionando, listando o diretório /home2/aluno. Em seguida, liste os sistemas de arquivos montados:
$ ls -l /home2/aluno $ mount
Assim como nos mapas na versão em arquivos, é possível criar uma entrada do tipo curinga em um mapa de sistemas de arquivos:
dn: cn=/,ou=auto.home,dc=redeX,dc=ger,dc=ifsc
objectClass: top
objectClass: automount
cn: /
automountinformation: -fstype=nfs,hard,intr,nodev,nosuid server.ger.edu.br:/home/&
Atividades
- Crie o mapa automounter em sua base LDAP, mapeando o diretório /home2 ao mapa de sistema de arquivos auto.home. Use entrada do tipo curinga.
- Teste o automounter, acessando os sistemas de arquivos que ele deve montar.
27/05: 3a avaliação
As equipes apresentaram os resultados do projeto da 3a avaliação.
31/05: Servidor de arquivos: Samba
Samba é originalmente uma implementação de código aberto para o serviço de compartilhamento de arquivos e impressoras do Microsoft Windows. Porém atualmente esse software evoluiu a tal ponto que pode ser usado como controlador de domínio Windows, além de possuir algumas funções e recursos não existentes no Windows (integração com Unix, flexibilidade de uso de diferentes bases administrativas, entre outros). Além de funcionar como um servidor, pode ter também papel de cliente e usar o serviço de autenticação de um servidor Windows. Seu uso se mostra razoavelmente simples, com complexidade proporcional à configuração desejada. Assim, Samba tem grande popularidade por possibilitar integrar os mundos do Windows e do Unix.
O Samba é dividido a grosso modo em duas partes principais:
- Servidor de arquivos, impressoras, e de autenticação (serviços SMB/CIFS): programa smbd
- Servidor de nomes WINS (Windows Name Service): programa nmbd
Esse software pode ser instalado tanto a partir do código-fonte, obtido no site oficial, quanto por pacote pre-compilado. No caso do Ubuntu, sua instalação pode ser feita assim:
sudo apt-get install -y samba samba4-clients smbfs
A configuração do Samba se faz por meio de arquivos, que normalmente ficam em /etc/samba. O principal deles se chama smb.conf, e uma configuração muito simplificada segue abaixo:
[global]
workgroup = GER
server string = Servidor %h (GER - IFSC)
; wins server = w.x.y.z
dns proxy = no
; name resolve order = lmhosts host wins bcast
; interfaces = 127.0.0.0/8 eth0
; bind interfaces only = yes
log file = /var/log/samba/log.%m
max log size = 1000
syslog = 0
encrypt passwords = true
passdb backend = tdbsam
obey pam restrictions = yes
map to guest = bad user
[homes]
comment = Lares dos usuarios
browseable = no
read only = no
create mask = 0700
directory mask = 0700
valid users = %S
Esse arquivo se organiza em seções. A seção [global] contém opções válidas globalmente, e as demais seções definem compartilhamentos e suas respectivas opções. Algumas seções são especiais, como '[homes], que corresponde aos diretórios home dos usuários.
Para usar a ferramenta de amdinistração web Swat:
- Instalar o swat:
sudo apt-get install -y swat
- Ativar o serviço openbsd-inetd:
service openbsd-inetd start
- Modifique a senha de root:
echo root:nova_senha | chpasswd
- Acessar a seguinte URL (use a senha de root):
http://192.168.2.X:901/
Atividade
- Instale o Samba em sua máquina virtual.
- Configure seu Samba para que use nome de servidor servidorX, sendo X o número de seu computador. O domínio (opção workgroup) deve ser GER.
- Crie contas de usuários samba, usando esse comando: ...sendo usuario um usuario do Linux.
smbpasswd -a usuario
- Ative o Samba:
sudo service restart
- Teste o acesso a seus compartilhamentos. Você pode usar esse comando:
# Para listar os compartilhamentos de seu servidor smbclient -L servidor X # Para acessar um compartilhamento smbclient ''\\servidorX\nome_compartilhamento'' -U usuario
- Monte um compartilhamento em sua árvore de diretórios. Para isso, use o tipo de sistema de arquivos cifs no comando mount:
mount -t cifs -o username=usuario,password=senha '\\servidorX\nome_compartilhamento' /ponto/de/montagem
07/06: Servidor Samba como controlador de domínio (PDC)
Um controlador de domínio Windows (PDC - Primary Domain Controller) é capaz de autenticar logons no dominio. Isso implica autenticar tanto o usuário quanto o computador onde ele tenta se logar. Ao final do logon, podem ser executados scripts netlogon no computador cliente, e ser carregado o perfil do usuário (profile).
O Samba é capaz de se tornar um PDC, o que implica ativar diversas opções de configuração e a execução de algumas tarefas administrativas. O Samba operando dessa forma possibilita autenticar logons provenientes tanto de estações Windows quanto Unix. Com isto, se obtém a integração de contas de usuários, serviços de autenticação e de arquivos e impressoras entre essas duas famílias de sistemas operacionais. O resultado é um ambiente de trabalho em rede com aparente homogeneidade, em que usuários podem usar tanto estações Windows quanto Unix.
Um breve tutorial (baseado nesse guia) para ativar um PDC com samba segue abaixo:
- Adicione as seguintes opções a /etc/samba/smb.conf:
workgroup = GERX security = user domain logons = yes logon path = \\%N\%U\profile logon drive = H: logon home = \\%N\%U logon script = logon.cmd add machine script = sudo /usr/sbin/useradd -n -g machines -c Machine -d /var/lib/samba -s /bin/false %u - Adicione o compartilhamento [netlogon] a /etc/samba/smb.conf:
[netlogon] comment = Network Logon Service path = /srv/samba/netlogon guest ok = yes read only = yes share modes = no
- Crie o diretório /home/samba/netlogon, com um arquivo logon.cmd vazio:
sudo mkdir -p /home/samba/netlogon sudo touch /home/samba/netlogon/logon.cmd
- Crie o grupo sysadmin, e mapeie-o para o grupo Windows Domain Admins:
groupadd sysadmin sudo net groupmap add ntgroup="Domain Admins" unixgroup=sysadmin rid=512 type=d
- Crie um usuário que será o operador Samba, responsável por operações administrativas:
useradd -g sysadmin -G admin -c "Operador samba" -m smbadmin - Reinicie o Samba:
sudo service samba restart
Após esses passos, será possível adicionar máquinas ao domínio Windows mantido pelo Samba. Cada máquina deverá, no entanto, possuir previamente uma conta Linux com nome nome_da_maquina$:
- Criar a conta de máquina (obs: assume-se que exista um grupo maquinas):
useradd -c "Nome do computador" -g maquinas nome_da_maquina$ smbpasswd -am nome_da_maquina
Para tornar um computador como membro de domínio, deve-se criar sua conta de máquina e uni-lo ao domínio. Se for feito com Samba, devem-se seguir esses passos:
- Adicionar essas opções a /etc/samba/smb.conf:
workgroup = GERX netbios name = nome_da_maquina domain logons = no security = domain password server = * wins server = IP_do_PDC
- Reativar o Samba:
service samba restart
- Adicionar o computador ao domínio:
net join GERX
Integrando Samba e LDAP
Muitas das informações necessárias pelo Samba, como contas de usuários e grupos, além de informações sobre o domínio Windows, podem ser armazenadas em uma base LDAP. Isso abre a possibilidade de haver mais de um servidor Samba como controlador de domínio. Em tal cenário, um dos servidores Samba é o PDC (Primary Domain Controller) e os demais são BDC (Backup Domain Controller). Assim, caso o PDC fique inoperante, os BDC podem continuar autenticando logons, evitando que o domínio fique fora do ar.
A integração do Samba com LDAP implica ter primeiro um servidor LDAP devidamente configurado. Os passos abaixo, baseados em um tutorial da comunidade Ubuntu, criam uma configuração básica do Samba com LDAP:
- Devem-se instalar os seguintes pacotes:
sudo apt-get install samba-doc smbldap-tools
- Copie o schema LDAp do Samba:
sudo cp /usr/share/doc/samba-doc/examples/LDAP/samba.schema.gz /etc/ldap/schema/ sudo gunzip /etc/ldap/schema/samba.schema.gz
- Adicione a seguinte linha a /etc/ldap/slapd.conf:
include /etc/ldap/schema/samba.schema
- Adicione essas outras linhas a /etc/ldap/slapd.conf, logo após a lista de índices:
index sambaSID eq index sambaPrimaryGroupSID eq index sambaSIDList eq index sambaDomainName eq
- Reinicie o slapd:
service slapd restart
- Adicione essas linhas a /etc/samba/smb.conf:
passdb backend = ldapsam:ldap://localhost ldap suffix = dc=redeX,dc=ger,dc=ifsc ldap user suffix = ou=Users ldap group suffix = ou=Groups ldap machine suffix = ou=Computers ldap idmap suffix = ou=Idmap ldap admin dn = cn=admin,dc=redeX,dc=ger,dc=ifsc ldap passwd sync = yes ldap ssl = off add machine script = sudo /usr/sbin/smbldap-useradd -t 0 -w "%u"
- Configure no Samba a senha de acesso ao LDAP:
smbpasswd -w senha_do_ldap
- Reinicie o Samba:
service samba restart
- (opcional) Configure o smbldap-tools (utilitários para auxiliar a criação de contas e grupos na base LDAP pro Samba):
sudo gunzip /usr/share/doc/smbldap-tools/configure.pl.gz perl /usr/share/doc/smbldap-tools/configure.pl
Atividades
- Converta seu servidor Samba em um PDC para o domínio GERX, sendo X o número de seu computador.
- Configure a outra máquina virtual como membro do domínio GERX. Para isso você deve nela ativar a opção security = domain.
- Integre seu servidor Samba ao LDAP. Teste o acesso a compartilhamentos com os usuários existentes na base LDAP.
10/06: não houve aula
... devido ao Workshop do IFSC na Fiesc.
14/06: Servidor proxy e cache web
Ver capítulo 34 da apostila.
Um servidor proxy (procurador ou intermediário, em inglês) é um serviço que intermedia o acesso entre clientes e servidores de uma aplicação. Sendo assim, cada diferente aplicação precisa de um proxy específico. Existem proxies para aplicações como HTTP, FTP, SIP, POP3, DNS e outros. Alguns motivos para o uso de um proxy seguem abaixo:
- Manter os clientes anônimos, por razões de segurança
- Acelerar o acesso a recursos (usando cache). Por exemplo, proxies web são comumente usados para armazenar páginas web em cache.
- Policiar o acesso a serviços de rede ou conteúdo
- Registrar ou auditar o acesso a serviços de rede
- Contornar controles de segurança (i.e. burlar os controles definidos no ítem 3)
- Investigar o conteúdo recebido em busca de código malicioso
- Investigar conteúdo transmitido, para evitar envio de dados sigilosos
Proxy e cache web
Um proxy web possui duas principais tarefas:
- Cache: fazer cache de páginas localmente, para acelerar o acesso a essas páginas quando outros clientes as requisitarem, e para poupar o uso do link para Internet.
- Controle de acesso: aplicar controles de acessos a páginas, restringindo o acesso de acordo com o endereço da página, o cliente (computador) ou usuário que faz o acesso, o horário de acesso, e possivelmente outras restrições.
Além dessas, outras tarefas importantes são:
- Autenticação: identificar os usuário que acessam páginas
- Log: registrar os acesso feitos pelos usuários, para possibilitar auditorias
Alguns proxies web conhecidos são:
Cache web
Um servidor proxy web pode funcionar como uma espécie de "cache comunitário", onde toda página que um usuário visualizar ficará armazenada e quando outro (ou o mesmo) usuário requisitar a mesma página, ela não será trazida da Internet novamente, simplesmente será lida do disco e entregue, economizando o uso do link Internet. Porém se a página tiver sido modificada na origem, será trazida da Internet novamente. A figura abaixo ilustra o funcionamento da cache web.

Controle de acesso
O controle de acesso pode ser feito com ACL (Access Control List), que restringem ou permitem acessos de acordo com características previamente definidas. Por exemplo, uma ACL pode ser definida para casar com:
- O computador de onde se origina o acesso
- O usuário que faz o acesso
- A URL acessada
- O endereço do servidor onde reside a página procurada
- O horário do acesso
- A quantidade de acessos simultâneos feitos pelo cliente ou usuário
- ... e possivelmente outros, incluindo combinações desses
Squid
Squid é um proxy web largamente usado e com muitas funcionalidades. Todas as características de proxies citadas anteriormente estão implementadas com grande flexibilidade, e há grande ênfase em desempenho (aceleração do acesso a páginas e uso dos recursos do comutador onde reside o proxy).
Para instalar o squid no Ubuntu:
sudo apt-get install -y squid
O principal arquivo de configuração é /etc/squid/squid.conf. As principais diretivas deste arquivo são:
http_port 3128 # Porta à qual o squid atenderá
cache_dir ufs /var/spool/squid 100 16 256 # Diretório de cache do tipo ufs, com armazenamento em /var/spool/squid, tamanho total de 100 MB, com 16 subdiretórios e cada um deles com 256 subdiretórios. Obs.: recomenda-se aumentar o tamanho total e mais nenhum outro parâmetro.
cache_mem 8 MB # Tamanho da cache em RAM. Dependendo do uso da máquina, ocupe metade da RAM total.
maximum_object_size 4096 KB # Tamanho máximo de um único objeto. Recomenda-se 16384 (16 MB). Isto é interessante quando faz-se downloads de arquivos.
visible_hostname mX.redesX.edu.br # Nome real do servidor.
Se mudar alguma diretiva lembre-se de reiniciar o serviço:
service squid restart
As mensagens de erro que o squid envia aos usuários (por exemplo que determinado sítio tem acesso proibido) podem ser personalizadas. Existem várias possíveis mensagens de erro para diferentes idiomas, as quais podem ser encontradas no diretório /usr/share/squid/errors.
ACLs no Squid
O controle de acesso no Squid se faz com a combinação de ACLs e diretivas para liberação ou rejeição de acesso. Assim, uma ACL apenas classifica acessos com uma determinada característica comum, e o bloqueio ou liberação se faz a diretiva http_access:
# ACL para identificar acessos vindos de uma determinada subrede
acl minha_rede src 192.168.2.0/24
# Libera os acessos vindos de minha subrede, e rejeita todos os demais acessos
http_access allow minha_rede
http_access deny all
De forma geral, uma ACL é definida da seguinte forma:
acl nome_da_acl tipo_da_acl valor_da_ACL [outro_valor ...]
Se houver mais de um valor feito um OU lógico entre eles (i.e. ao menos um deles deve ser satisfeito). Quando há muitos valores pode ser mais prático colocá-los em um arquivo:
acl nome_da_acl tipo_da_acl "/caminho/do/arquivo_de_valores"
A restrição a ser aplicada com http_access pode incluir uma ou mais ACLS:
http_access allow minha_rede http_access allow minha_rede expediente
Quando mais de uma ACL for indicada, será feito um E lógico entre elas (i.e. todas devem ser satisfeitas).
Alguns tipos de ACL seguem abaixo:
| ACL | Característica do acesso | Exemplo |
|---|---|---|
| src | Endereço IP de origem | acl minha_rede src 192.168.2.0/24 127.0.0.1 |
| dst | Endereço IP de destino | acl rede_ifsc dst 200.135.37.64/26 |
| arp | Endereço MAC do cliente | acl micros arp 00:27:0e:06:2e:95 |
| srcdomain | Domínio DNS do cliente | acl rede1 srcdomain .ger.edu.br |
| dstdomain | Domínio DNS do servidor destino (está na URL) | acl ifsc dstdomain .ifsc.edu.br |
| srcdom_regex | Expressão regular aplicada ao domínio DNS de origem | acl rede1 srcdom_regex \.rede[0-9]+\.ger\.edu\.br |
| dstdom_regex | Expressão regular aplicada ao domínio DNS de destino | acl ifsc dstdom_regex (ifsc|cefetsc)\.edu\.br |
| time | Horário do acesso | acl expediente time MTWHF 8:0-18:0 |
| url_regex | Expressão regular aplicada à URL | acl copa url_regex .*copa.* |
| urlpath_regex | Expressão regular aplicada somente à URI | acl pics urlpath_regex -i (gif|jpg|png|pnm) |
| port | Port contido na URL | acl ports_padrao port 80 443 |
| proto | Protocolo da URL | acl ftp proto FTP |
| method | Método HTTP do acesso | acl leitura method GET HEAD |
| proxy_auth | Usuário autenticado | acl meus_usuarios proxy_auth REQUIRED |
| maxconn | Máximo número de conexões vidas do mesmo IP | acl conexoes maxconn 8 |
| max_user_ip | Máximo número de IPs de onde um mesmo usuário pode se logar | acl restrito max_user_ip 1 |
| rep_mime_type | Tipo de conteúdo da resposta | acl video rep_mime_type video/mpeg video/mp4 |
Atividades
- Instale o Squid em uma máquina virtual
- Configure o squid para usar uma cache de 64 MB, e permitir qualquer tipo de acesso. Teste-o com seu navegador.
- Acesse um site bastante carregado (ex: UOL, Terra, ou outro de sua preferência). Em seguida peça que um colega use o seu proxy, e o use para acessar esse mesmo site. Compare a velocidade do acesso com e sem o proxy.
- Configure o controle de acesso no Squid para permitir apenas que seu computador o utilize. Em seguida peça a um colega que tene usá-lo.
- Crie regras de controle de acessos para bloquear:
- Acessos a sites de notícias mais populares
- Acesso a serviços de webmail externos
- Acesso a sites com URLs com palavras-chaves futebol, copa, bola, pele, dunga
- Essas restrições se aplicam somente ao horário de expediente: 2a a 6a feira, das 8 às 12h, e das 14 às 18h.
- Configure a autenticação de usuários no Squid, que deve aproveitar o servidor IMAP já existente.
- Pesquise sobre essas funcionalidades do Squid:
- Controle de banda (ex: forçar que downloads longos sejam limitados a determinada taxa de bytes por segundo) ... ver diretiva delay_pool.
- Hierarquias de caches (uso de vários servidores proxy para cache) ... ver diretivsa cache_peer.
17/06: Administração com Webmin
Em uma rede real costumam-se usar ferramentas de auxílio à administração dos equipamentos e serviços de rede. Dependendo da sofisticação da ferramenta, é possível tornar rara a necessidade de editar arquivos de configuração dos softwares e do próprio sistema operacional. Assim, pode-se concentrar em administrar de fato os serviços num nível mais elevado.
Dentre diversas ferramentas existentes, webmin se destaca pela longevidade, contínuo aperfeiçoamento, simplicidade e grande quantidade de tarefas administrativas suportadas. Praticamente todo sistema operacional variante do Unix possui uma versão do webmin sob medida (ex: Linux, FreeBSD, Solaris, AIX, OpenBSD). Essa ferramenta iniciou como um projeto de código aberto e gratuito, mantendo até hoje esse status porém com versões especializadas pagas.
- Veja esse artigo de 2001 sobre o webmin
- Há também um artigo na Wikipedia
Outras ferramentas similares para administração de sistema e rede:
Instalando o webmin no Ubuntu
- Execute esses pacotes, que são requisitos:
aluno@m66:~$ sudo apt-get install -y libapt-pkg-perl libauthen-pam-perl aluno@m66:~$ sudo apt-get install -y libio-pty-perl apt-show-versions aluno@m66:~$ sudo apt-get install -y libnet-ssleay-perl
- Faça o download do webmin, e instale-o em seguida:
aluno@m66:~$ wget http://www.sj.ifsc.edu.br/~msobral/GER/webmin_1.510-2_all.deb aluno@m66:~$ sudo dpkg -i webmin_1.510-2_all.deb Desempacotando webmin (de webmin_1.510-2_all.deb) ... Configurando webmin (1.510-2) ... Webmin install complete. You can now login to https://localhost:10000/ as root with your root password, or as any user who can use sudo to run commands as root. aluno@m66:~$
- Acesse a URL https://192.168.2.X:10000/, e logue como "aluno". Deverá aparecer uma tela como a seguir:
Á esquerda estão os módulos do Webmin classificados de acordo com categorias de administração. Experimente navegar por esses menus e conferir que módulos estão disponíveis.

Atividades
- Use o webmin para:
- Ver a ocupação dos discos do servidor
- Ativar e desativar serviços a serem executados na inicialização (boot)
- Criar usuários e grupos
- Instalar e remover software
- Executar comandos no servidor
- Todos os serviços de rede vistos até o momento podem ser administrados com webmin. Investigue os seguintes módulos:
- BIND DNS Server
- DHCP Server
- Apache Web Server
- Postfix Mail Server
- Dovecot IMAP/POP3 Server
- LDAP Server
- LDAP Client
- LDAP Users and Groups
- Samba Windows File Sharing
- Squid Proxy Server
- O webmin possibilita a delegação de tarefas. Assim, podem-se criar usuários que terão o poder de executar somente algumas tarefas administrativas previamente definidas. Crie um usuário operador, e faça com que ele possa apenas criar usuários e grupos.
21/06: SNMP
- Ver capítulo 39 da apostila.
- Artigo na Wikipedia sobre SNMP
- Tutorial sobre gerência de redes
- Ver RFCs relacionadas:
Gerência de Redes SNMP
Obs: Partes do texto foram extraídos do tutorial da Teleco.
A gerência de redes, numa definição mais ampla diz respeito ao controle e acompanhamento dos recursos de rede. Para tornar mais claro do que se trata gerenciar uma rede, foram definidas cinco áreas funcionais da gerência (de acordo com o modelo de gerência OSI):
- Gerência de Configuração: Manter atualizadas as informações de hardware e software de uma rede, incluindo as informações de configurações de todos os equipamentos.
- Gerência de Falhas: Monitorar os estados dos recursos verificando em qual ponto da rede e quando uma falha ou um erro pode ocorrer
- Gerência de Contabilidade: Contabilizar e verificar de limites de utilização de recursos da rede.
- Gerência de Desempenho: Quantificar, medir, informar, analisar e controlar o desempenho de diferentes componentes da rede
- Gerência de Segurança: Proteger os elementos da rede, monitorando e detectando violações da política de segurança estabelecida.

O modelo SNMP (Simple Network Management Protocol) foi o primeiro modelo não proprietário desenvolvido pelo IETF (Internet Engineering Task Force), apresentando facilidade de implementação e possibilitando o gerenciamento de sistemas heterogêneos. Consiste em um esquema centralizado de gerência baseado num modelo Agente/Gerente, utilizando o protocolo de gerenciamento SNMP.
Desde o lançamento da primeira versão, na década de 80, o SNMP mantém-se como um protocolo simples de gerenciamento e é amplamente utilizado no gerenciamento de sistemas na Internet. Por isso, esse modelo também é denominado de Modelo da Internet de Gerenciamento.
O modelo SNMP, e a maior parte dos sistemas de gerenciamento disponíveis, se baseia no modelo Agente/Gerente, que normalmente é formado pelos seguintes elementos:
- Agente: Programa executado nos elementos de rede a serem gerenciados. Tem como função responder as solicitações vindas do Gerente e gerar mensagens a cada alteração de status de um determinado objeto;
- Gerente: Programa executado em um elemento de rede que realiza a interface entre o usuário final é o sistema de gerenciamento, ou seja, realiza a conversão das solicitações do usuário em ações que serão executadas na rede;
- Protocolo de Gerenciamento: Protocolo que normaliza a troca de informações entre um gerente e um agente. É o elemento principal de uma rede de gerenciamento. Esta troca de informações pode acontecer de duas formas: Interações comando/resposta do Gerente para o Agente (o Gerente faz uma solicitação e o Agente responde) e apenas envio de informações do Agente para o Gerente sem a solicitação prévia (também conhecido como mensagens do tipo TRAP);
- MIB (Management Information Base): Por último, a MIB é uma base de dados localizada no Agente que contém as informações e a estrutura dos objetos que podem ser gerenciados pelo Gerente. Esses objetos a serem gerenciados podem ser, por exemplo, uma interface serial ou uma fonte em um roteador.
Há dois tipos de dispositivos no modelo SNMP:
- Nodo gerenciado: equipamento na rede que possui o software necessário para ser gerenciado (o agente).
- Estação de gerenciamento de rede (NMS - Network Management Station): um equipamento que possui o software para gerenciar os nodos gerenciados (o gerente).
Note que esse modelo trata da execução de operações de gerência sobre os nodos gerenciados, que são equipamentos que desempenham alguma função de comunicação na rede, tal como um roteador, switch, servidor, ou um simples computador desktop. Do ponto de vista da gerência de redes, cada nodo gerenciado se constitui de um conjunto de objetos passíveis de serem gerenciados, os quais descrevem atributos de componentes do nodo gerenciado. Por exemplo, objetos relacionados com uma interface de rede podem ser sua descrição, endereço, contadores de pacotes lidos e enviados, contadores de erros de recepção e transmissão, entre outros. As operações de gerência, portanto, são traduzidas para leituras ou modificações dos valores desses objetos.
A figura abaixo ilustra a arquitetura SNMP, mostrando como seus componentes se relacionam:

O protocolo SNMP
O protocolo SNMP transmite as informações das operações de gerência entre gerente e agentes. Ele usa o protocolo UDP, com port padrão 161. Há quatro comandos básicos (SNMPv1) que operam em modo comando-resposta (com exceção de TRAP):
- GET: lê um ou mais valores de atributos de um objeto em um elemento de rede. Implementado com as PDUs GetRequest e GetResponse.
- SET: modifica um ou mais valores de atributos de um objeto em um elemento de rede. Implementado com as PDUs SetRequest e SetResponse.
- GET-NEXT: lê iterativamente um ou mais valores de atributos de um objeto em um elemento de rede. Implementado com as PDUs GetNextRequest e GetResponse.
- TRAP: notifica o gerente sobre a modificação de um atributo vigiado. Implementado com a PDU Trap.

Formato de uma mensagem SNMP genérica
| Campo | Sintaxe | Formato | Descrição |
|---|---|---|---|
| Versão | Inteiro | 4 | Número da versão SNMP dessa mensagem; usado para certificar a compatibilidade entre versões. Para SNMPv1, esse valor é na verdade 0 (e não 1) |
| Comunidade | Octet string | Variável | Identifica a comunidade SNMP em que o transmissor e receptor dessa mensagem estãop localizados. Isso é usado para implementar o mecanismo simples de segurança baseado em comunidade do SNMP. |
| PDU | - | Variável | A PDU contida na mensagem |
As PDUs SNMP (campo PDU da mensagem genérica) possuem o seguinte formato:

| Campo | Sintaxe | Formato | Descrição |
|---|---|---|---|
| PDU Type | Inteiro | 4 | 0: GetRequest 1: GetNextRequest 2: GetResponse 3: SetRequest |
| RequestID | Inteiro | 4 | Um número usado para casar pedidos com suas respostas |
| Error Status | Inteiro | 4 | Usado por PDUs GetResponse para informar o status da resposta |
| Error Index | Inteiro | 4 | Quando Error Status não for zero, indica qual objeto gerou o erro |
| Variable Bindings | Variável | Variável | Um conjunto de pares nome-valor identificando os objetos da MIB na PDU |
- Maiores detalhes sobre PDUs SNMP:
Nomenclatura de objetos na MIB
Todos os objetos acessados pelo SNMP devem ter nomes únicos definidos e atribuídos. Além disso, o Gerente e o Agente devem concordar sobre os nomes e significados das operações GET e SET. O conjunto de todos os objetos SNMP é coletivamente conhecido como MIB (do inglês: Management Information Base). O padrão SNMP não define o MIB, mas apenas o formato e o tipo de codificação das mensagens. A especificação das variáveis MIB, assim como o significado das operações GET e SET em cada variável, são especificados por RFCs próprios.
Cada variável em uma MIB se chama objeto da MIB, e é definida usando a linguagem de descrição de dados SMI. Um dispositivo de rede pode ter muitos objetos, que correspondem aos diferentes elementos de hardware e software nele contidos. Para possibilitar que novos objetos de MIB sejam facilmente definidos, grupos de objetos de MIB relacionados estão definidos em RFCs separadas chamados de módulos MIB.

Resumo da hierarquia da MIB
Um objeto ou ramo da MIB é identificado por seu caminho desde a raiz (chamado de OID: Object Identifier), com uma notação parecida com um caminho de um arquivo em um diretório:
.iso.org.dod.internet.mgmt.mib-2.application
Na verdade, um OID se constitui de uma sequência de números que identificam o caminho na MIB. Os nomes são apenas uma forma de torná-los mais facilmente compreensíveis por um ser humano. Assim, o OID acima em notação numérica é:
.1.3.6.1.2.1.27.1.1.8.2
Usualmente, caso o OID não inicie com um ponto assume-se que ele esteja abaixo de .iso.org.dod.internet.mgmt.mib. (1.3.6.1.2.1). Assim, o OID a seguir:
system.syslocation.0
... corresponde na verdade ao OID:
.iso.org.dod.internet.mgmt.mib.system.syslocation.0
Software net-snmp
O projeto net-snmp provê uma implementação de um agente SNMP e de utilitários para fazer operações sobre MIBs (assim, fornece também a base para a implementação de um gerente). Para instalá-lo deve-se executar:
sudo apt-get install -y snmp snmpd
Esses pacotes contêm os seguintes programas:
- snmpd: o agente SNMP
- snmpwalk: navegação por uma MIB (modo texto)
- snmpget: lê valores de OID de uma MIB
- snmpset: modifica valores de um OID em uma MIB
- ... e outros mais específicos (ver a documentação)
Para configurar o agente SNMP, pode-se editar manualmente o arquivo /etc/snmp/snmpd.conf, ou executar o utilitário snmpconf.
Atividades
- Instale o net-snmp em seu servidor.
- Use o utilitário snmpwalk para mostrar os OIDs presentes por default na instalação. Use-o da seguinte forma: Experimente usá-lo também assim:
snmpwalk -v1 -c public 127.0.0.1snmpwalk -v1 -c public -Of 127.0.0.1 # ... ou assim: snmpwalk -v1 -c public -Ofn 127.0.0.1
- Configure seu agente SNMP para ativar as MIBs IP e TCP. Em seguida use novamente o snmpwalk para visualizr os OIDs.
- Usando o utilitário snmpset modifique o valor do OID system.sysContact.0 (corresponde ao nome do técnico responsável pelo nodo gerenciado).
24/06: Monitoramento com Cacti
Como visto na aula anterior, SNMP é um protocolo de gerência de redes que tem o propósito de ler e modificar valores de objetos gerenciados (variáveis na MIB). Assim, esse protocolo, e o modelo de gerência de redes de que faz parte, não fazem grande coisa além de possibilitar acessar esses valores. Sua utilidade reside em sua aplicação em sistemas de gerência de redes (NMS - Network Management Systems) e aplicações que coletam dados para fins de monitoramento. Dentre os coletores de dados existentes, um que se destaca é o Cacti.
O cacti é um coletor de dados e gerador automático de gráficos para fins de monitoramento e histórico de desempenho. Os dados devem ser numéricos, para possibilitar a geração de gráficos. Uma interface web possibilita a administração e visualização dos gráficos, como se pode ver abaixo:


No cacti os dados são coletados, em seguida armazenados numa base de dados especial (RRD), e finalmente apresentados em gráficos quando solicitado. Para cumprir essas tarefas, os seguintes elementos são definidos (nesta ordem):
- Dispositivos (Devices): equipamentos de onde se coletarão os dados. Cada equipamento pode ter uma ou mais fontes de dados (Data Source).
- Fontes de Dados (Data Sources): os atributos ou variáveis de um dispositivo cujos valores serão coletados. A coleta pode ser feita por diferentes mecanismos, como SNMP e execução de programas ou scripts.
- Gráficos (Graphs): os gráficos a serem gerados a partir de cada fonte de dados. Diferentes gráficos podem ser definidos para uma mesma fonte de dados, dependendo do que se deseja mostrar (valores médios ou máximos, por exemplo).
Muitos exemplos e tipos de dispositivos ou fontes de dados estão predefinidos no Cacti. Por exemplo, existem todas as definições para obter estatísticas de interfaces de rede usando SNMP. Como o cacti é muito flexível, podem-se criar novos tipos de fontes de dados, bastando definir como os dados devem ser coletados.
Instalando o cacti
No Ubuntu a instalação se mostra muito simplificada, pois o sistema de pacotes já configura todos os detalhes do cacti após a instalação. Se for instalado a partir do código fonte serão necessárias a configuração do banco de dados MySQL (para guardar informações administrativas. como definições de dispositivos, fontes de dados e gráficos) e a instalação de algumas extensões PHP.
- Instale o cacti:
sudo apt-get install -y cacti
- Serão apresentadas telas com questões sobre a configuração do Cacti:
- Selecione Sim para Configurar a base de dados para cacti com dbconfig-common?
- Forneça a senha do administrador do MySQL (ela deve ter sido definida quando da instalação do banco de dados)
- Forneça uma senha que será usada pelo usuário do cacti no banco de dados. Essa será a senha do cacti (não deve ser a do administrador).
- Selecione o uso do Apache.
- Ao final da instalação, edite o arquivo /etc/apache2/sites-enabled/000-default, e a ele adicione esta linha:
Include /etc/cacti/apache.conf
- Reinicie o Apache:
sudo service apache2 restart
- Com um navegador acesse a URL http://192.168.1.X/cacti. Ali você deve dar continuidade ao processo de instalação:
- Selecione "New Install"
- Verifique na próxima tela se todas as opções mostradas estão corretas (se aparece OK em verde ao lado).
- Clique em Finish, e na tela a seguir forneça o usuário admin e senha admin.
Atividades
- Crie gráficos para monitorar a CPU, memória, discos, processos e usuários do servidor onde reside o Cacti.
- Visualize os gráficos cvriados.
- Crie gráficos para as interfaces de rede do servidor onde reside o gráfico, usando SNMP.
- Crie os mesmos gráficos, porém coletando os dados do gateway do laboratório (192.168.2.101) também via SNMP.
- Crie um gráfico para coletar um OID SNMP específico (ex: quantidade de conexões TCP estabelecidas).
- É possível coletar qualquer dado e graficá-lo. Portanto crie um gráfico que mostre a quantidade de acessos ao seu servidor Web, e outro gráfico para mostrar a quantidade de erros de acesso. Dicas:
- Essas informações estão nos logs do Apache, que ficam em /var/log/apache2
- As coletas dependem de um método de entrada de dados (Data Input Method); O ideal é criar um script para a coleta dos dados
- Crie primeiro um Data Input Method, em seguida um Data Template, depois um Graph Template e finalmente um New Graph.
4a avaliação: Monitoramento de uma pequena rede
Prazo de entrega e apresentação: 07/07.
Na 3a avaliação foi criado um sistema de correio eletrônico, composto por um MTA e MDA POP3/IMAP4. Para que funcionassem a contento foram necessários outros serviços de rede, como DNS. A 4a avaliação estende aquela rede para que use alguns novos serviços, e que possa ser monitorada com um NMS (Network Management System). A nova rede deve ser composta de duas máquinas virtuais: uma com a infraestrutura de correio eletrônico e demais serviços implantados na 3a avaliação, e outra com os novos serviços descritos a seguir.
Os objetivos do projeto são:
- Usar LDAP para integrar as contas de usuários e grupos no servidor de correio eletrônico e no servidor onde reside o NMS.
- Usar um agente SNMP em ambos servidores para coletas de estatísticas de interfaces de rede, uso de processador e memória.
- Usar o NMS Nagios para monitorar os servidores e todos os serviços nele implantados. O Nagios deve ser configurado para acompanhar o estado dos serviços, mas não deve enviar emails quando detectar situações de alerta.
Deve ser confeccionado um relatório que descreva a instalação dos serviços implantados, de forma que possam ser reproduzidos em outros servidores.
28/06: NMS (Network Management System): Nagios
NMS (Network Management System) é um sistema (incluindo hardware e software) onde se executam softwares para gerenciar uma rede de computadores. Um termo parecido para NMS é Network Monitoring System, que se trata de um tipo específico de software para monitorar elementos de rede e seus serviços (ex: HTTP, SMTP, LDAP, DNS).

Existem muitos sistemas de monitoramento de rede, uma vez que o acompanhamento eficiente da saúde da rede é uma tarefa fundamental da gerência. Em uma grande rede, composta de muitos servidores, equipamentos de rede e diversos serviços, a equipe responsável precisa de ferramentas de auxílio ao acompanhamento de seu bom funcionamento. Essas ferramentas devem idealmente não somente mostrar se os componentes da rede estão funcionando como esperado, mas também alertar os responsáveis quando identificar algo errado. Além disso, como existe dependência tanto entre serviços de rede quanto entre equipamentos (e entre ambos), essas ferramentas devem senão apontar a causa raiz dos problemas, ao menos localizar os prováveis candidatos. Finalmente, é desejável que esses sistemas identifiquem e mostrem tendências de eventos na rede, a partir do histórico de funcionamento de seus componentes. São portanto muitos requisitos para os NMS, os quais não são totalmente atendidos por todos os softwares existentes.
Um NMS muito usado que possibilita atender quase todos os requisitos listados acima (com exceção da análise de tendências na rede) é o Nagios. Basicamente, o Nagios é uma plataforma configurável de monitoramento de serviços e equipamentos de rede, capaz de emitir alertas e de efetuar ações de recuperação de falhas. Cada serviço ou tipo de equipamento pode ser monitorado com um plugin especializado, que assim efetua testes de disponibilidade sob medida. Por exemplo, um plugin de monitoramento do serviço HTTP (Web) pode tentar buscar uma ou mais páginas, e analisar tanto o status da resposta do servidor quanto o tempo que levou para obtê-la. A dependência entre os serviços pode ser configurada, de forma que ao se detectarem falhas por diferentes plugins, o Nagios possa apontar a causa raiz do problema.
O ponto de partida do Nagios é a descrição da rede e de todos os serviços a serem monitorados. Cada monitoramento de serviço ou equipamento precisa ser parametrizado (por exemplo, quais os atrasos de resposta aceitáveis para o roteador de um link), para que se possam identificar as situações anômalas. Essas informações residem na configuração do Nagios, e precisam ser criadas manualmente.
Outros NMS interessantes:
Instalação
- Instalar alguns softwares necessários pelo Nagios:
sudo apt-get install -y gcc libpng12-dev libjpeg62-dev wget http://www.sj.ifsc.edu.br/~msobral/GER/nagios/gd-2.0.35.tar.bz2 tar xjf gd-2.0.35.tar.bz2 cd gd-2.0.35 ./configure make make install - Fazer o seguinte download:
wget http://www.sj.ifsc.edu.br/~msobral/GER/nagios/nagios-3.2.1.tar.gz wget http://www.sj.ifsc.edu.br/~msobral/GER/nagios/nagios-plugins-1.4.14.tar.gz
- Descompacte nagios-3.2.1.tar.gz:
tar xzf nagios-3.2.1.tar.gz
- Compile e instale o Nagios:
cd nagios-3.2.1 groupadd nagios useradd -g nagios -c Nagios -d /var/lib/nagios -m nagios ./configure --with-httpd-conf=/etc/apache2/conf.d --with-temp-dir=/var/lib/nagios --with-nagios-user=nagios --with-nagios-group=nagios make all make install make install-init make install-commandmode make install-config make install-webconf
- Agora instale o nagios-plugins:
cd .. tar xzf nagios-plugins-1.4.14.tar.gz cd nagios-plugins-1.4.14 ./configure --with-nagios-user=nagios --with-nagios-group=nagios make make install
- O Nagios foi instalado dentro de /usr/local/nagios. Dentro de /usr/local/nagios/etc há vários arquivos de configuração, iniciando com nagios.cfg. Esse arquivo contém a configuração global, e a informação de que outros arquivos devem ser incluídos. As configurações específicas ficam em arquivos dentro de /usr/local/nagios/etc/objects. Cada elemento monitorado é definido por um objeto, havendo basicamente hosts (equipamentos) e services (serviços que residem nos equipamentos). Por exemplo, o arquivo localhost.cfg ali existente inicia assim:
# Define a host for the local machine define host{ use linux-server ; Name of host template to use ; This host definition will inherit all variables that are defined ; in (or inherited by) the linux-server host template definition. host_name localhost alias localhost address 127.0.0.1 } # Define an optional hostgroup for Linux machines define hostgroup{ hostgroup_name linux-servers ; The name of the hostgroup alias Linux Servers ; Long name of the group members localhost ; Comma separated list of hosts that belong to this group } # Define a service to "ping" the local machine define service{ use local-service ; Name of service template to use host_name localhost service_description PING check_command check_ping!100.0,20%!500.0,60% } # Define a service to check the disk space of the root partition # on the local machine. Warning if < 20% free, critical if # < 10% free space on partition. define service{ use local-service ; Name of service template to use host_name localhost service_description Root Partition check_command check_local_disk!20%!10%!/ } - Inicie o nagios:
service nagios start
- Crie um usuário para acesso ao Nagios (usuário somente para autenticação básica no Apache):
htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
- Acesse a interface web do Nagios pela URL http://192.168.2.X/nagios. Após autenticar o usuário nagioasdmin deve aparecer a seguinte tela:

Atividades
- Instale o Nagios na mesma máquina virtual onde está o Cacti.
- Crie uma configuração inicial para monitorar os serviços em seu servidor (SMTP, HTTP, IMAP, DNS) e o gateway da rede (192.168.2.1), e o servidor web do IFSC onde fica a Wiki (wiki.sj.ifsc.edu.br).
- Crie uma dependência entre o gateway e o servidor Wiki: para chegar à wiki é necessário que o gateway esteja ativo.
- Veja o que o Nagios reporta quando o gateway fica fora do ar (o professor irá simular isso).
- Estenda a configuração do Nagios para monitorar a conectividade da rede do IFSC. Quer dizer, ele deve monitorar a conectividade com a Internet e quando ela ficar fora do ar deve indicar se o problema está no IFSC ou se é externo.
- Configure o envio de alertas para a queda do serviço de email ou web. Esses alertas devem ser enviados por email para o administrador da rede (ou por SMS).
- Crie um monitoramento de serviço para monitorar a quantidade de conexões TCP estabelecidas no seu servidor. Dica: esa informação pode ser obtidfa facilmente com SNMP, como visto na aula sobre o Cacti.
- Crie outro monitoramento de serviço para a quantidade de conexões estabelecidas com o servidor web (port TCP 80).
- Integre o Cacti ao Nagios, de forma que se associem os gráficos gerados pelo Cacti aos equipamentos monitorados pelo Nagios.